Topic 5:活动记录¶
约 2748 个字 45 行代码 9 张图片 预计阅读时间 10 分钟
1. 栈帧¶
An invocation of a function P is an activation of P.
对于下面的 OCaml 代码:
每次对 f 的调用都创建了参数 x 的一个新的实例,每次进入到函数体的时候都创建了一个新的局部变量 y。
活动记录/Activation Record 其实就是栈帧/Stack Frame,其是栈上的一块内存区域,联系了调用者和被调用者,其内容包括:
- 相关的机器状态(Saved rigisters...);
- 返回值、对应的局部数据;
- 指向非局部数据的活动记录的指针。
下面是一个经典的栈帧布局模型:

当一个函数 f 调用一个函数 g 的时候,我们称 f 为调用者/Caller,g 为被调用者/Callee。在一些 ISA 以及对应的调用管理的时候,当调用函数 g 的时候,栈指针指向传入的第一个参数,同时在进入函数 g 的时候,我们简单地将栈指针减去一个栈帧的大小,从而分配一个新栈帧。将旧的桢指针保存到内存中,设置新的桢指针为栈指针,使得桢指针指向当前栈帧的基地址。当函数退出的时候,我们设置栈指针为桢指针,恢复栈指针,同时从保存的位置恢复桢指针。
考察全局变量以及堆上的存储,注意到对一个全局变量的引用都指向同一个对象,因此我们不能将一个全局变量存在一个活动记录之中。并且全局变量被分配给一个固定的地址(Statically Allocated)。而堆变量的生命周期很可能超过创建它的过程,其典型收到 new 和 delete 的控制,因此我们也不能将其保存在活动记录中。
2. 寄存器的使用¶
问题:将所有值都存在栈帧上会导致 Memory Traffic,直白点说就是访问内存的速度比较慢。
解决方法:将尽可能多的值都存在寄存器上,一般有这些:
- 一些函数参数、函数返回地址和函数返回值;
- 一些局部变量和一些表达式的临时值;
寄存器的使用场景之一是传递参数/Parameter Passing。对于 Tiger 来说,参数的传递方式为 Call-by-value:传递的是实际参数的值,这些值被用来初始化形式参数,在函数内部对形式参数的修改不会影响到函数外部的实际参数。
在上世纪 70 年代的大多数系统上,参数通过栈被传递,这样会导致内存流量过大。解决方法之一来自于下面观察:大多数函数的参数数目不会超过四个,并且极少数函数参数数目超过六个。于是现代机器的参数传递约定为,前 4/6 个参数通过寄存其传递,比如 x86-64 前六个参数使用 %rdi, %rsi, %rdx, %rcx, %r8, %r9 传递,剩下的参数使用栈传递。
调用函数会出现一个需求:我们需要保存寄存器的状态。因此出现了寄存其调用惯例以及 Caller-Saved Registers 和 Callee-Saved Registers 的概念。
- Caller-Saved Registers:Caller 函数负责保存,在函数调用之后,还需要使用的寄存器的值,Caller mast save and restore them;
- Callee-Saved Registers:Callee 函数负责保存和恢复,Callee 需要使用的寄存其的原始值。
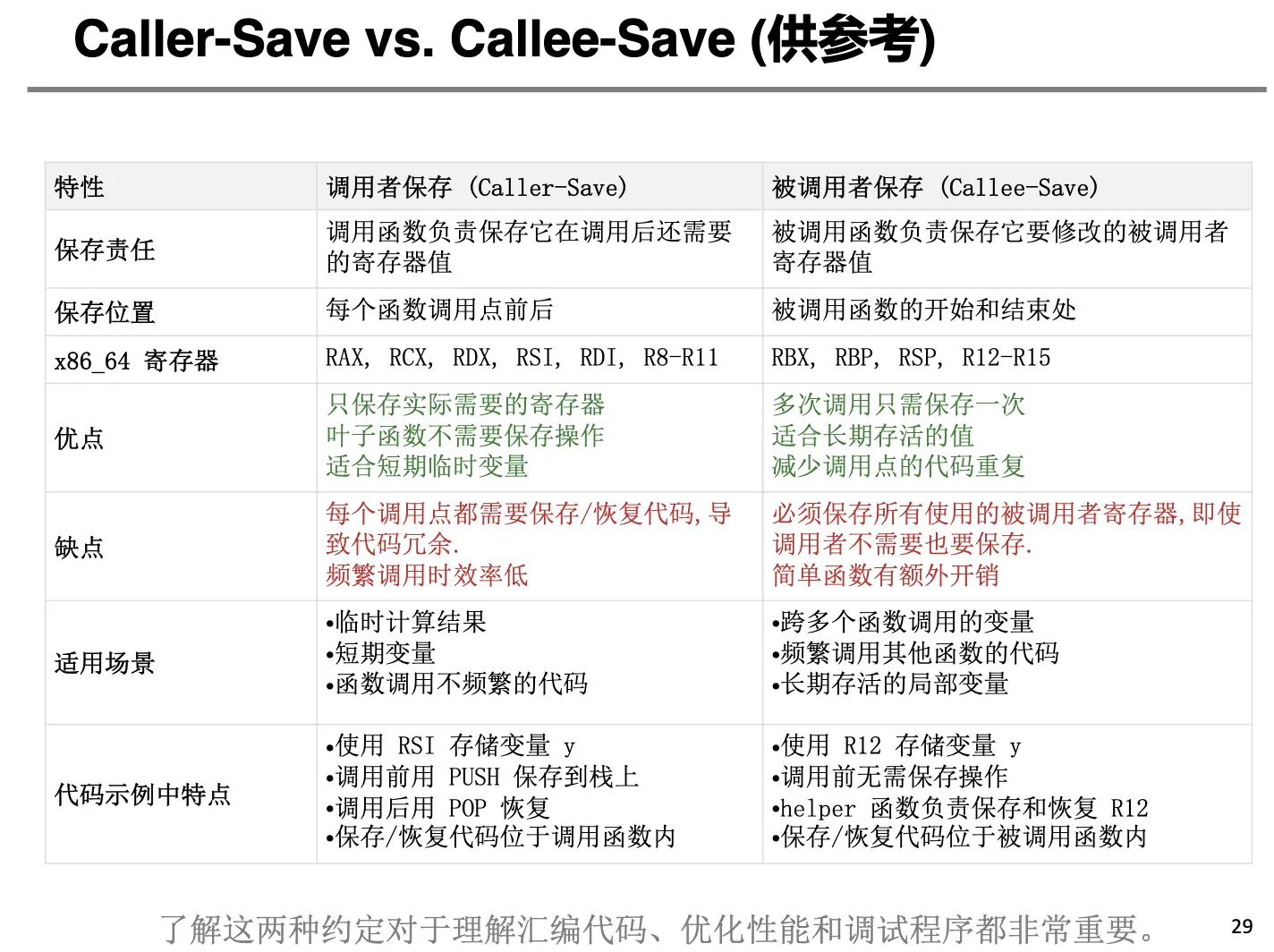
比如 %rdi 在传参之前,必须将 %rdi 的值保存到栈上,在函数返回之后,恢复 %rdi 的值。
但是这样的传递参数又会引起一些额外的内存流量,比如对于代码:
假设 f 在寄存器 r1 接受参数,又通过 r1 向 h 传递参数 z,那么 f 需要在调用 h 之前在栈帧上保存 r1 的旧值,在 h 返回之后恢复 r1 的旧值,因此还会引起额外的内存流量。解决方法有四:
- 活跃性分析:如果没有第五行,也就是在调用
h之后a的值就不再使用了,这时候参数a就是 Dead,这样就可以覆写掉r1的值,从而不需要保存和恢复r1的值; - 全局寄存器分配/过程间寄存器分配:不同的函数使用不同的寄存器传递参数,避免冲突;
- 叶子过程/Leaf Procedure:我们将没有调用其他函数的函数称为叶子过程,叶子过程天然减少了寄存器的保存需求。
- 使用寄存器窗口/Register Window:这是硬件层面的解决方案,每一个函数调用会分配一个新的窗口寄存器集合。
另一个场景是使用寄存器传递返回值。对于比较老的架构,call 会将下一条指令的地址/返回地址压入栈中,现代方法是将返回地址放在一个指定的寄存器中,比如 x86-64 的 %rip,RISC-V 中的 ra。
寄存器还被用来传递返回值,比如 x86-64 对于整数和指针使用 %rax,对于浮点数返回值使用 %xmm0,RISC-V 中的 a0。
除此之外,某些局部变量和表达式的临时值也会被保存在寄存器中,我们在寄存器分配章节中讨论。
3. 寄存器驻留变量¶
寄存器数目必定有限,显然也并非所有变量都适合放在寄存器中。如果一个变量必须被分配在栈帧之中,其大概会满足下面几个条件:
-
其通过引用传递,或者作为传地址参数,因此其必须有一个内存地址,因此其必须放在内存中;
-
在代码中出现了取地址运算,比如
&x,x必须被分配在栈帧中; -
其被嵌套过程访问,也就是如果一个定义在
f中的过程g访问了定义在f中的变量x,那么x必须被分配在栈帧中,但是并不完全,使用跨过程寄存器分配的时候,被内层函数访问的局部变量有时也可以被放在寄存器中,只要内层函数知道该到哪个地方访问这个变量即可。 -
值太大无法放到一个寄存器,比如一个大结构体,但是有的编译器为了效率起见,会将一个很大的值分散到若干个寄存器中;
- 变量是一个数组,访问需要通过基地址进行地址的算术运算来访问;
- 持有该变量的寄存器另有他用,比如这个寄存器用来传递参数;
- 局部变量和临时变量太多了,多余的变量被溢出/Spill 到栈帧内存之中。
如果一个变量是传地址实参/传引用访问,或者其被取了地址(使用 & 运算符),或者内层嵌套函数对其进行了访问,那么我们称该变量是逃逸的/Escape。
4. 块结构¶
在允许嵌套函数声明的语言中,比如 Tiger、OCaml 和 Python,内层函数可能会使用在外层声明的变量。如果我们使用类 C 的语法,一般可以如下写:
我们可以通过桢指针访问局部变量,注意到桢指针的值在编译期是不知道的,但是我们可以知道每一个局部变量相对于桢指针的偏移。问题来了,g 如何访问 m 呢?方法就是下面三种。
4.1 静态链¶
简单来说,当一个函数 g 被调用的时候,我们可以传递一个额外的指针,其指向定义 g 的那个语法上的静态外侧函数/Statically Enclosing Function f 的(最新)活动记录,这个额外的指针就是静态链。
在实现中,每一个函数都被标注了其静态嵌套深度,当一个深度为 n 的函数访问一个深度为 m 的变量,需要按照静态链连续向上查找 m-n 次,才能在对应的活动记录内找到该变量。


Static Link 的优点在于 Overhead 很小,但是缺点在于需要 \(O(n)\) 的额外时间来查找变量。
4.2 嵌套层次显示表/Display¶
简单来说,我们外呼一个全局数组,其经常被命名为 display,其每一项(第 i 项)包含一个指向嵌套深度为 i 的最新进入进程的活动记录的指针。这个全局数组就是所谓的嵌套层次显示表/Display。当进入一个函数或者退出一个函数的时候更新 Display,可以直接访问任何嵌套深度为 i 的变量。
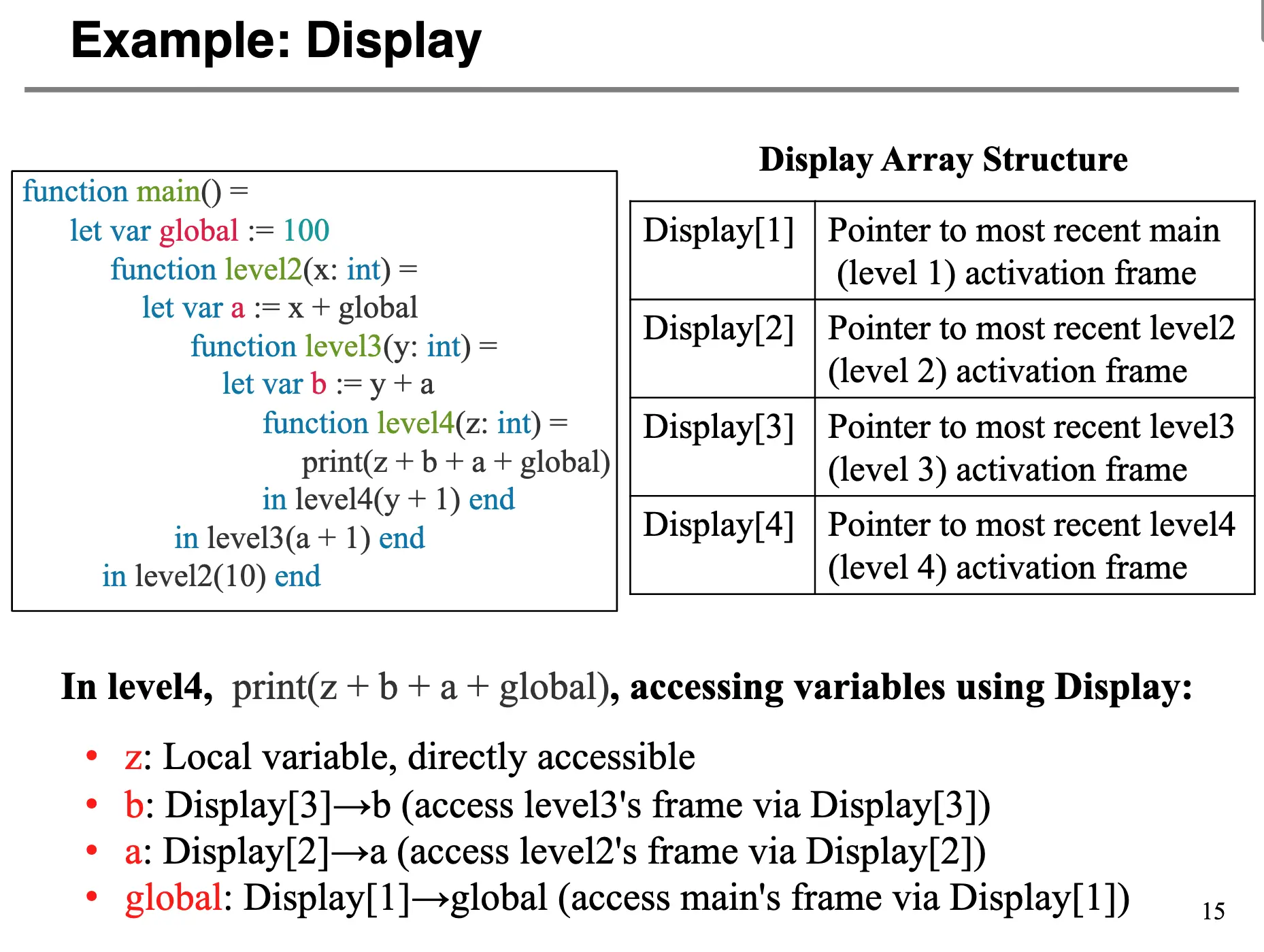

优点在于变量访问效率很高,对于任何语义等级的临时变量,只需要 \(O(1)\) 的时间,代码生成速度也是很高的,不需要多重间接寻址。但是上下文切换开销很大,切换过程也很复杂。另一方面,显然 Display 是一个全局资源,因此需要额外处理并发。
4.3 Lambda 提升¶
当 f 调用 g 的时候,每一个 f 的变量都作为额外的参数传递给 g。方法如下:
- 对每一个函数,鉴定出其使用的所有非局部变量;
- 将那些非局部变量作为额外的参数添加到这个函数的参数列表中,修改所有对
f的调用,将这些非局部变量的当前值作为实参传递给f;

这样一来,程序就没有嵌套函数了,所有的函数都处在一个水平了,我们也不需要静态链或者 Display 了。其优点在于简化了运行时环境,不需要维持复杂的栈帧、静态链和 Display,也让数据流变得更加显式,为分析和优化提供了可能。缺点在于需要传递更多的参数,引起 Overhead,对于高阶函数也不一定适用。
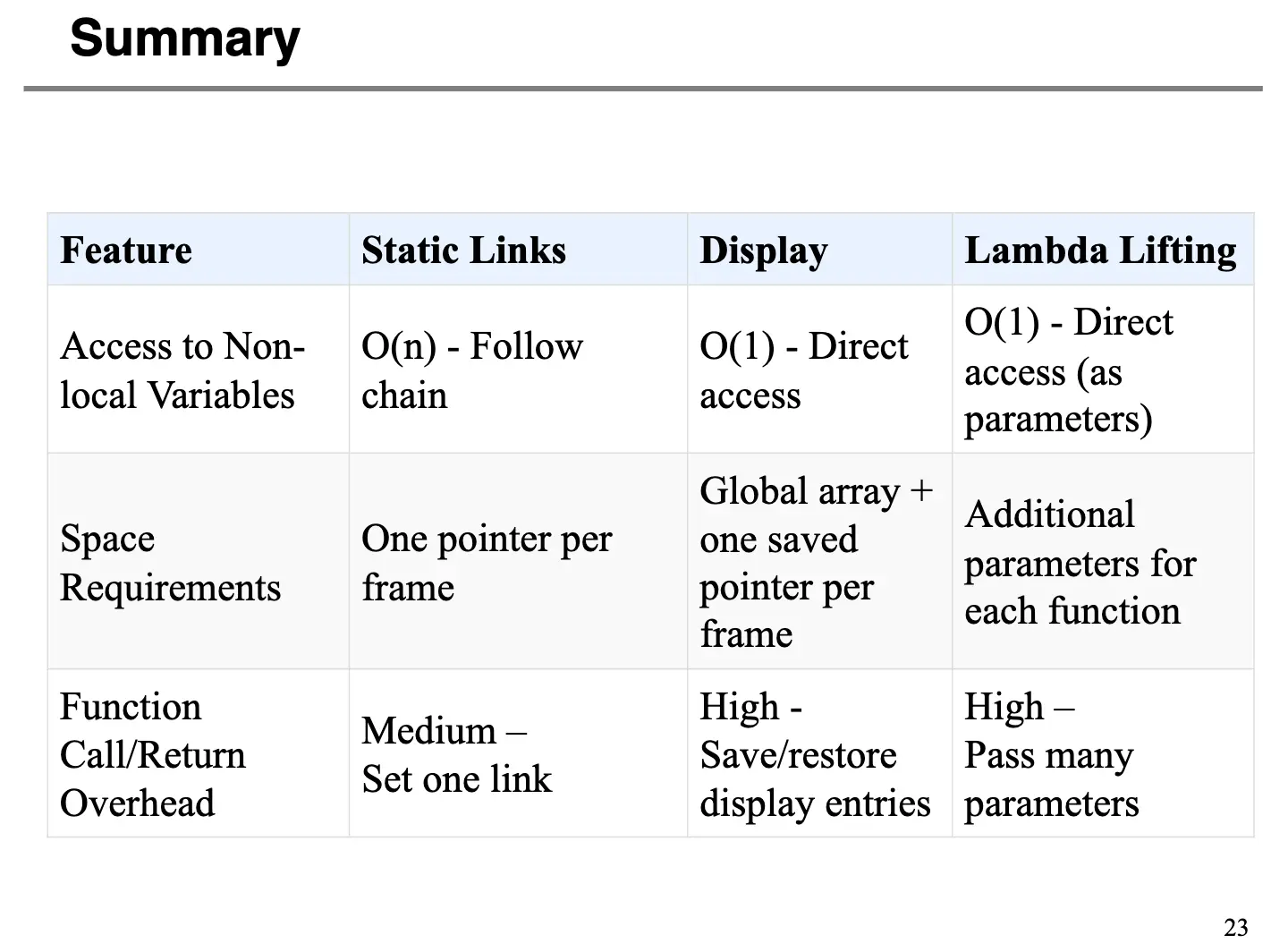
注意课上的活动记录第二个 PPT 的附录例子非常好,考试之前一定复习一下
5. Tiger 的典型栈帧布局¶
一图流,没有过多好说的。需要注意 Frame Pointer 为特定的寄存器,其值为栈上的内存地址,宏观视角是一个 Stack Link,具体是某一个函数的 Frame Point。

然而这样的栈帧很难支持高阶函数,对于高阶函数,当函数返回之后仍然保持局部变量是必要的,然是我们目前假设的是局部变量不会在函数返回之后再使用。