Topic 7:基本块与 Traces¶
约 3276 个字 12 张图片 预计阅读时间 11 分钟
Outline
简单来说,IR Tree 代码和机器指令之间存在着一定意义上的不匹配,比如 CJUMP 可以转移到两个标号之间的任何一个,而真正的机器语言中的转移指令在为假的时候直接 Fall Through;并且由于存在副作用的原因, ESEQ 和 CALL 的子树的执行顺序很重要;嵌套的 CALL 节点也会引起寄存器干扰。
因此我们使用一个三阶段的规范化转换:线性化/Linearization 形成没有 SEQ 节点和 ESEQ 节点的规范树;基本块划分/Basic Block Partitioning 形成没有内部跳转和标签的基本块;迹调度/Trace Scheduling 对基本块进行排序,使得每一个 CJUMP 之后都紧跟其 false 标号。
1. 规范形式¶
语义分析的阶段生成的中间语法树必须转换成汇编语言或者机器语言,中间代码树语言虽然都经过了仔细的选择,产生了最适合大多数机器的操作符,但是仍然存在一些问题:
- 比如一些操作符不能直接和机器语言的指令完全对应;
- 存在中间代码树语言和编译优化分析相冲突的情况。
比如 CJUMP 可以转移到两个标号之间的任何一个,而真正的机器语言中的转移指令在为假的时候下降到下一条指令;表达式内的 ESEQ 节点也不太方便,因为 ESEQ 节点在计算语句 s 的时候可能会产生副作用,因此会导致计算表达式的时候先做什么后做什么结果不一样:

除此之外,当试图将参数传入固定的形式参数寄存器的时候,在一个 CALL 节点的参数表达式中使用另一个 CALL 节点会产生问题,比如对于 CALL(f, [e1, CALL(g, [e2, ...]) 来讲:
- 一是寄存器使用冲突:参数
e1的值应该放进第一个参数寄存器中,第二个函数的返回值应该放进返回值寄存器中,但是很有可能在某些调用约定中,第一个参数寄存器和返回值寄存器是同一个寄存器; - 二是语句副作用问题:
CALL(g, [e2, ...])除了返回值之外,还可能修改全局变量,改变对内存,如果e1依赖于这些可能被g修改的状态,那么e1的值就可能在调用前后不同。
典范形式的特征如下:所有语句都在同一个级别,一个函数仅仅是所有语句的一个序列而已,所有的 SEQ 的父节点都是另一个 SEQ 节点或者其没有父节点。这就允许我们完全将 SEQ 节点删除,创建一个仅仅包含语句的列表,这就很汇编语言很相似了。
IR 树的典范化分三部分:
- 线性化/Linearize:将中间表示树转化成一系列规范树,其没有
SEQ节点和ESEQ节点; - 基本块/Basic Block:将这一列树分组合成没有
LABEL和JUMP语句的基本块集合; - Trace Schedule:对基本块排序并且形成一组轨迹/Trace,轨迹中每一个
CJUMP之后都直接跟随它的false标号。这是因为机器码在条件为false的时候可以完全顺着执行下去,只有条件为真的时候才需要跳转到远处。
规范树/Canonical Tree 有下面性质:没有 SEQ 节点和 ESEQ 节点,CALL 节点的父节点要么是 EXP 节点,要么就是 MOVE(TEMP t, ...)。
2. 转化成规范树¶
为了执行 IR 树到规范树的转化,我们分三步完成:
- 第一步:消除所有
ESEQ节点; - 第二步:将所有
CALL节点移到顶层; - 第三步:消除所有
SEQ节点。
2.1 消除 ESEQ 节点¶
检查 ESEQ 出现在表达式内的形式,重写规则使得将 ESEQ 可以推到更高一层;最后将 ESEQ 节点转化到 SEQ 节点。
转化规则基本如下:
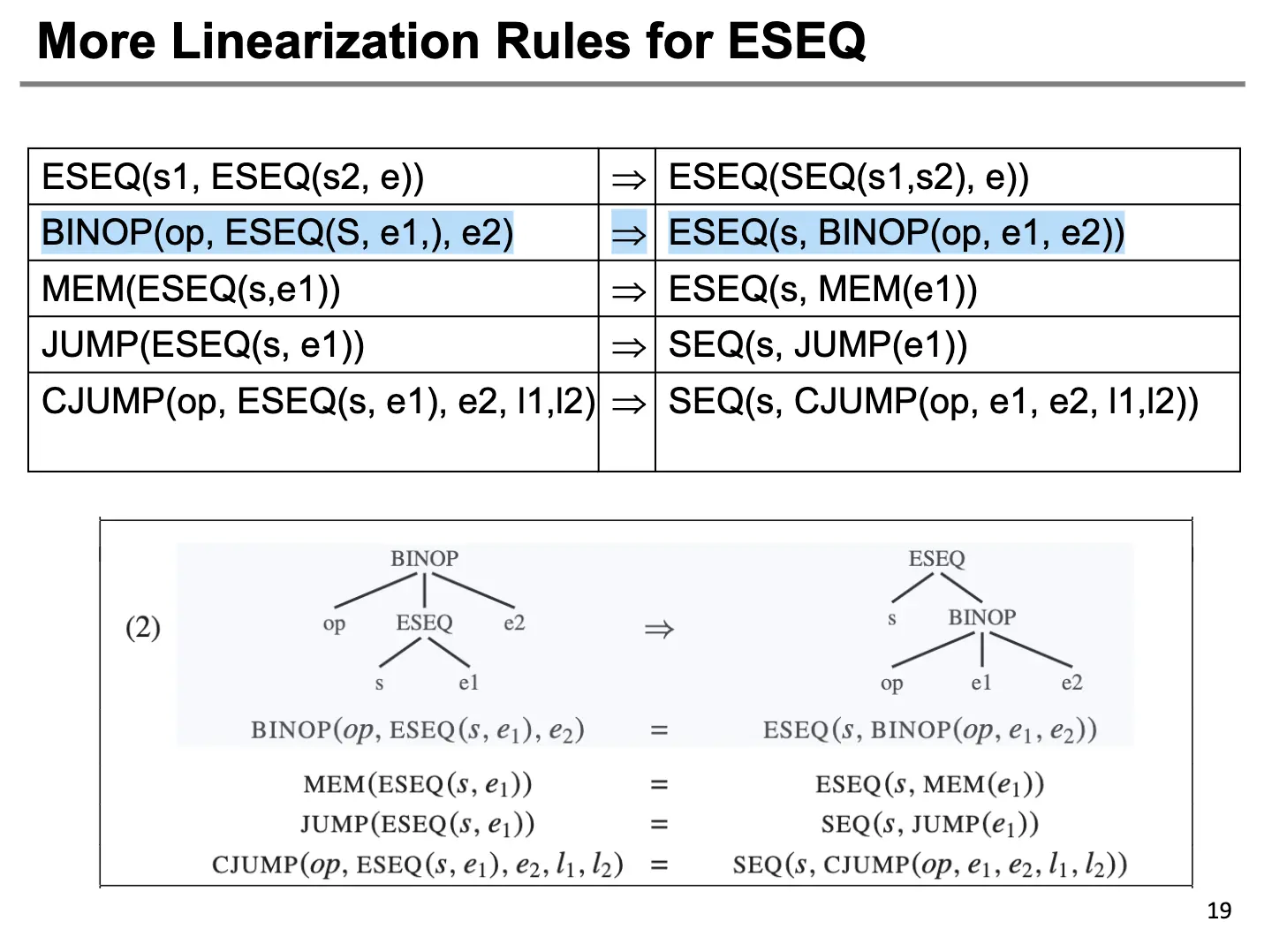
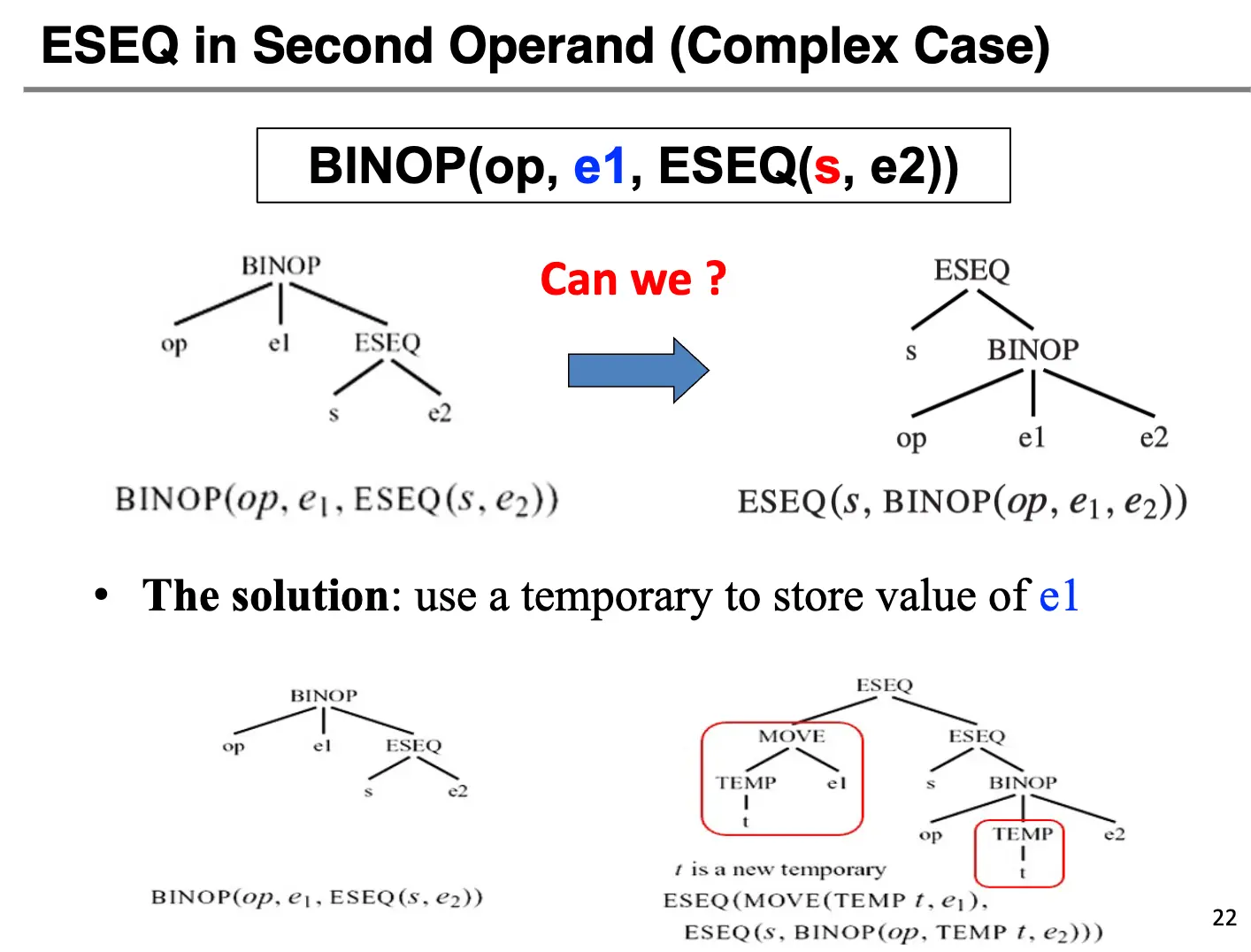
但是对于一些复杂的表达式,比如 BINOP(op, e1, ESEQ(s, e2)),我们就不能简单的转换成 ESEQ(s, BINOP(op, e1, e2)),因为 s 可能有副作用,影响 e1 的值。解决方法是使用临时值保存 e1 的值,然后使用这个临时值替换 e1 的位置,也就是转换成 ESEQ(MOVE(TEMP t, e1), ESEQ(s, BINOP(op, TEMP t, e2)))。
对于 s 会不会影响 e1 的值这个属性,我们将其命名为可交换性/Commutativity。考虑 MOVE(MEM(t1), e) 和 MEM(t2),如果 t1 != t2,那么这两个表达式就是可以交换的,否则就是不可以交换的。
这样看来,如果 s 和 e1 是可交换的,那么 BINOP(op, e1, ESEQ(s, e2)) 就可以转换成 ESEQ(s, BINOP(op, e1, e2)),否则就使用临时值进行替换。同样可以处理 CJUMP(op e1, ESEQ(s, e2), l1, l2) 节点:如果 s 和 e1 是可交换的,那么就可以转换成 SEQ(s, CJUMP(op, e1, e2, l1, l2)),否则就使用临时值进行替换,转换成 SEQ(MOVE(TEMP t, e1), CJUMP(op, TEMP t, e2, l1, l2))。
如果可以判断表达式和语句是可以交换的,我们就可以最大限度地避免临时变量的使用,进而使得代码简洁。但是静态判别可交换性是困难的,不过我们只需要进行保守近似/Conservative Approximation 就可以,当表达式和语句确确实实在我们的保守策略下一定可以交换的话,那么其一定可以交换,否则我们保守地认为他们互相有可能影响/不可交换。一种简单/朴素的策略是:
- 常量和所有语句都可交换;
- 一个空语句和所有语句都可以交换;
- 其他情况均假定为不可交换。
下面这部分关于可交换的内容不需要掌握:对于 BINOP 和 MOVE 这类操作,其处理规则在于是否可以安全交换一个表达式 e 和一个语句 s,安全交换的前提是语句不能改变表达式的值,下面是两种不能交换的条件:
- 语句可能改变一个被表达式
e使用的临时变量的值; - 语句可能改变一个被表达式
e使用的内存位置的值。
问题又来了,如何判断这两个条件?
- 检查语句是否更新表达式使用的临时变量是容易的,因为临时变量都有一个独特的名字,编译器可以简单的检查语句的目标临时变量是否和表达式中使用的任何临时变量重名。
- 检查是否更新了内存位置的值就变得困难很多,因为两个不同的内存表达式可以指向同一个位置,这种情况称为别名/Alias。更加精确的保守方法是进行别名分析/Alias Analysis,这里不再赘述。
2.2 将 CALL 节点移到顶层¶
回忆:CALL 的问题在于会覆写寄存器以及产生副作用,解决方法还是使用临时变量:将 CALL(func, args) 转换成 ESEQ(MOVE(TEMP t, CALL(func, args)), TEMP t)。其效果就变成了每一个 CALL 节点的父节点要么就是 EXP 节点,要么就是 MOVE(TEMP t, ...) 节点。
因此,BINOP(+, CALL(f, []), CALL(g, [])) 可以转换成 SEQ(MOVE(TEMP t1, CALL(f, [])), SEQ(MOVE(TEMP t2, CALL(g, [])), BINOP(+, TEMP t1, TEMP t2)))。
对于特殊情况,比如仅仅利用 CALL 的副作用或者直接对 CALL 返回值进行赋值的情况,这两种我们保持中间表示树不变:

2.3 消除 SEQ 节点¶
在应用完上述规则之后,我们得到的树可能形如:SEQ(SEQ(SEQ(..., sx), sy), sz),需要将每一个 SEQ 节点转换成另一个 SEQ 节点的右节点,应用规则:SEQ(SEQ(a, b), c) -> SEQ(a, SEQ(b, c))。这样我们就得到了形如 SEQ(s1, SEQ(s2, SEQ(s3, ...))) 的树。这就可以看成一列语句 s1, s2, s3, ... 了。

3. 处理条件分支¶
CJUMP 的问题在于大部分机器不具备两个分支分别跳转到两个块的这种功能,因此我们们的目标是将 CJUMP 节点转化成类似于 CMP 节点和条件跳转指令的实现。解决方法分两步走:
- 第一步:将一列规范树组装成基本块,目标是在内部没有跳转指令和
LABEL节点; - 第二步:将基本块排列成轨迹/Traces,目标是
CJUMP之后紧跟false标号。
3.1 基本块¶
基本块是一系列语句,进入则一定一路执行到块末尾,其开头一定是一个 LABEL 伪指令,结尾一定是跳转、条件跳转或者返回等语句,在中间不含任何 LABEL 和跳转指令。
事实上,由于没有任何与跳转指令相关的指令,程序只会一路向下执行,正是因为有了跳转指令使程序在执行中途跳出,而跳转的目标地址(也就是 LABEL)令程序在执行中途跳入,才把原本的代码分割为了多个基本块。
控制流图/Control Flow Graph 中的节点是基本块,边就是跳转指令:
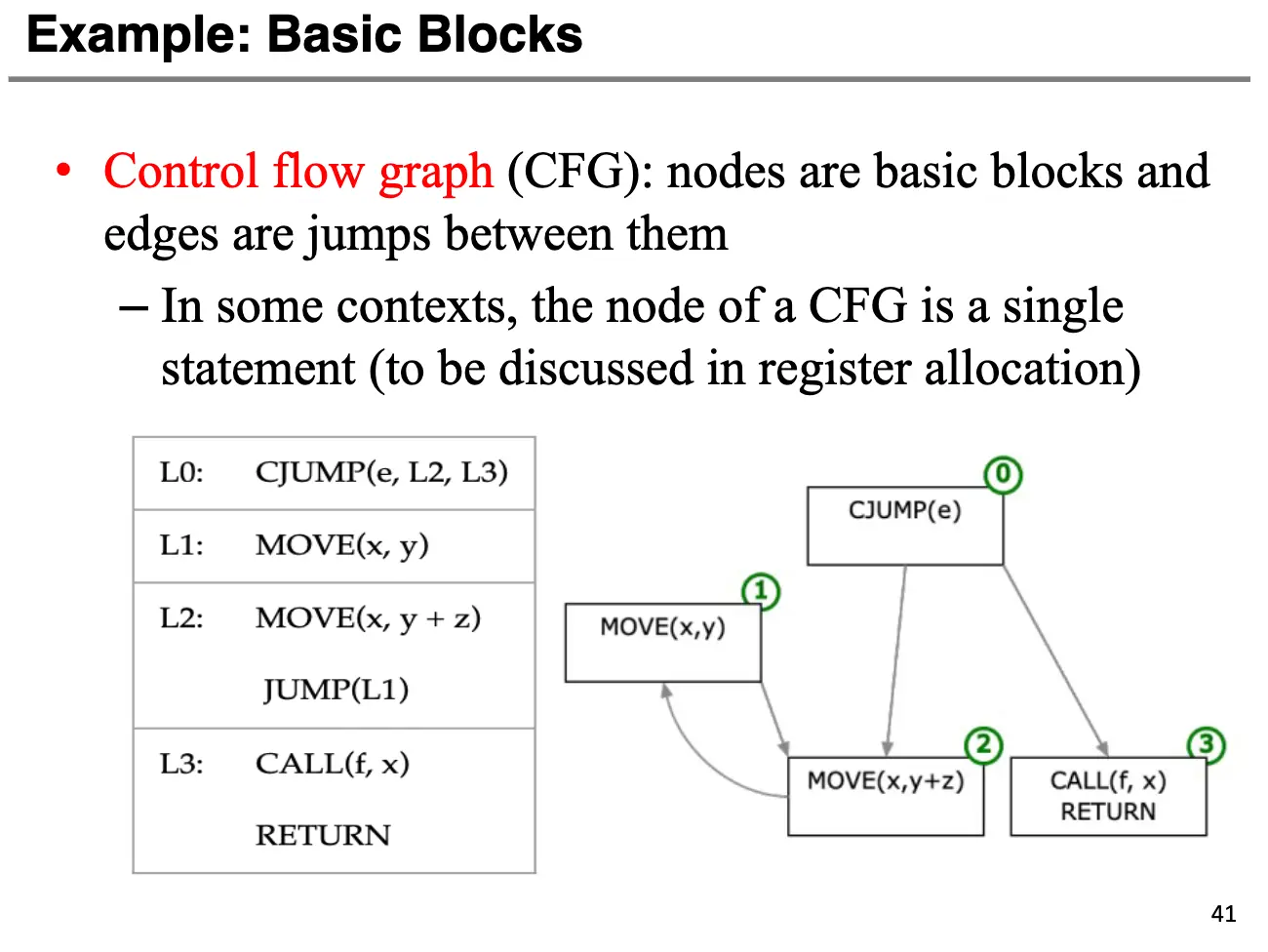
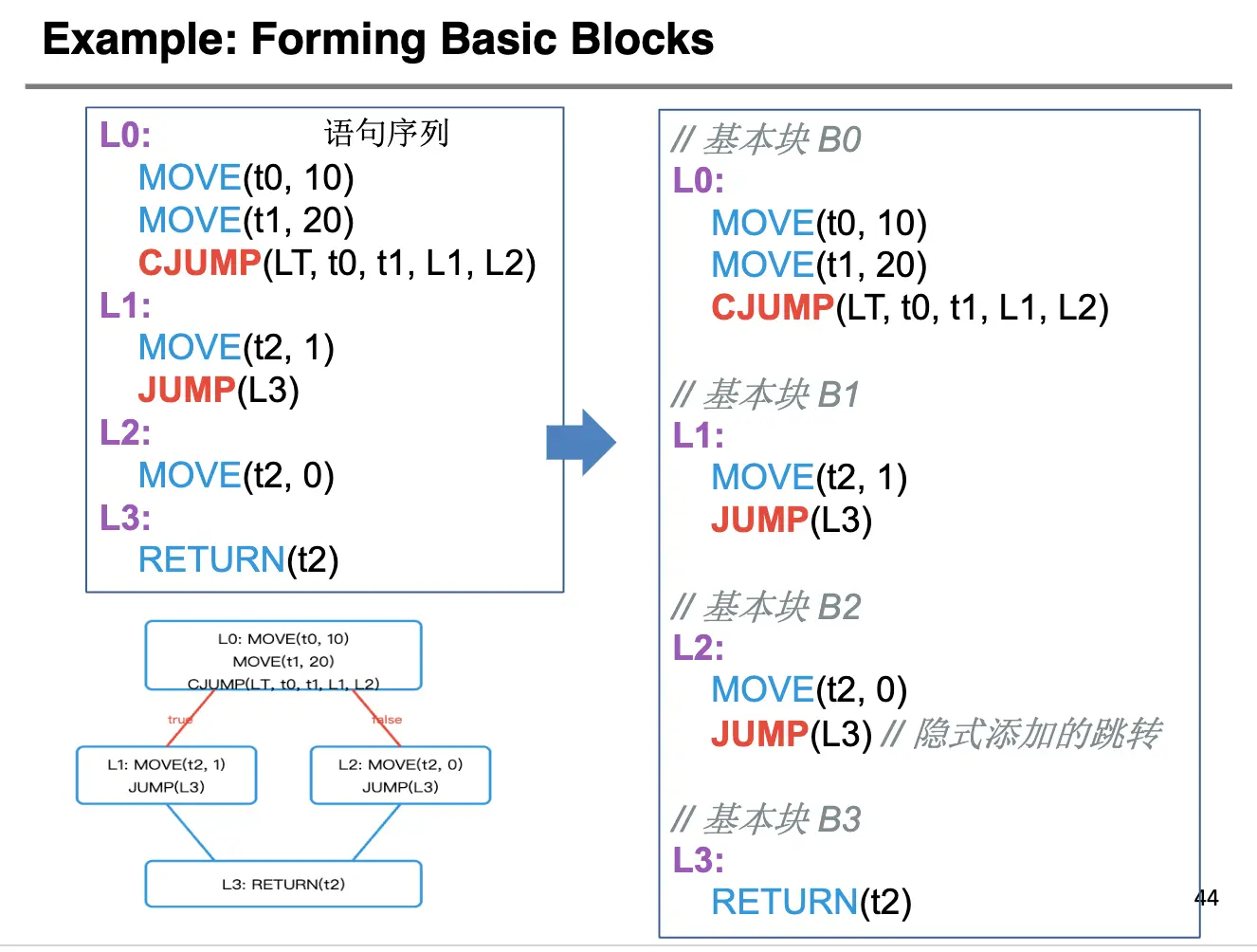
生成过程很自然:
- 从头到尾扫描语句列表,当遇到
LABEL伪指令的时候,就开始一个新块; - 当遇到一个
JUMP或者CJUMP的时候,当前块就结束了; - 如果一个块并不以
JUMP或者CJUMP结束,那么就添加一个JUMP指令指向下一个块; - 如果一个块不以
LABEL开头,那么就添加一个LABEL指令在块的开始。
3.2 轨迹/Traces¶
基本块无论怎么排列都不会影响执行结果,这是因为基本块之间通过 CJUMP 和 JUMP 之间进行链接,定义了实际的执行路径,不依赖于其在代码文件只中的物理顺序。因此我们可以进行一些优化,尽可能减少跳转或者提升跳转效率。比如:
- 对于
CJUMP,尝试将false标号直接放置在CJUMP之后,这样就可以 fall through; - 对于
JUMP,尝试直接将跳转的目标块放到JUMP之后,这样就可以减少跳转指令的数量; - 将频繁执行的代码序列放在一起,进而提升指令缓存命中率;
- 创建更容易进行分支预测的分支模式,进而减少流水线停顿。
对于下面的图来讲,我们显然应该按照 Layout 1 的顺序排序基本块,这样可以减少跳转的次数,减少流水线停顿。
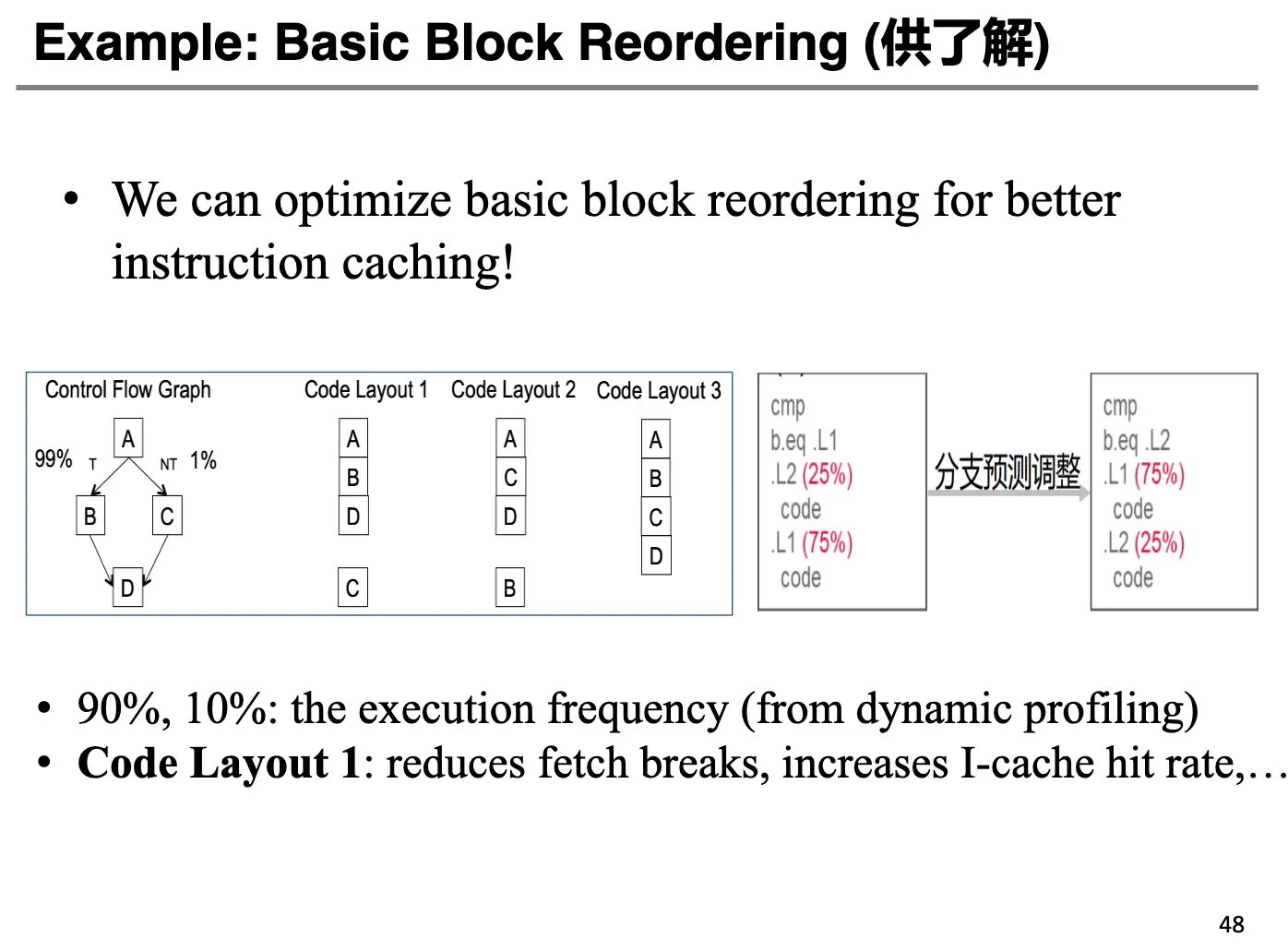
一个轨迹/Trace 是在程序执行过程中可以按照顺序执行的指令序列,可以包含条件分支。换句话说,几个链接在一起的基本块构成了一个 Trace。我们的目标是构造一组覆盖整个程序的轨迹集合,其中每一个 Trace 都没有环,每一个基本块必须严格只在一个 Trace 中出现。
简单的贪心算法的形式化描述如下:

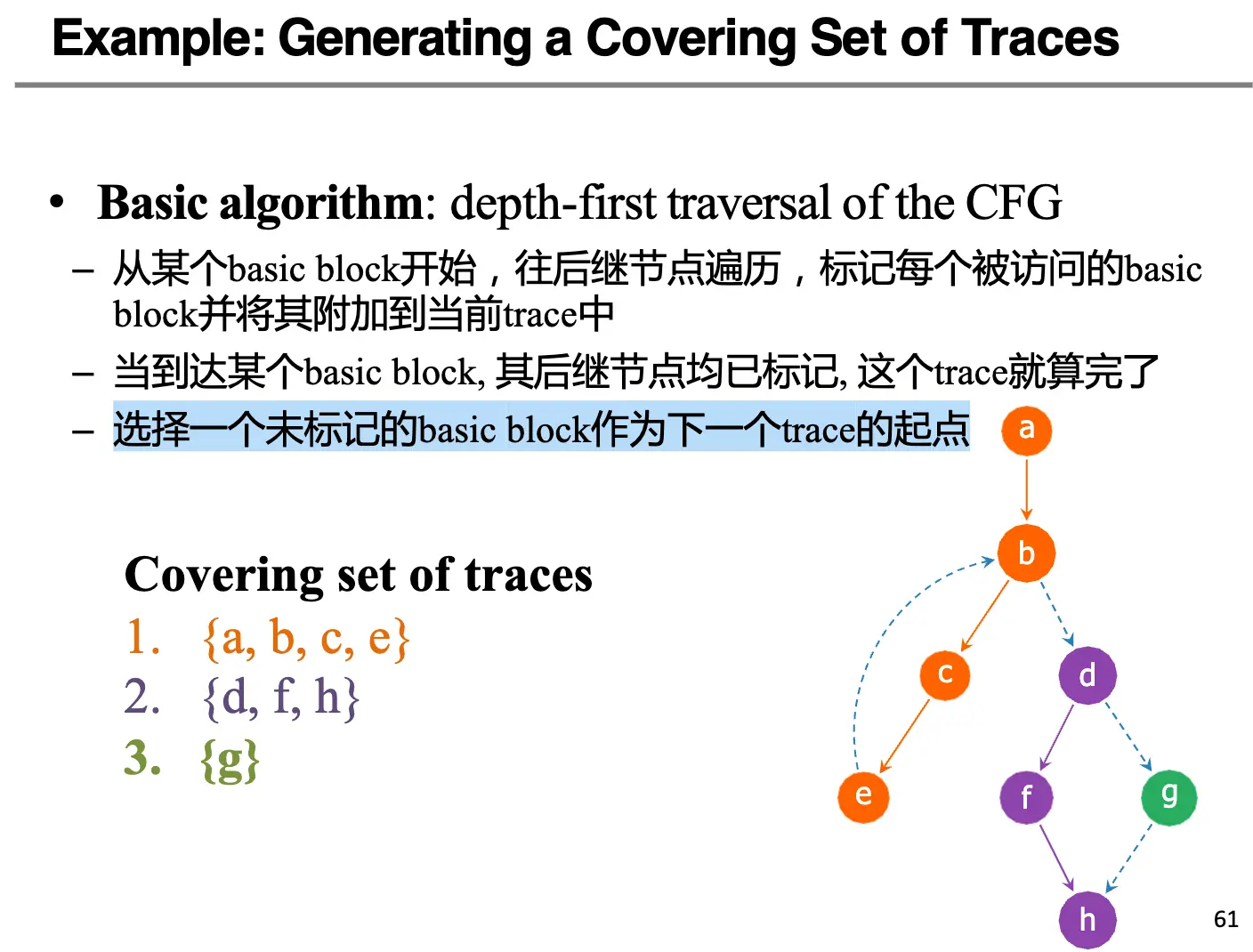
简单来说,我们只需要从源节点开始跑一个深度优先搜索(Depth-first Traversal of the CFG)就可以,详细描述如下:
- 如何计算一个 Trace:从某一个 Basic Block 开始,往后继节点遍历,标记每一个被访问的基本块并将其附加到当前 Trace 之中,当访问到一个后继结点均被标记的节点或者访问到一个没有后继节点的节点的时候,当前 Trace 就计算完成了;
- 如何计算新的 Trace:选择没有被标记的一个基本块作为下一个 Trace 的起点;
- 全局终止条件:不断迭代一直到所有基本块都被标记。
代码在组织成 Trace 之后,很多(但不是所有的)CJUMP 指令后面都紧跟着其 false 标号,我们需要处理那些后面没有跟随 false 标号的 CJUMP 指令:对于 CJUMP(>, x, y, Lt, Lf), LABEL Lt:直接将 OP 取反,标签交换,变成 CJUMP(<=, x, y, Lf, Lt),就可以了。
如果 CJUMP 后面不是真标签也不是假标签,解决方法是在后面添加一个新的标签和跳转指令:

最后,再选择迹优化方案产生所谓最优迹/Optimal Trace 的时候,我们需要注意:最优性本身需要标准,可能的指导原则可能如下:
- 热点路径优先/Hot Path Prioritization:将频繁执行的代码块放在同一个迹中;
- 局部性增强/Locality Enhancement:将相关的代码(逻辑上或执行上)放在内存中相邻的位置,这可以改善缓存性能;
- 跳转最小化/Jump Minimization:减少常见执行路径中无条件跳转的数量,跳转会打断处理器的流水线,降低效率。
