Topic 6:中间表示生成¶
约 2469 个字 24 行代码 13 张图片 预计阅读时间 9 分钟
回顾一下编译器的组成,我们可以简单地分成三个阶段:
- 前端:词法分析、语法分析、语义分析,从源码生成抽象语法树(也可以生成 IR);
- 中端:中间表示生成、机器无关代码优化,基于 IR 的分析和变换,也可能生成新的 IR;
- 后端:指令选择、寄存器分配、指令调度等,进行机器相关优化,从 IR 生成目标代码。
Outline
1. 中间表示概述¶
如果不使用 IR,直接将 M 种源语言翻译成 N 种目标语言,那么我们需要 M * N 种不同的编译器,这显然是不现实的。但是统一使用一种 IR 之后,就只需要 M 个前端和 N 个后端了。
可以见得,直接生成目标机器码的设计一方面阻碍了模块型,一方面也限制了可移植性。
实际的编译器常常采用多层 IR 设计,这样支持了多种不同层次的分析与变换。按照抽象层次来讲,可以分为下面三种:
- 高层中间表示/High-level IR:贴近输入语言,方便从前端生成,比如 Rust 的 HIR IR;
- 底层中间表示/Low-level IR:贴近目标语言,方便目标代码生成,比如 GCC 的 RTL 中间表示;
- 中层中间表示/Middle-level IR:介于高层和底层之间,比如 Numba 和 TVM 的 IR。
但是这三种之间并没有明确的界限。
按照结构特征分类,可以分为下面三种:
- 结构化表示/Structural:一般是图形化的,比如树和有向无环图,大量的用在源码到源码的转换上;
- 线性表示:存储布局是线性的,比如有三地址码、栈机;
- 混合表示/Hybrid:介于结构化和线性之间,结合了结构化和线性的特点。
下面详细介绍三地址码,其接近大多数目标机器的执行模型,支持大多数目标机器移动的数据类型和操作,提供高于机器码的抽象表达能力,但是这种表达能力是有限的。三地址码的一般形式是 \(x = y \operatorname*{op} z\)。每一个指令最多具有一个算符,并且最多具有三个操作数。比如表达式 \(x + y * z\) 的三地址语句序列就是 \(t_1 = y * z, t_2 = x + t_1\)。可以看作按照从深到浅的顺序,将表达式树的节点依次写成三地址语句。

下面是一个翻译的例子:

整个三地址指令序列通过一个链表来实现,最常见的实现是使用四元式/Quadruples,每一个 TAC 指令使用一个包含四个字段的结构体表示,比如 \((\mathrm{op}, \mathrm{arg}_1, \mathrm{arg}_2, \mathrm{result})\)。对于不需要三个地址的执行,比如一元运算、赋值、跳转和标签,某些地址字段会被设置为空,比如使用 _ 代表空。典型的例子有:
t1 = x > 0->(gt, x, 0, t1)if_false t1 goto L1->(if_false, t1, L1, _)fact = 1->(asn, 1, _, fact)label L2->(lab, L2, _, _)
其余实现包括三元式/Triples 和间接三元式/Indirect Triples。
静态单赋值/Static Single Assignment/SSA 是一种特殊的三地址码,其所有变量在代码之中只被赋值一次。
下面是原始代码和 SSA 的版本的对比:
SSA 方便了编译器的很多分析和优化,比如查询 def-use 信息,基于 SSA 的稀疏分析加速算法,以及一些算法也严格依赖 SSA。SSA 也广泛应用于现代编译器中,比如 LLVM。
2. IR Tree 的中间表示¶
现代的编译器使用多级 IR 设计,越到后面阶段的 IR 越接近目标机器的机器码,但是 Tiger 编译器只使用单个 IR,大致翻译流程为:AST -> IR Tree -> Assembly -> Machine Code。使用 BNF 形式的文法描述为:

IR 中间指令列举如下:


简单举几个例子:
BINOP(PLUS, TEMP(t1), CONST(1))对应着t1 + 1;MEM(CONST(100))对应着访问内存地址为 100 的值;ESEQ(MOVE(TEMP(t1), CONST(1)), TEMP(t1))对应着先计算t1 = 1,然后计算表达式t1;;MOVE(MEM(e1), e2)对应着*e1 = e2;;EXP(CALL(NAME(print), ...))对应着调用print函数并且丢弃返回值;CJUMP(EQ, TEMP(t1), CONST(0), L1, L2)对应着if (t1 == 0) goto L1; else goto L2;;SEQ(MOVE(...), JUMP(...))对应着赋值之后直接跳转。
对于 \(\operatorname*{ESEQ}(s, e)\),其中对 \(s\) 求值是为了使用其副作用,在求值结束之后,对 \(e\) 求值作为结果,这里语句 \(s\) 不返回值。其中副作用意味着更新某些内存单元的内容或者临时寄存器的值。
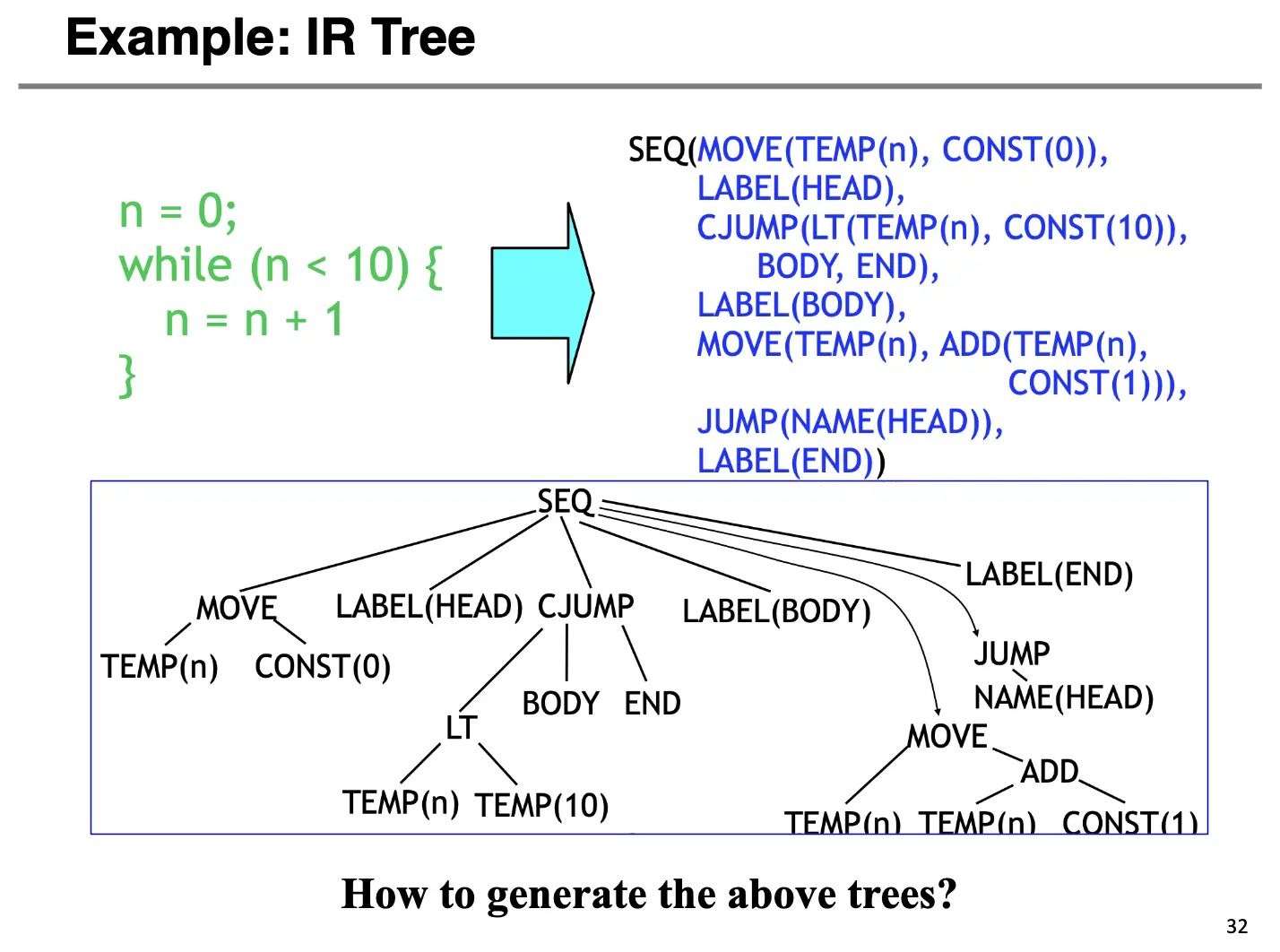
3. IR Tree 的生成¶
这部分太多了我靠
3.1 概述¶
简单来说,Tiger 语言中的表达式分为三类:
- Ex:带有返回值的 AST 表达式,比如
x和a + b; - Nx:不带有返回值的 AST 表达式,比如
print(x); - Cx:条件表达式,返回值为布尔值。

很多情况下我们需要在不同的表达式之间进行转换,这部分我们就可以看见,其实 IR 翻译是上下文有关问题,就没办法使用 CFG 刻画了。解决方法是使用不同表达式之间转化的 Utility。

对于简单的声明在当前过程内的栈帧的变量,其相对于桢指针的偏移量 \(k\) 是已知的,并且 Tiger 语言的所有变量都是一个字大小的,因此我们可以翻译成这样的中间代码:MEM(BINOP(PLUS, TEMP FP, CONST k))。
对于需要静态链访问的变量,需要翻译成如下的中间代码:MEM(+(CONST k_n, MEM(+(CONST k_{n-1}, ... MEM(+(CONST k_1, TEMP FP)) ... )))。注意到我们使用了 +(e1, e2) 来表示 BINOP(PLUS, e1, e2)。
对于数组和记录,其实就是一种固定的指向一个元素/字段序列的指针,赋值拷贝的是指针而非内容,因此下面的代码在执行后,a 和 b 都指向了一个包含 12 个 7 的数组:
3.2 结构左值¶
右值出现在赋值语句的右侧,不表示一个可以赋值的内存位置/Assignable Location,只是一个可以被计算出来但是不能被赋值的值。左值出现在赋值语句的左侧,表示一个可以被赋值的内存位置,同样也可以出现在赋值语句的右侧,这里其指代该内存位置中存储的内容。
对于左值,我们大体可以分为标量左值/Scalar Lvalue 和结构化左值/Structured Lvalue。当其只有一个部分的时候/has only one component,一个整数或者指针值就是一个标量左值,Tiger 中所有变量和左值都是标量的;C 或者 Pascal 含有结构化左值,比如说 C 中的结构体,结构化左值含有多个成员。
标量左值和结构化左值之间的区别极大影响了编译器如何处理赋值操作和内存操作。对于标量左值,使用 MEM(e) 就已经足够访问内存了,并且所有的赋值都是简单的字大小操作/Word-sized operations。对于结构化左值,我们不仅仅需要记录值的大小,还需要处理多字操作/Multi-word operations。
对于结构左值的整体赋值,对应的地址计算就应该是 MEM(+(TEMP fp, CONST k), S) 了,其中 S 指示了要获取或者存储的对象的大小。
3.3 数组下标和字段选择¶
在 Tiger 语言中,所有的记录类型和数组实际上都是指向一个连续的内存块的指针,因此没有实际上的结构左值。下面是计算 a[i+1] 和 a.f 的地址的中间代码:

3.4 条件语句¶
对于条件语句,我们使用 CJUMP(op, e1, e2, T, F) 来表示 if (e1 op e2) goto T; else goto F;:

额外还需要实现短路操作:对于逻辑与 a & b 来讲,首先计算 a,如果为假就直接得到假结果,否则继续计算 b,最终结果为 b 的值;对于逻辑或 a | b 来讲,首先计算 a,如果为真就直接得到真结果,否则继续计算 b,最终结果为 b 的值。下面以逻辑与作为 if 语句的条件为例:

3.5 循环¶
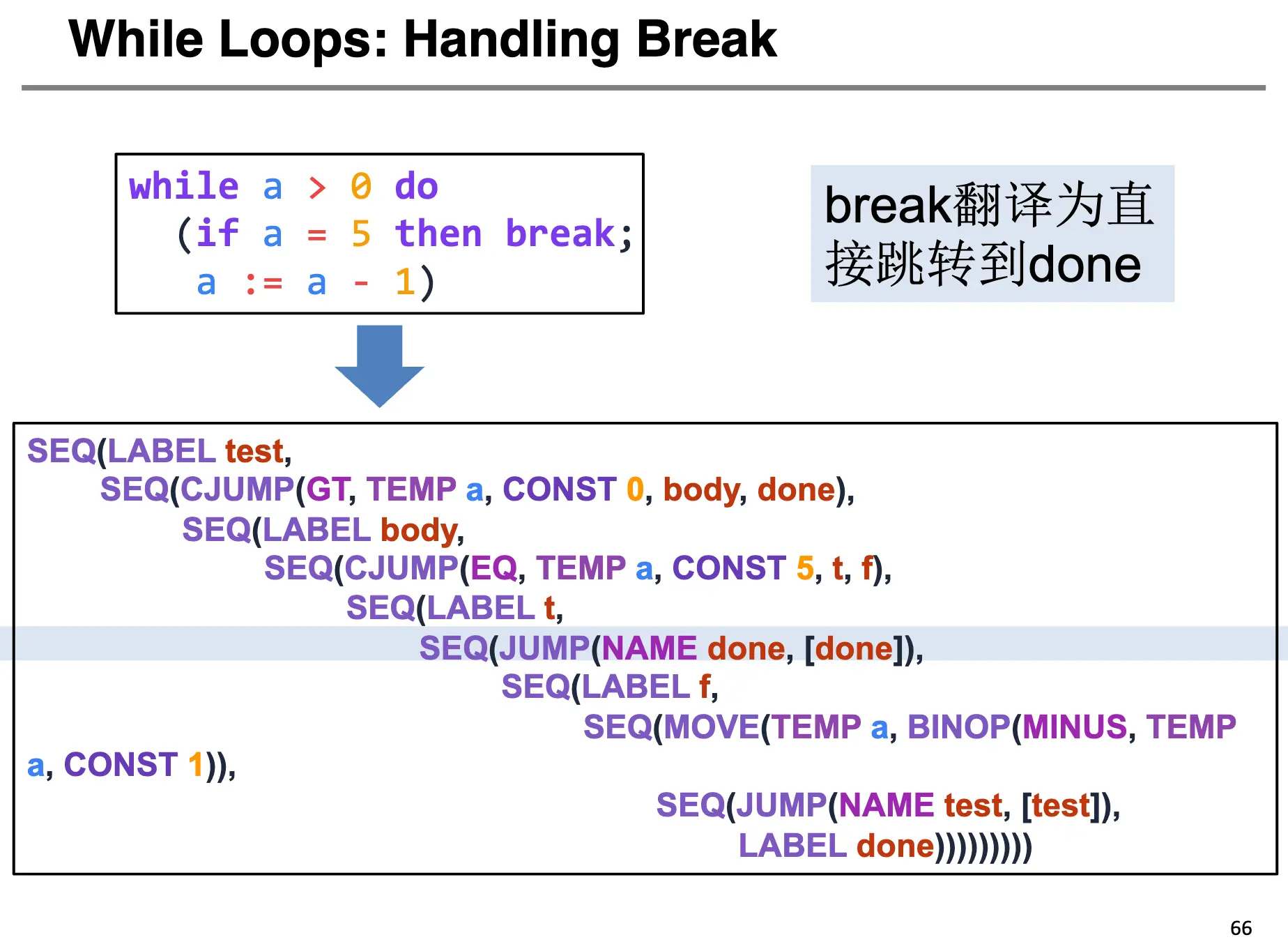
while 循环的一般布局是这样的:
对于 break 语句,其翻译为直接跳转到 done,下面是一个例子:
for 循环直接重写抽象语法,让其变成 let 语句和 while 循环的组合:
这个问题在于对于 hi 为 maxint 的时候,i + 1 就会溢出,解决方法之一是将测试放在循环底部,在递增 i 之前检查 i < hi,而不是检查 i <= hi。另外一种方法是添加初始范围检查,检查 lo <= hi,如果初始条件不满足,就可以直接跳过整个循环。
3.6 函数调用¶
除了需要静态链,调用函数是很简单的,可以直接将 call f(a1, a2, ... an) 翻译成 CALL(NAME(f), [sl, a1, a2, ... an]),其中 sl 是静态链。
3.7 变量声明¶
对于变量声明,需要在栈帧之中保留空间,并且生成对应的初始化表达式:

3.8 函数声明¶
函数在翻译成汇编语言的时候,需要翻译出三个组件:Prologue、Body 和 Epilogue。
对于 Prologue:
- 生成特定的伪指令,告诉汇编器这是函数的开头,并且生成对应的标签,调用者跳转到这个标签来执行函数;
- 生成指令调整栈指针,分配新的栈,将被调用者保存寄存其和返回地址压入栈中,然后保存函数参数和静态链;
对于 Body:翻译 Tiger 语言中的所有表达式;
对于 Epilogue:
- 将返回值移动到一个特殊的寄存器;
- 产生 Load 指令,恢复被调用者保存寄存器,并且重置栈指针;
- 生成返回指令;
- 生成伪指令,告诉汇编器这是函数的结尾。