Part 3: Lecture 12 to Lecture 15¶
约 5897 个字 230 行代码 34 张图片 预计阅读时间 23 分钟
Table of Contents
Lecture 12: Deep Learning Software¶
这段有点过时了,PPT 上介绍的是 PyTorch 1.10,现在版本都到 2.7(2025.04.28) 了。但是 PyTorch 的 API 变化不大,所以还是可以参考的。
深度学习框架的核心价值:
- 快速原型设计能力;
- 自动计算梯度;
- 在 GPU/TPU 上高效运行;
PyTorch 的核心概念分为三部分:Tensor、Autograd、nn.Module:
- Tensor:类似于 NumPy 的数组,但可以在 GPU 上运行;
- Autograd:根据 Tensor 构建计算图并且自动计算梯度的包;
- nn.Module:神经网络层的抽象,可以存储状态和更多的可学习权重。
我们使用代码来解释:
Code: Tensor
Code: Autograd I
- 使用
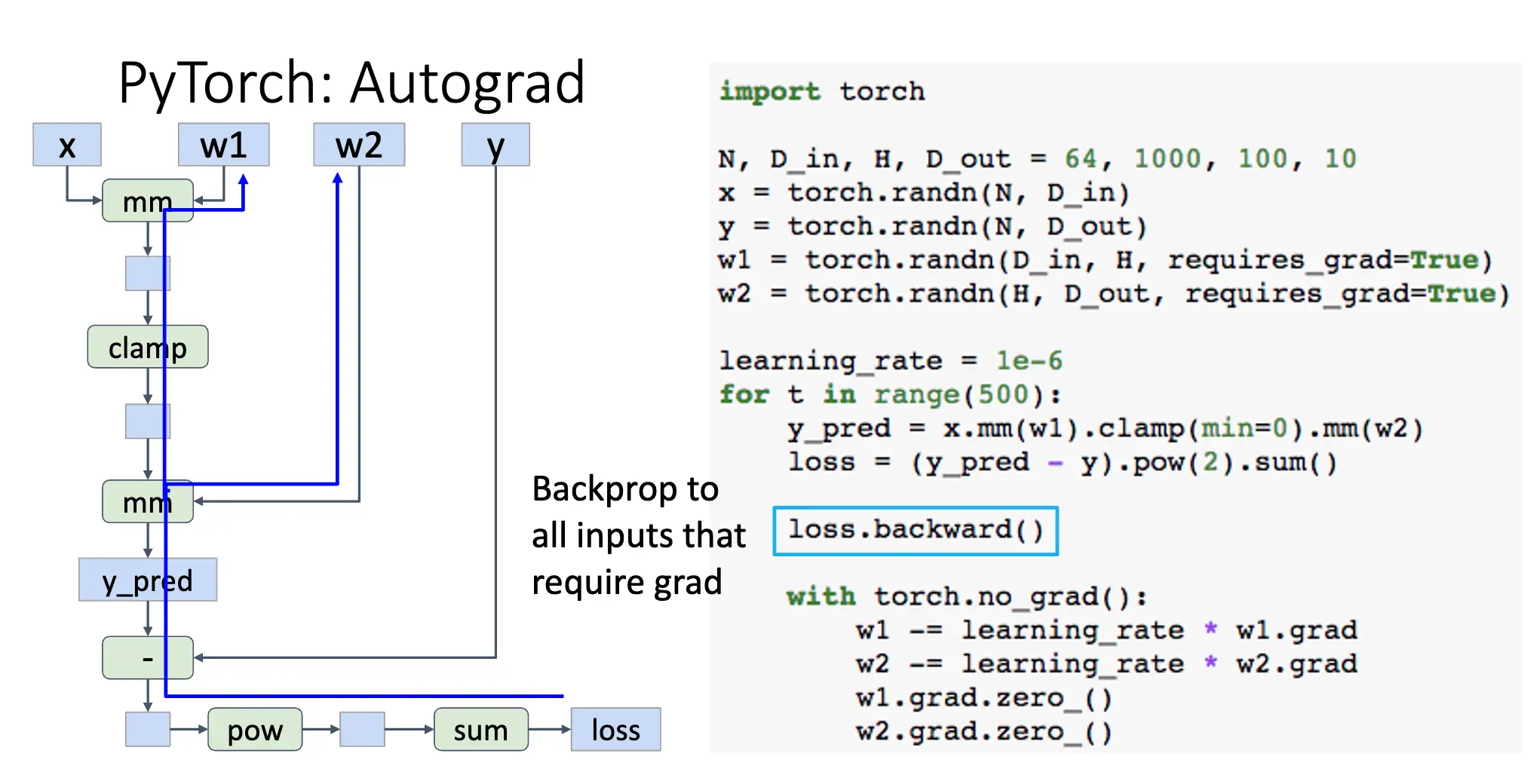
requires_grad=True创建的 Tensor 会记录计算图,并自动计算梯度; - 前向传播正常进行,但是我们不需要记录中间值,而 PyTorch 会在计算图中帮助我们记录;
- 使用
loss.backward()自动计算梯度,梯度记录在所有需要梯度的 Tensor 的grad属性中,每一次调用loss.backward()都会在原有的梯度基础上累加,在反向传播结束的时候,计算图会被释放; - 使用
with torch.no_grad()上下文管理器可以暂时禁用梯度计算,例如在更新参数的时候; - 使用
w1.grad.zero_()手动清零梯度,缺失这一步会导致梯度累加问题,这是因为.backward()方法会累加梯度,而不是直接赋值。 - 对每一个
requires_grad=True的 Tensor 进行的操作都会添加到计算图中,例如clamp、mm等,这些操作的结果 Tensor 也会自动添加requires_grad=True属性。
上面的代码其实会产生这样一个计算图:
对于计算图来说,定义的 Python 函数和定义的 Autograd 算子略有不同:定义算子需要首先定义一个 Function 的子类,然后重写 forward 和 backward 方法。
Code: Autograd II
Code: nn.Module I
torch.nn.Sequential为顺序执行的容器,允许我们按照顺序堆叠多个网络层,自动处理层间链接;- 网络结构包含三层:输入层到隐藏层的线性变换,ReLU 激活函数,隐藏层到输出层的线性变换,分别使用
torch.nn.Linear和torch.nn.ReLU实现; - 前向传播使用
model(x)即可,它会自动按照顺序执行每一层; - 调用
torch.nn.functional.mse_loss自动计算均方损失,loss.backward()自动计算模型中所有参数的梯度(requires_grad=True的张量); - 使用
with torch.no_grad()上下文管理器可以暂时禁用梯度计算,更新参数的时候禁用梯度计算,通过model.parameters()获取模型中所有参数;
Code: nn.Module II
- 使用
torch.optim.Adam作为优化器,构造优化器的时候需要传入模型参数和学习率; - 使用
optimizer.step()更新模型参数,使用optimizer.zero_grad()清零梯度;
Code: nn.Module III
- PyTorch 允许通过继承
torch.nn.Module来创建自定义神经网络模块,其中torch.nn.Module是所有神经网络模块的基类; - 自定义神经网络模块都应该实现
forward方法(Should be overridden by all subclasses),forward方法定义了前向传播的计算过程; - 自定义类的
__init__方法必须调用父类的__init__方法,这样才能正确初始化模块系统。 - 子模块通过属性赋值的方式自动注册,PyTorch 会追踪这些子模块的参数。
Code: nn.Module IV
- 更复杂一些的例子,但是原理没有变化,主要是表示我们可以在容器(比如
torch.nn.Sequential)中使用自定义的模块。
Code: DataLoader
Code: Static Graphs with JIT
TensorFlow 就不写了,现在除了初学者用一用 Keras 之外,前沿很少用了,等到之后可能接触到使用 TensorFlow 的代码的时候再速通。
Lecture 13: Object Detection¶
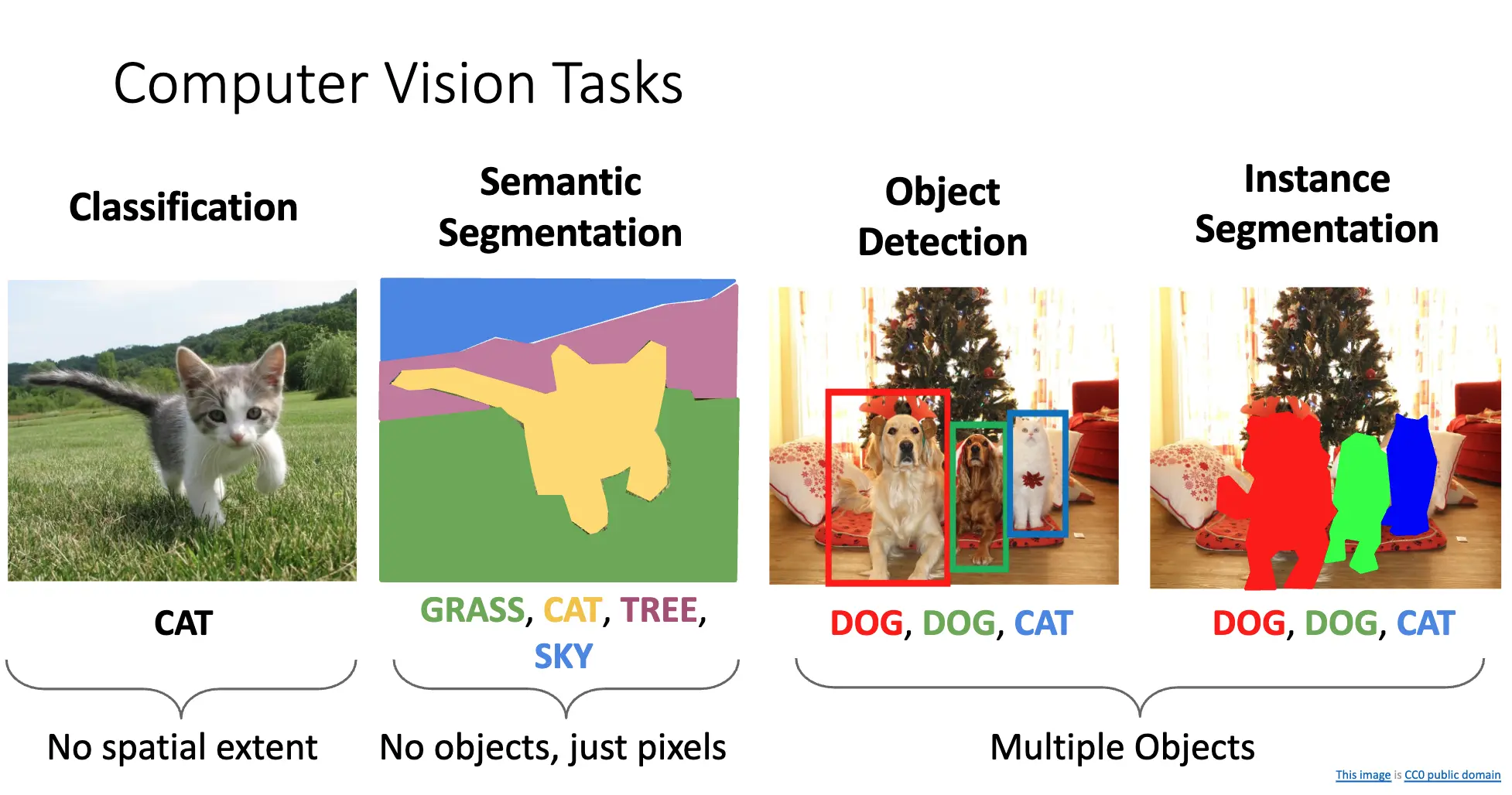
计算机视觉的基本任务可以分为:分类/Classification、语义分割/Semantic Segmentation、目标检测/Object Detection、实例分割/Instance Segmentation。四个问题,其中分类没有空间信息,语义分割只考虑像素,不考虑对象,而目标检测和实例分割考虑对象。
迁移学习-特征提取:在比较大的训练集上训练模型,然后将知识迁移到别的具有较小数据集的新任务上。方法之一是训练一整个神经网络,移除最顶上的层,冻结下面的所有预训练网络层,然后使用得到的网络提取特征,在这些特征上训练新的线性模型。得到的效果一般不错:

迁移学习-模型微调:从预训练的神经网络开始,去除最后一层,在原地方添加一个新的随机初始化的全连接层,然后使用新的数据集训练这个网络。使用技巧包括:
- 使用较小的学习率,比如使用原来学习率十分之一的学习率;
- 先训练特征提取再微调;
- 冻结较低的网络层,节约计算资源;
- 在测试模式下使用 BatchNorm。
迁移学习是常态,比如使用 Fast-RNN 的物体检测以及综合视觉和语言的多模态应用,并且可以帮助训练更快收敛。当然,如果训练数据和时间充分,随机初始化也可能媲美迁移学习。
目标检测的任务与挑战:
- 输入:一个 RGB 图像;
- 输出:一组检测到的对象,对每个对象预测类别标签/Category Label 和边界框/Bounding Box。类别标签是从已知的确定的类别之中选择的,边界框为矩形,一般给出四个参数:
x、y、width、height。 - 多个输出:每个图像都可能有不同数目的物品,因此模型需要能够动态地输出可变数量的检测结果;
- 多种类别输出:不仅仅需要预测类别标签,还需要预测边界框,同时处理不同类型的任务;
- 大尺寸图像:图像一般从小尺寸的 \(224 \times 224\) 转移到较大尺寸/分辨率的图像。
最常见的边界框都是轴对称的,和图像的坐标轴平行;很少有旋转的、不一定和坐标轴平行的定向框/Oriented Boxes。一般的模态检测/Modal Detection 任务输出的边界框只覆盖物体可见的那一部分,非模态检测/Amodal Detection 任务输出的边界框会覆盖物体的整个范围,即使物体的一部分被遮挡。
Intersection of Union/交并比:衡量模型预测的边界框好不好,定义为真实的边界框和预测的边界框的交集和并集的比值。也被称为 Jaccard Index/Jaccard Similarity。交并比大于 0.5 就可以认为预测边界框比较好,大于 0.9 就可以认为预测边界框和真实边界框几乎一致。
我们将检测单一目标的问题分为 Where 和 What 两个问题:
- 首先将一个图片经过神经网络变换成一个 4096 维的特征向量;
- 定位问题/Where:将其视为一个回归问题,经过全连接层输出四个参数,与正确的边界框的四个数据产生 L2 损失 \(L_{\text{reg}}\);
- 分类问题/What:就是一个分类问题,添加全链接层预测物体属于各个类别的分数,使用 Softmax 损失 \(L_{\text{cls}}\);
- 总损失:\(L = L_{\text{cls}} + \lambda L_{\text{reg}}\)。超参数 \(\lambda\) 平衡两个损失的权重;
- 常见的做法是通过迁移学习,使用 ImageNet 预训练的模型上开始训练。
这种方法局限很直接:框架假设每张图片只有一个物体,但是实际中一张图片可能有很多个物体。拒绝方法之一是使用滑动窗口/Sliding Window,核心思想是使用一个固定大小的窗口,在图片的不同位置、不同尺度上滑动,再对裁剪出来的窗口进行单目标检测。
可是滑动窗口的问题在于可能的窗口位置数目太大了:对于一个尺寸为 \(H \times W\) 的图片,如果使用一个 \(h \times w\) 的窗口,那么可能的窗口位置数目就是 \((W - w + 1) \times (H - h + 1)\),对所有可能的窗口大小求和,就是 \(\frac{H(H + 1)}{2} \times \frac{W(W + 1)}{2}\)。数量级爆炸。
Region Proposal/区域提议:与其暴力穷举每一个可能的窗口,不图先用简单的方法提议一小部分可能包含物体的候选区域,然后再将其送到神经网络中进行分类和回归。方法通常基于一些启发式规则或者简单的图像特征,优势是速度很快,Selective Search 可以在几秒钟在 CPU 上生成大约 2000 个候选区域。

Region-Based CNN/R-CNN:结合了 Region Proposal 和 CNN 的检测方法。
- 对于输入图像,进行区域提议,生成大约 2000 个候选区域/Regions of Interest/RoI;
- 对于每一个候选区域,强制缩放到一个固定尺寸,比如 \(224 \times 224\),这是为了方便输入神经网络;
- 将 Wraped Image Regions 独立的输入一个预训练的神经网络进行前向传播,提取特征,对得到的特征进行分类;
- 在最后一步,还进行边界框回归,预测一个变换参数 \((t_x, t_y, t_w, t_h)\),对候选区域进行变换,使其更接近真实边界框。

Box Regression/边界框回归的过程使用 L2 正则化,鼓励预测的边界框保持不变。我们也注意到这样的变换其实是有 Scale/Translation 不变性的,因为 CNN 在裁剪之后并不会感受到绝对的尺寸和位置的变化。
R-CNN 的训练:打标签,对每一个区域提议分类为 Postive、Negative 和 Neutral,通过计算和 Ground Truth 的 IoU 阈值为 0.5 和 0.3 进行分类。裁剪区域并缩放到 \(224 \times 224\) 的尺寸,扔进 CNN 提取特征。对于每一个正例预测类型并且回归边界框,对每一个负例仅仅预测类型。
在测试的时候,按照区域提议、CNN 提取特征、运行分类和回归的顺序进行,同时需要确定阈值来确定预测结果。但引申出两个问题:CNN 经常会输出互相覆盖的边界框,同时阈值应该如何确定?
对第一个问题,使用非极大值抑制/Non-Maximum Suppression/NMS 来解决。步骤如下:
- 选择下一个得分最高的边界框;
- 计算当前选择的框和所有未处理框的 IoU,如果 IoU 大于阈值,则删除该框;
- 重复步骤 1 直到没有剩余的边界框。

上图中的橙色框就是第一个删掉的框,因为其和蓝色框重叠太多了。但是在物体高度密集,互相严重遮挡的情况下,NMS 其实会错误的抑制掉了实际检测到不同物体的好框,这个问题到当时(2022 年)还没有很好的解决方案。
我们使用 Mean Average Precision/mAP 来衡量模型的好坏。过程如下:
- 对每一个测试图片运行带 NMS 的目标检测;
- 对每一个类别,计算平均准确率 \(\operatorname*{AP}\),其定义为准确率-召回率曲线下的面积,方法如下
- 按照分数从高到低的顺序,对每一个预测结果,如果其和某一个 Ground Truth 的 IoU 大于 0.5,则认为其是一个正例,否则为负例,计算当前的准确率和召回率;
- 绘制准确率-召回率曲线,计算曲线下的面积,即为 \(\operatorname*{AP}\)。
- 计算所有类别的 \(\operatorname*{AP}\) 的平均值,即为 \(\operatorname*{mAP}\)。
- 对于 COCO \(\operatorname*{mAP}\) 的计算,对多种 IoU 阈值对应的 \(\operatorname*{mAP}\) 求平均。

Lecture 14: Object Detectors¶
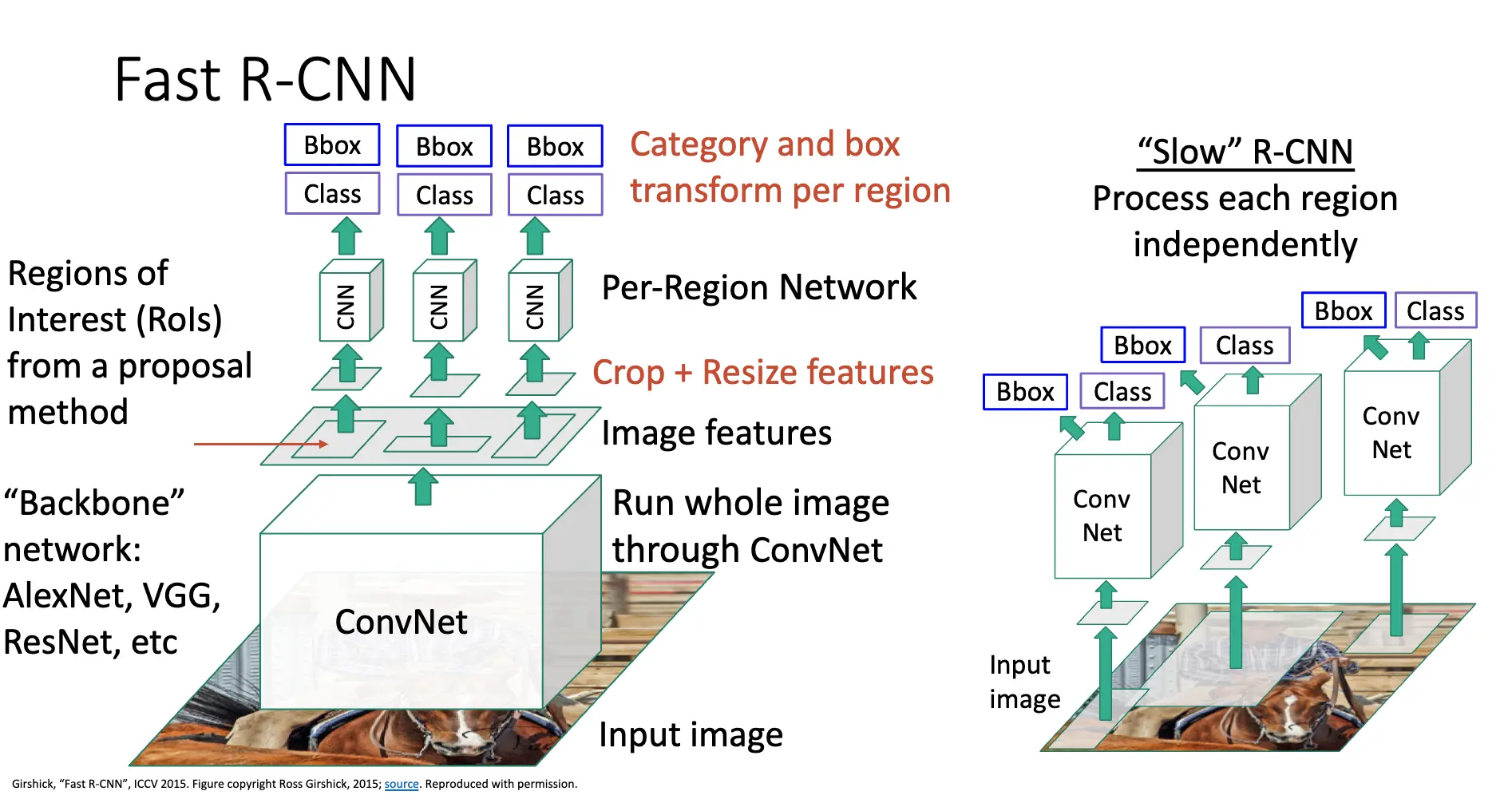
上次讲到原先 R-CNN 的 Overlapping Proposals 引发了很多重复性的工作,一些像素被处理了很多次,我们希望避免这种情况,于是有了 Fast R-CNN:
- Backbone Network/骨干卷积网络:首先将整张图片输入到骨干神经网络中,一般是 VGG 或者 ResNet,得到一个特征图;
- Region Proposal:需要一个外部提议算法,从特征图生成一系列可能包含物体的 RoL;
- 裁剪并且调整大小之后,将图片输入到专门处理信息的 Per-Region Network 之中,对提取到的区域特征进行分类和边界框回归。
其中大部分计算都集中在骨干网络之中,Per-Region Network 多是相对轻量的网络,比如我们如果要基于 AlexNet 做 Fast R-CNN,那么前五层卷积层被使用为骨干网络,后两层全连接层被使用为 Per-Region Network。Fast R-CNN 和 Slow R-CNN 的架构比较如下:
对于对 RoI 的裁剪和缩放,我们起码应该将特征图上不同大小的 RoI 缩放到相同的大小。先回忆感受野的概念,注意到对于输出的图片的每一个点,其都和输入图片的感受野的某一个点有着一定的对应关系,于是我们可以建立起输入坐标系统和输出坐标系统之间的对应关系,来将特征图中的 RoI 反过来对应输入图片的边界框:

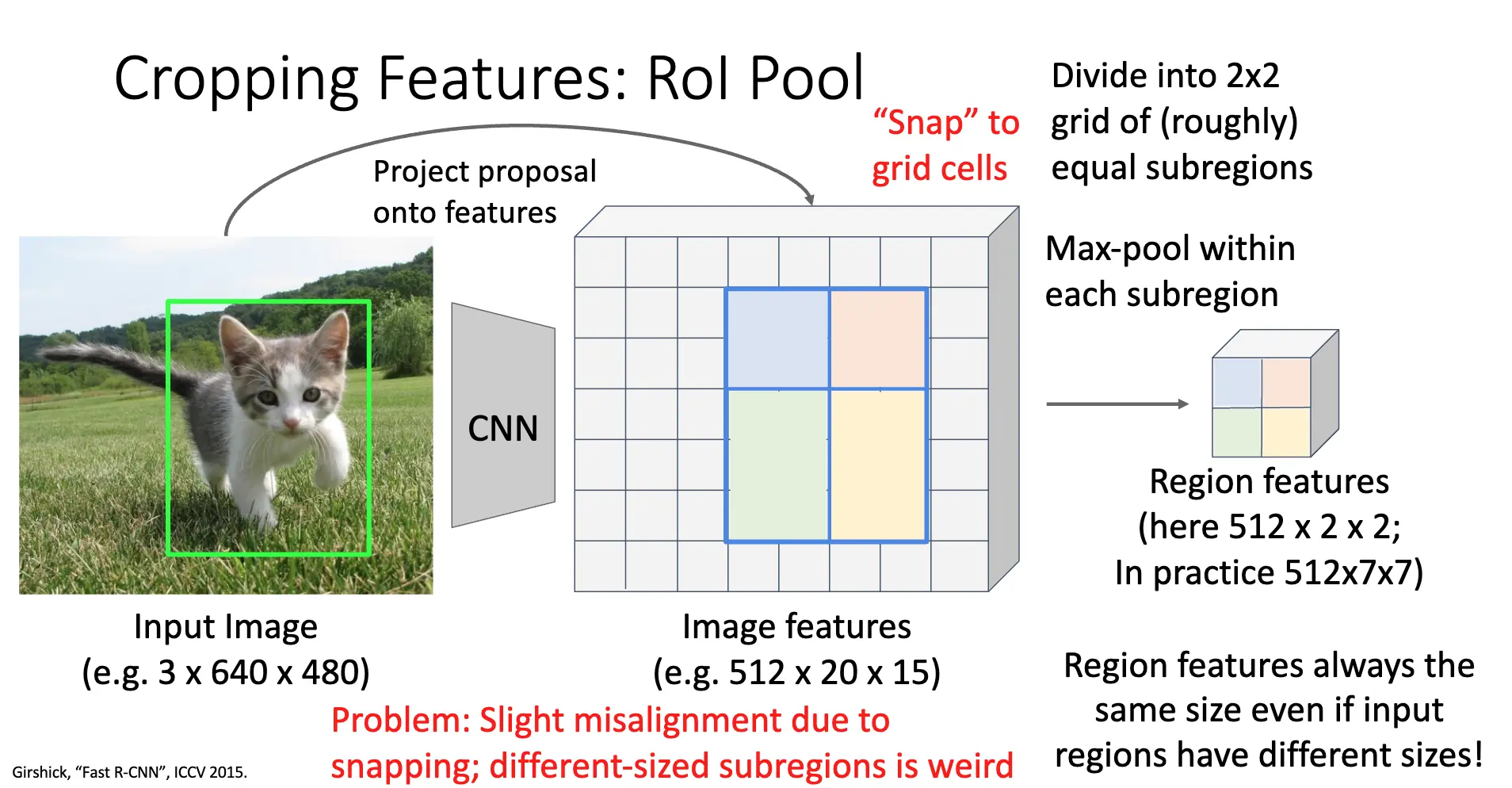
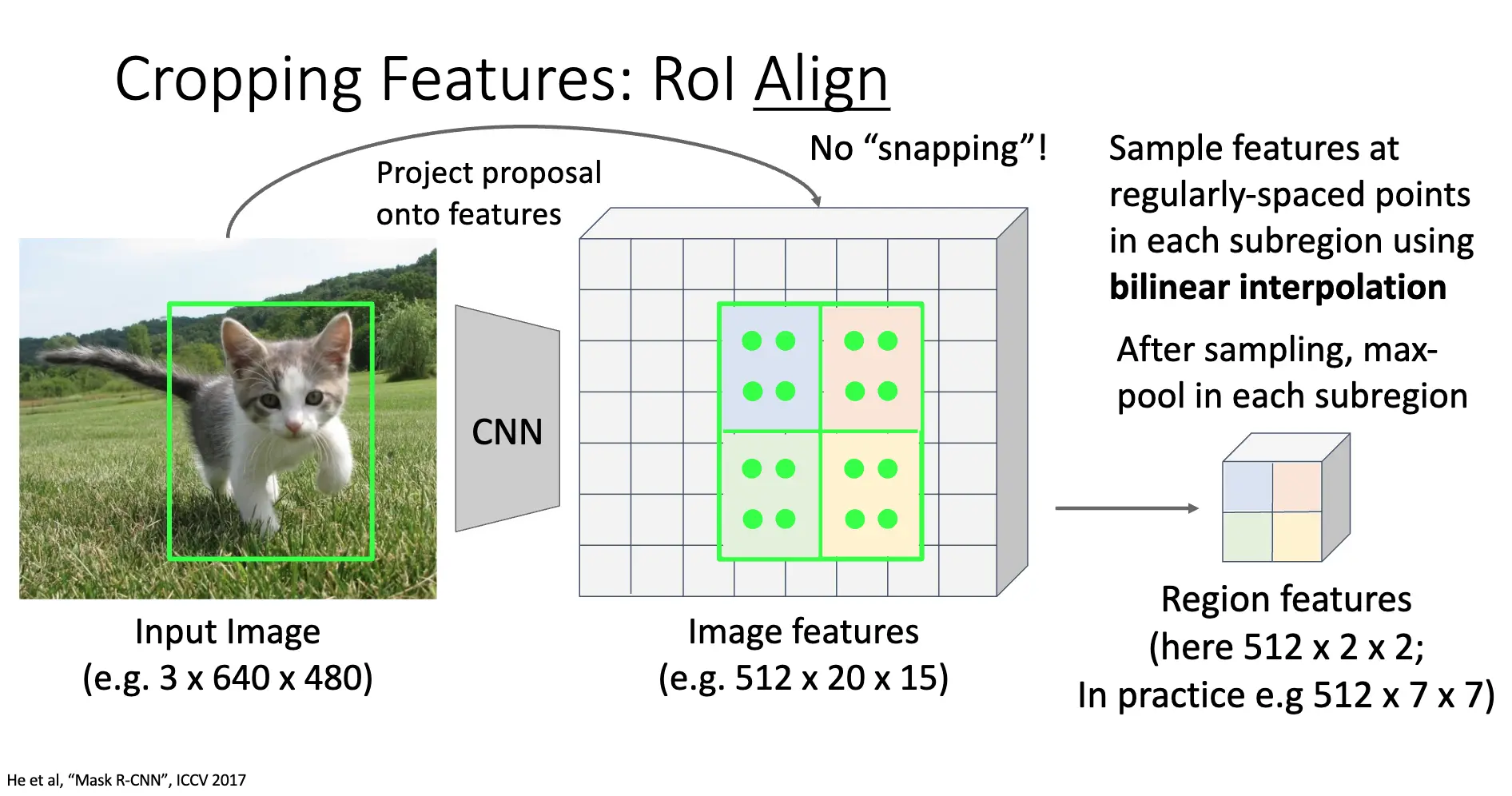
处理特征图的方法是 RoI Pool 和 RoI Align,两个方法是相辅相成的:
- RoI Pool:首先,输入图像的 RoI 经过骨干 CNN 网络得到特征图,对应的特征图上的 RoL,值得注意的是,这个 RoI 的坐标很可能是浮点数,那么先将其量化为整数/Snap to Grid Cells。如果我们需要一个 \(2 \times 2\) 的特征图,那么我们将其大致划分为四个大小相等的子区域,然后对每一个子区域进行最大池化/Max Pooling,得到四个值,然后将其拼接成一个 \(2 \times 2\) 的特征图。
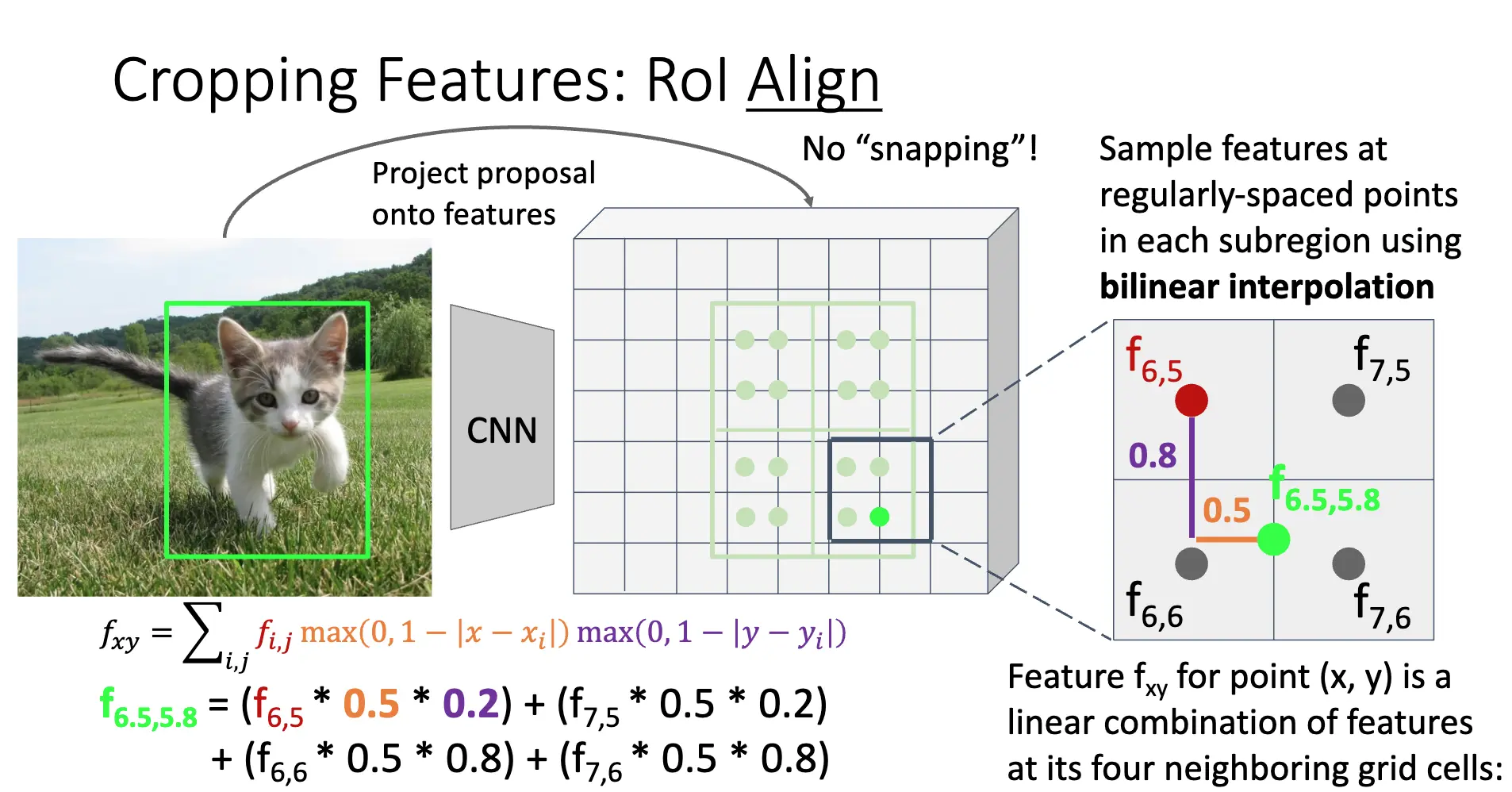
- RoI Align:RoL Pool 的问题在于 Snap to Grid Cells 的量化操作会引起错位/Misalignment,并且不同大小的子区域很奇怪,这俩操作会引起提取的特征和与原始的 RoI 的精确位置之间产生偏差,失去精确的空间信息。RoL Align 的方法是直接计算输入图片的 RoI 在特征图上的精确坐标,分成固定数量的、大小完全相等的子区域;再在子区域内进行按照固定数量规则的采样,对采样点使用双线性插值/Bilinear Interpolation 得到特征值,对每一个子区域的特征值进行最大池化/Max Pooling,得到最终的特征值。
Fast R-CNN 的方法非常美妙,训练时长减少到了 Slow R-CNN 的十分之一,测试时间甚至到了二十分之一的量级,但是还不够美妙:一个数据是 Fast R-CNN 的测试时间为 2.3 秒,但是除了 Region Proposal 的时间只有 0.32 秒,运行时间受到了 Region Proposal 的限制。问题很直接:Region Proposal 是跑在 CPU 上的,没有充分并行化。当然,将其实现为神经网络的一个组件,使用 GPU 加速,可以显著提升速度。
我们这里研究在 NIPS'2015 发表的 Faster R-CNN,在网络中插入了 Region Proposal Network/RPN,直接将骨干 CNN 输出的特征图作为输入,预测出区域提议。这样,区域提议步骤就变得可学习得了,并且可以在 GPU 上高效运行了。
首先,特征图上的每一个点都对应着输入图像的一个空间位置,这实际上对应着一个感受野的中心。对特征图上的每一个空间位置可以引入锚框/Anchor Box,这是一组具有不同尺寸的宽高比的边界框,其中心位置都对齐到原图上的一个点。RPN 的第一个任务是对每一个锚框进行二分类,判断其是否包含物体,这部分使用一个卷积层,在这里是 512 个输入通道,2 个输出通道,输出维度为 \(2K \times 5 \times 6\),其中 \(K\) 是每一个特征图的点上的锚框数量。
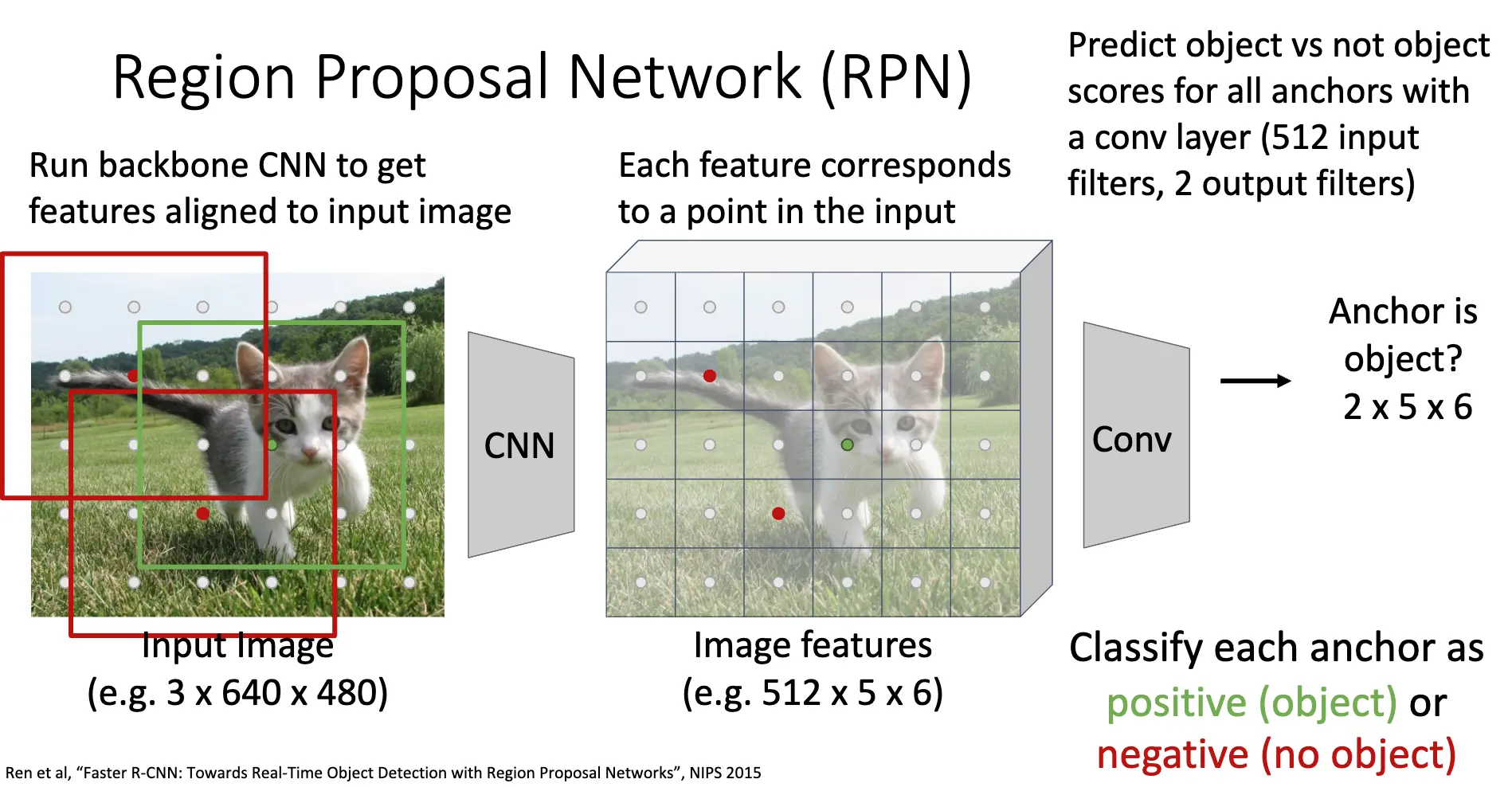
在训练过程中,还将锚框和 Ground Truth 的 IoU 作为监督信号,来训练 RPN 的参数,只有正例才会计入边界框回归的损失函数。
因此我们在训练的时候需要对下面四个损失进行训练:
- RPN classification:区分锚框是物体还是背景;
- RPN regression:学习将正样本锚框调整到更接近 Ground Truth 的边界框(可以看 Lecture 13 的边界框回归);
- Object classification:RPN 提出的区域提议进行具体的物体类别分类;
- Object regression:进一步微调 RPN 提出的区域提议的边界框,使其更精确/predict transform from proposal box to object box。
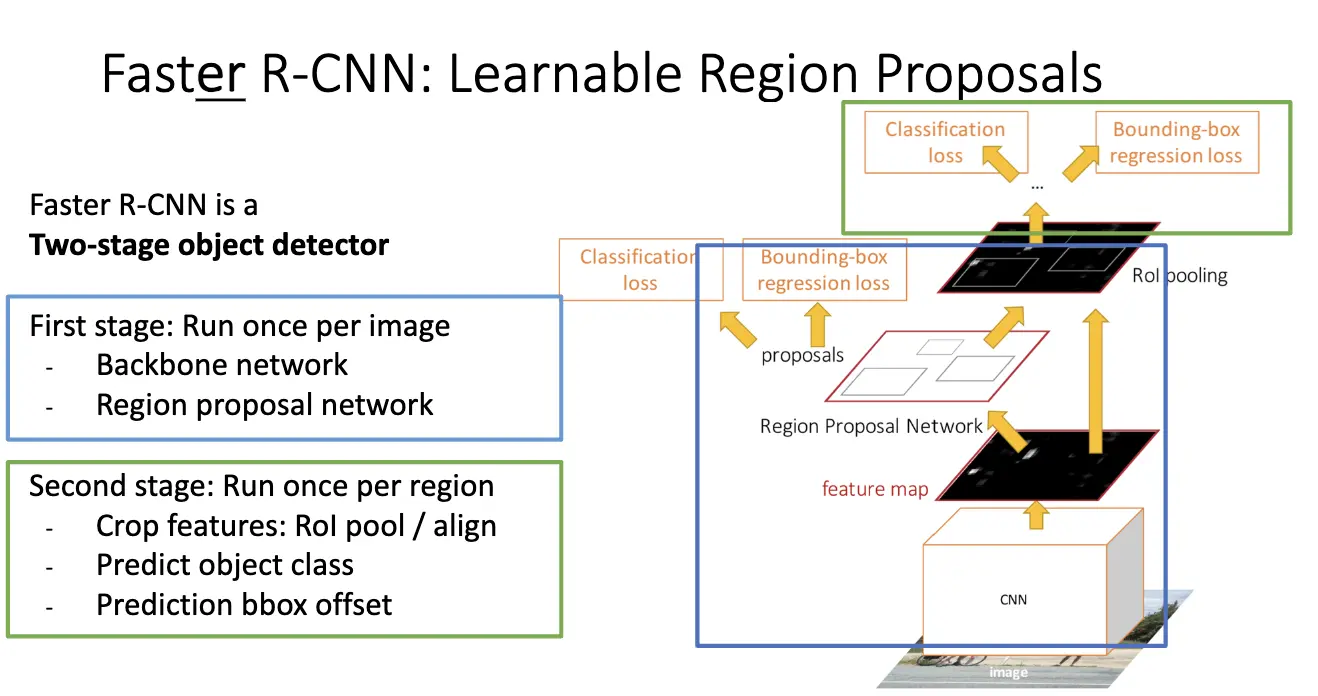
Faster R-CNN 是一个两阶段的检测器,第一阶段是运行骨干网络和 RPN,生成候选区域提议,第二部分是对这些提议区域,使用 RoI Pooling/RoI Align 提取特征,然后进行分类和回归。
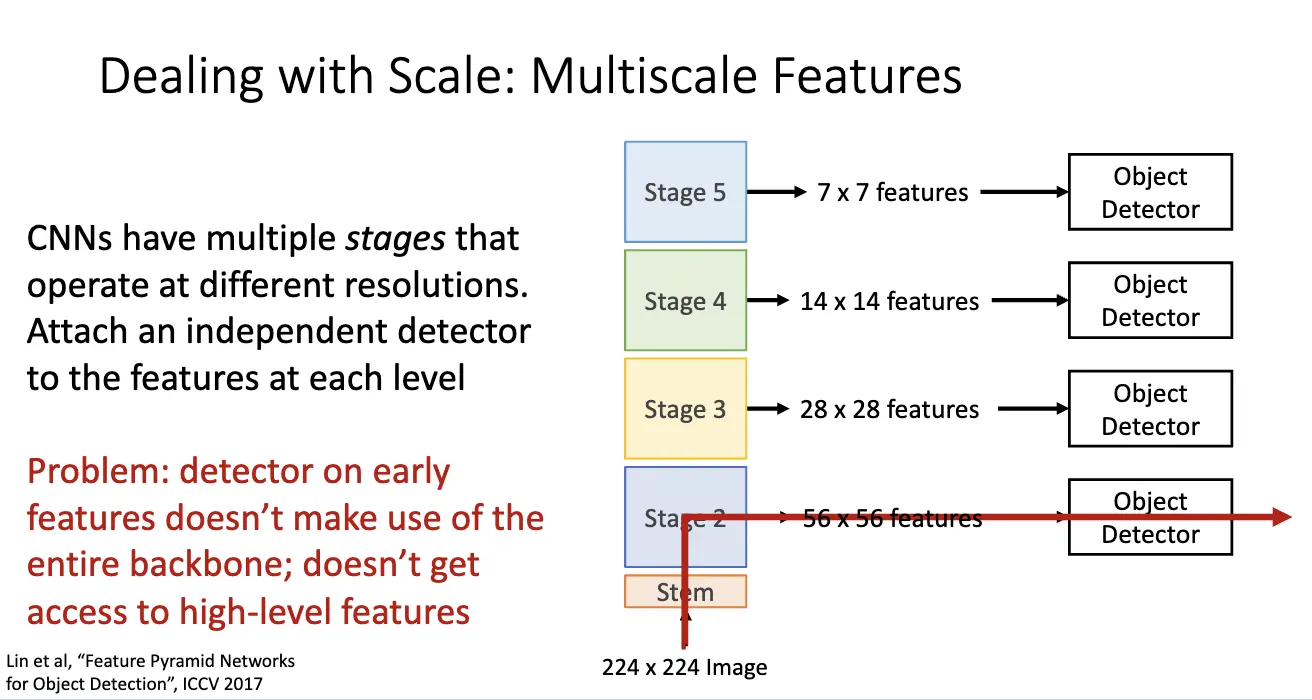
问题:现实场景中物体具有多种尺寸,因此需要要求让目标检测器具有尺度不变性。解决方法之一是图像金字塔/Image Pyramid。这是个经典的想法,方法是将图片缩放到不同的尺寸,然后分别进行目标检测,最后将结果融合起来。问题是过于昂贵,在不同尺度上并不共享任何计算。

另一个方法是利用 CNN 固有的多尺度特征,现代 CNN 本身就包含多个阶段,每一个阶段输出不同分辨率的特征图,因此可以利用这一点,在不同层级的特征图上附加一个独立的检测器,不同层级的检测器负责检测不同尺度的物体。问题在于早期层级的特征图上缺乏高层语义信息,虽然其分辨率高,细节丰富,但是语义信息不足。
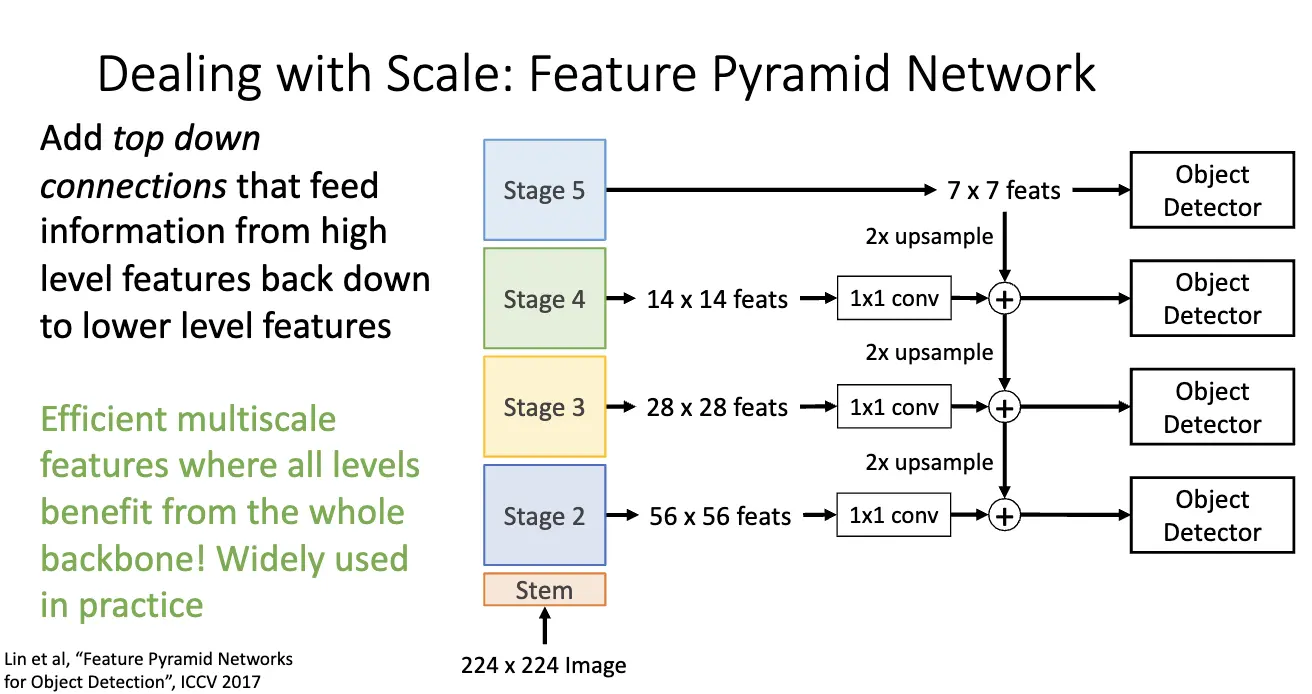
解决方法是特征金字塔网络/Feature Pyramid Network/FPN,方法是 Add Top Down Connection/从上往下通过上采样/Upsample 在保持高分辨率的同时增加语义信息,再将其和当前层级的语义进行融合。这就很棒了,因为其具有高效的多尺度特征表示,使得所有层级都可以享受整个网络的语义信息。
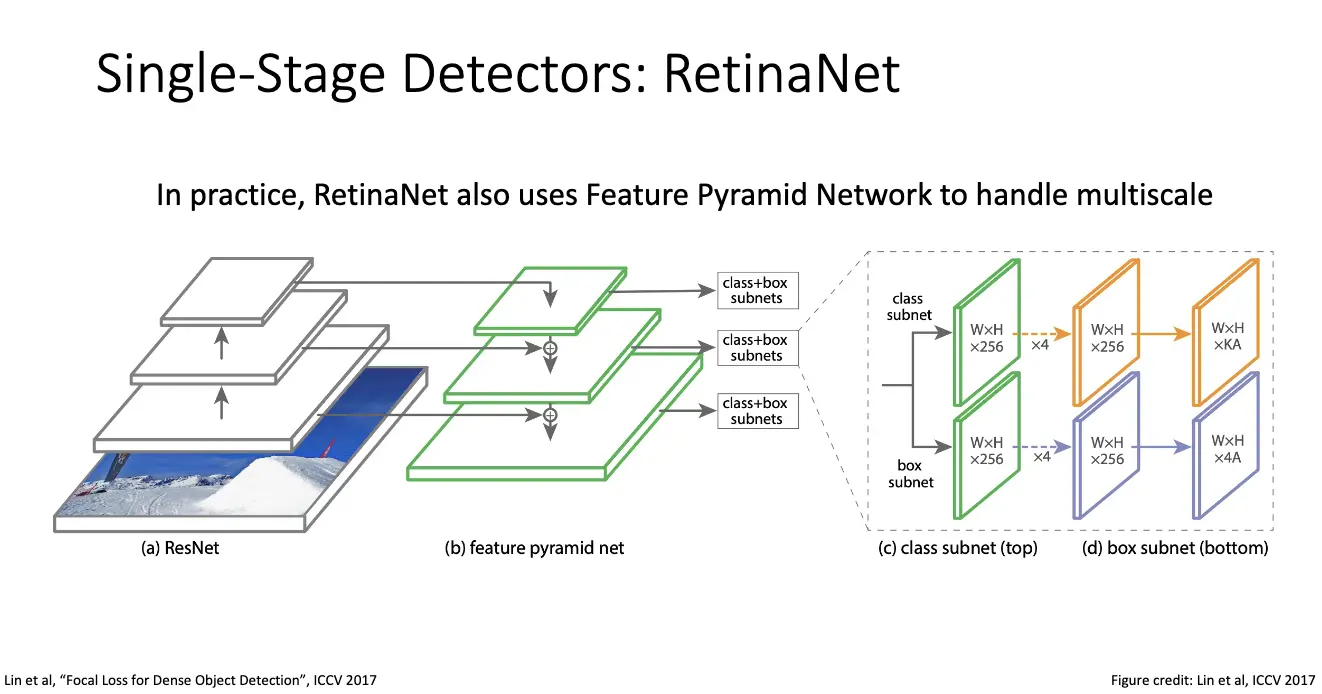
另一个问题就是:我们真的需要 Faster R-CNN 的第二阶段吗?单阶段检测器/Single-Stage Detectors 中的 RetinaNet 和 FCOS 就是很好的例子。
RetinaNet 和两阶段检测器的先提议再分类/回归不同,单阶段检测器和 RPN 类似,但是与分类为是不是物体相反,RetinaNet 是直接在骨干网络输出的密集特征图上直接预测物体类别和边界框。假设我们有 \(C\) 个类别,之前的还是不变,那么锚框的分类数就有 \(2K \times (C + 1) \times 5 \times 6\) 个,锚框的回归数就有 \(4K \times 5 \times 6\) 个。

但是单阶段检测器面临着一个主要问题是:极端的类别不平衡/Class Imbalance,绝大多数锚框都是背景,只有极少数物品属于前景。解决方法是使用新的损失函数,Focal Loss,让训练过程聚焦于难以分类的样本。详情见论文。同样,RetinaNet 也使用 FPN。
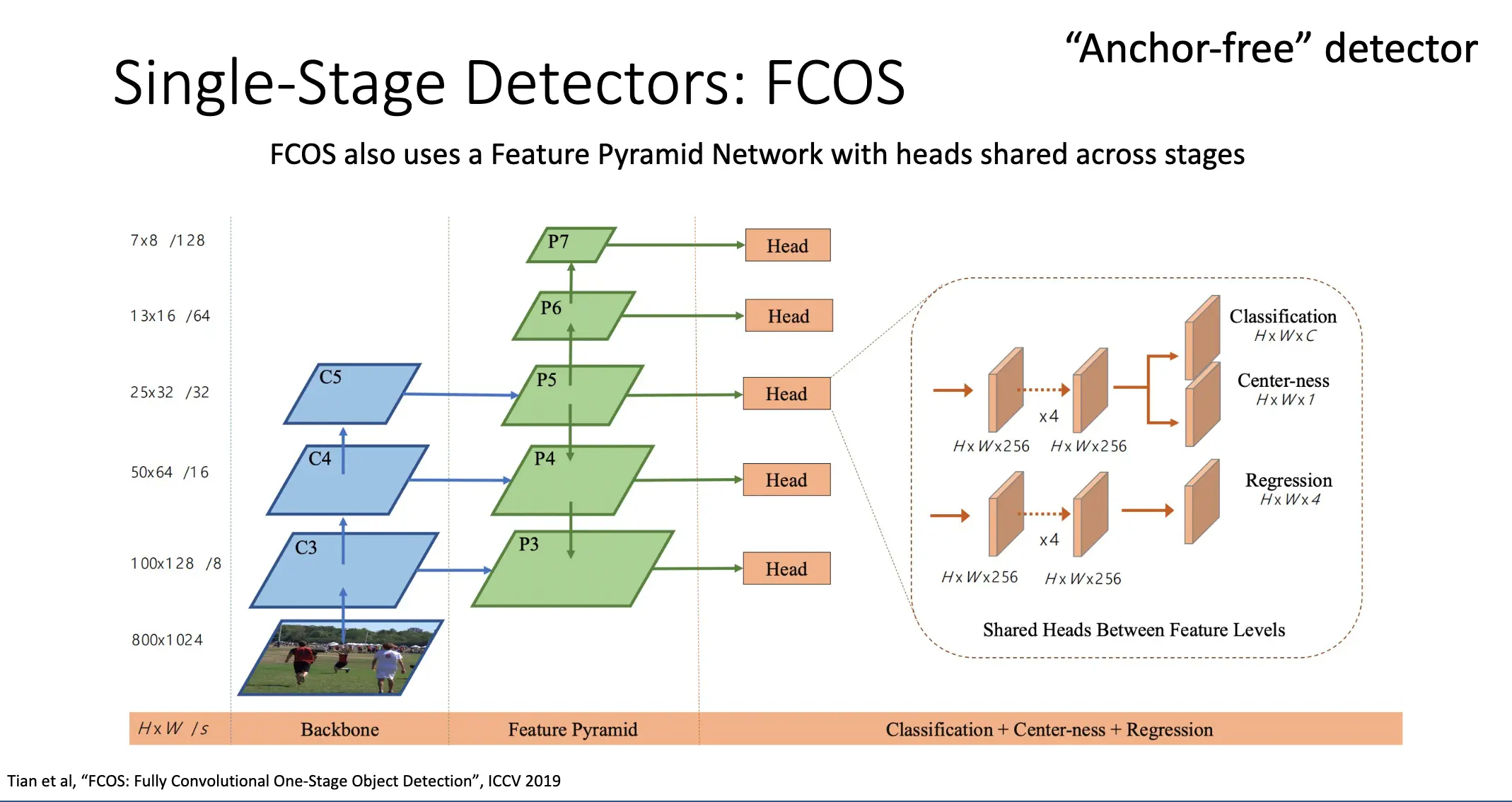
FCOS 是一种不基于锚框的检测器。方法是直接将特征图上的每一个点分类为正样本或者负样本,如果其落在某一个物体的真实边界框内部,那么就认为其是正样本,否则为负样本。也训练一个独立的类别分类器,来预测每一个点对每一个类别的分数。
对于正样本,使用 L2 损失回归其到真实边界框的四个边界的距离,输出维度为 4。同时使用 Centerness/中心度分数,衡量其距离其负责的物体的中心有多远。

Lecture 15: Image Segmentation¶
语义分割:将每一个像素分类为不同的类别,不区分物体实例,只关心像素。
古老/Naive 的想法是使用滑动窗口,但是效率非常低,不能在相互覆盖的小块间复用特征。现代的方法是使用全卷积网络/Fully Convolutional Network/FCN 以及 argmax:
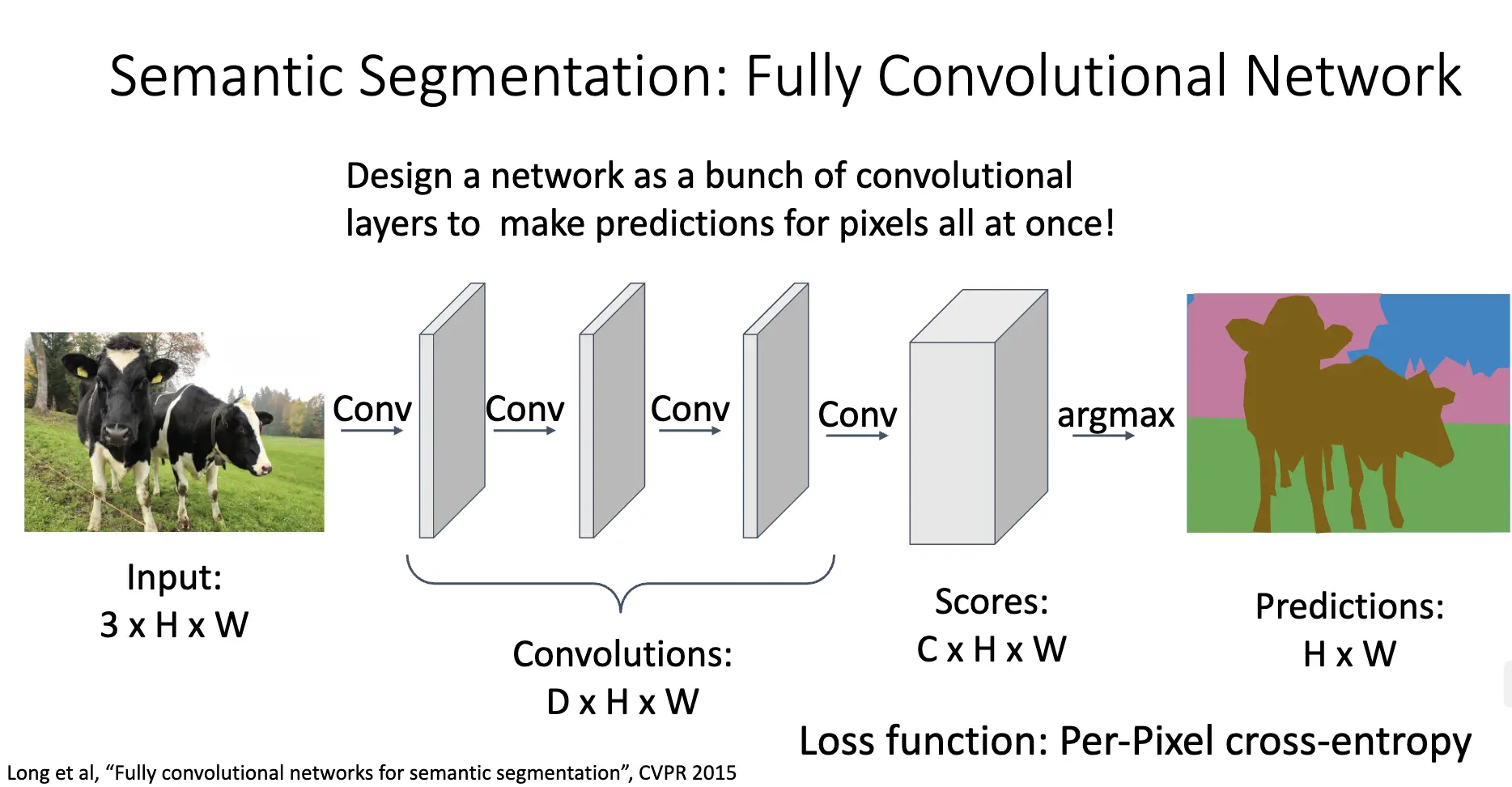
但是会出现两个问题:
- 一个是有效感受野的大小会随着卷积层数的增加线性增长,会导致分辨率下降,分割结果会变得模糊;
- 另一个问题就是对高分辨率的卷积其实非常昂贵,经典的网络(比如 ResNet)积极的进行下采样。
解决方法之一是先进行下采样再进行上采样/Upsampling,问题此时变成了:既然我们可以通过池化和带步长的卷积来下采样,那么上采样应该怎么做?

反池化/Unpooling:将每一个小块池化后的值赋给这个小块内的每一个值:
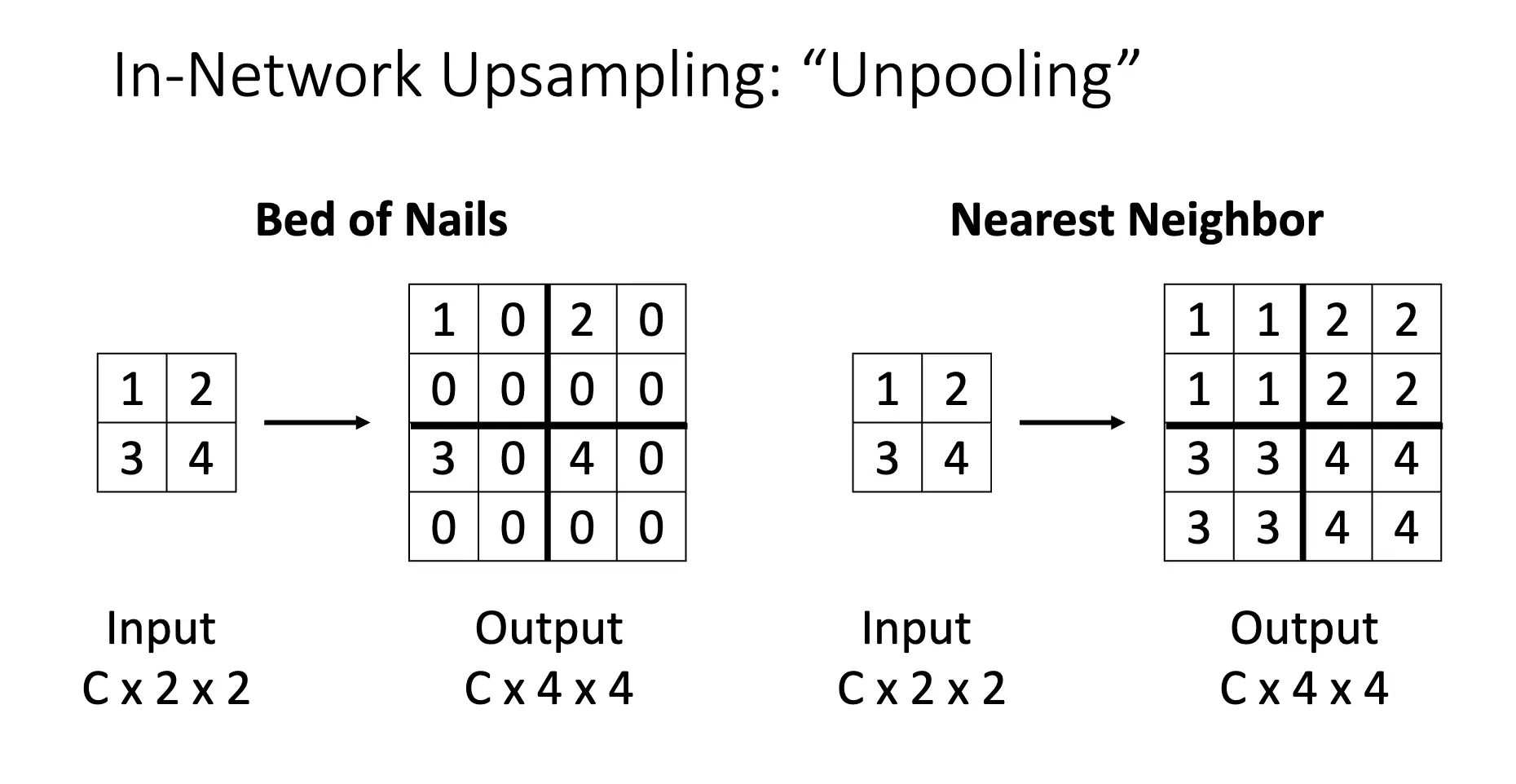
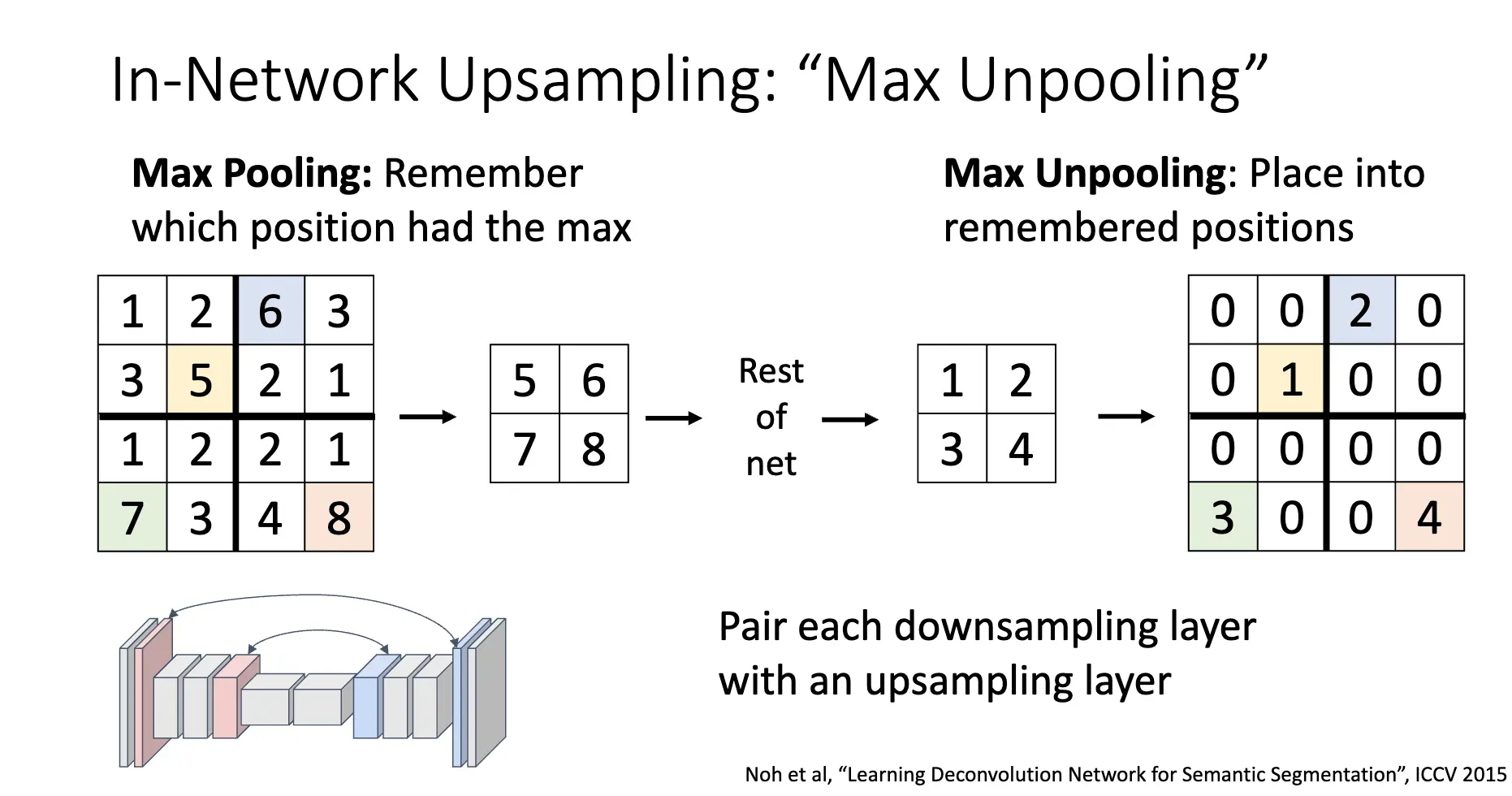
也有一种方法是在最大池化的时候记住最大值的位置,再在上采样的时候将最大值的位置填回去:
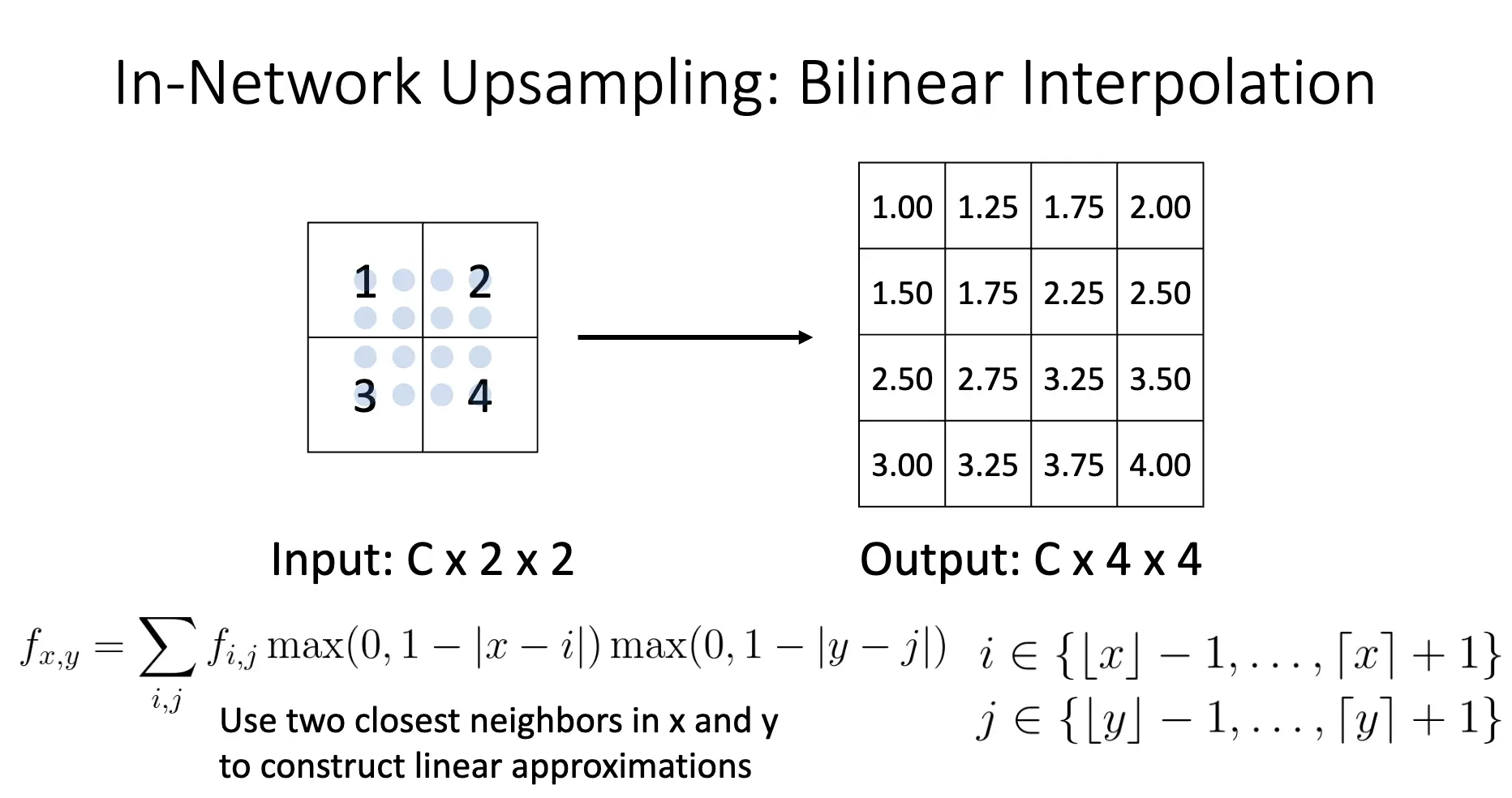
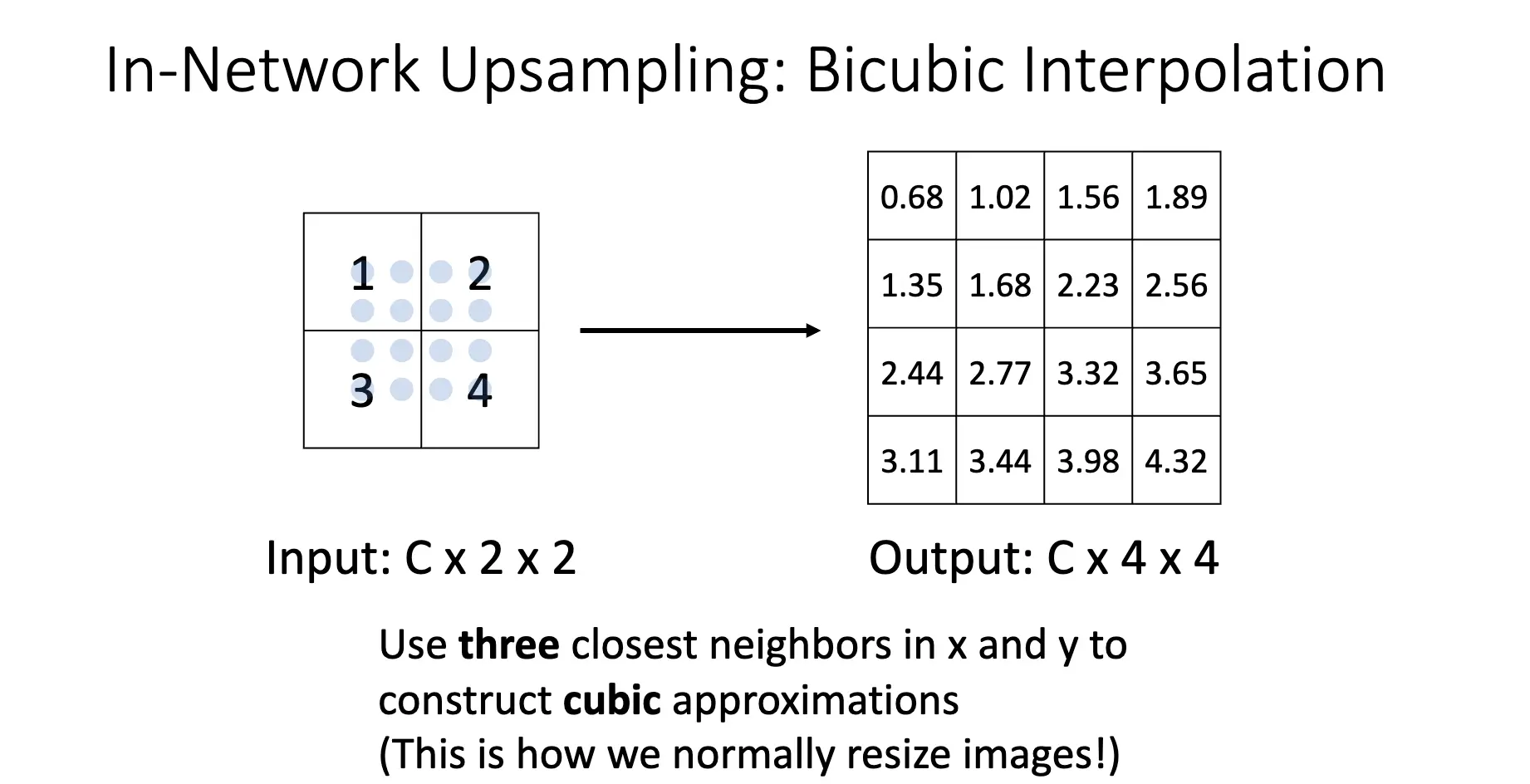
同理还有双线性插值/Bilinear Interpolation 以及双三次插值/Bicubic Interpolation:
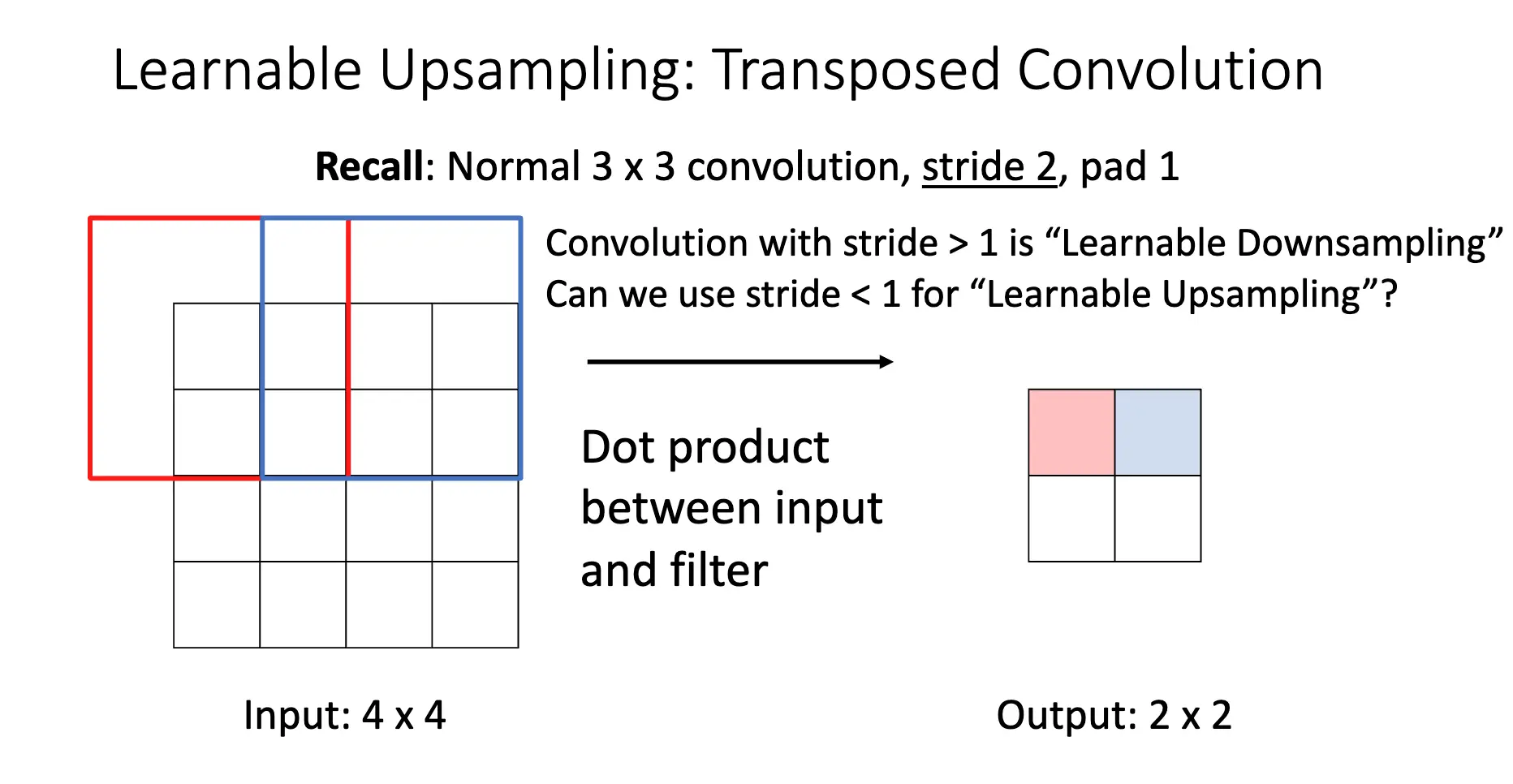
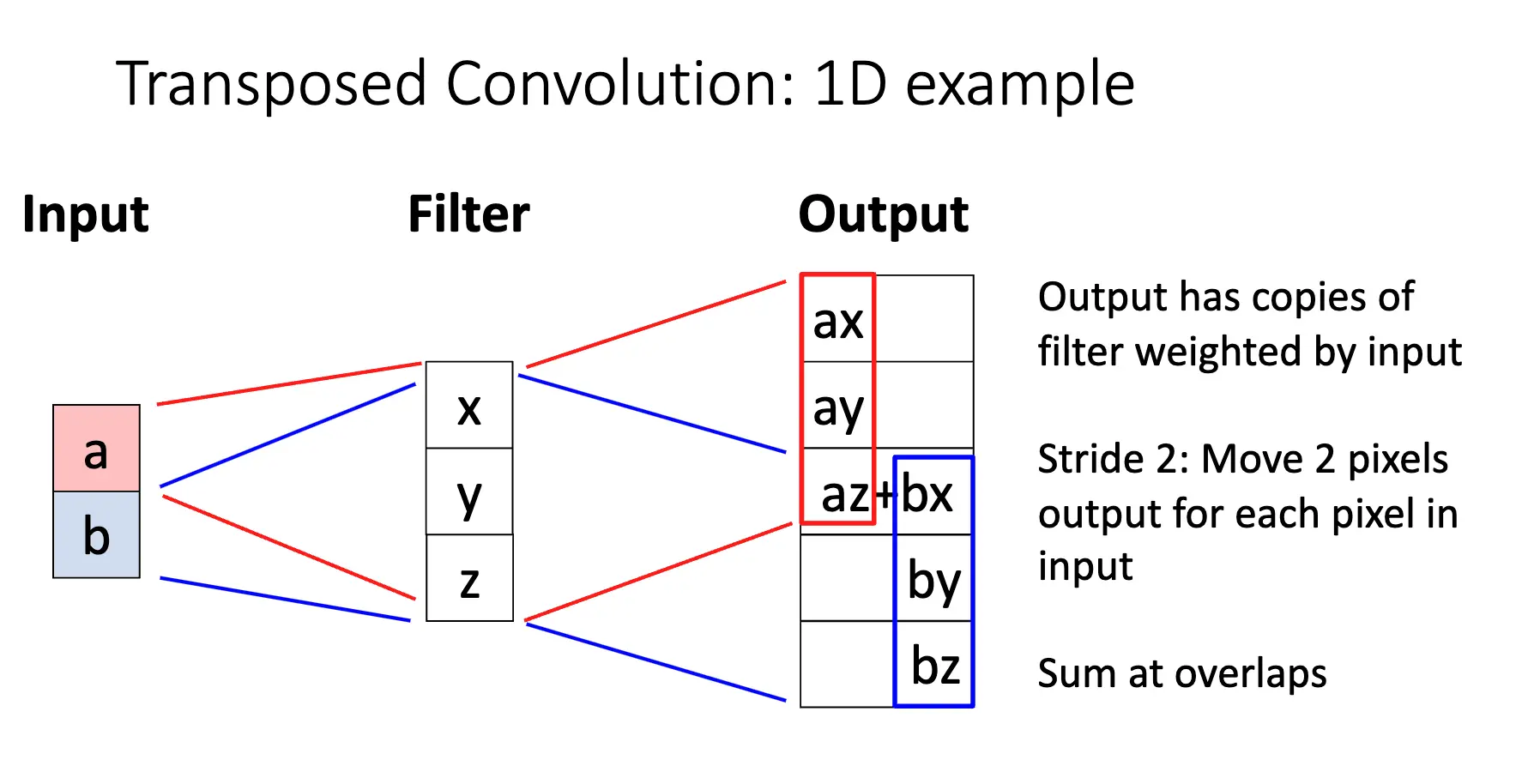
Transposed Convolution/反卷积/转置卷积是一种可学习的上采样方法,其本质是卷积层的转置:

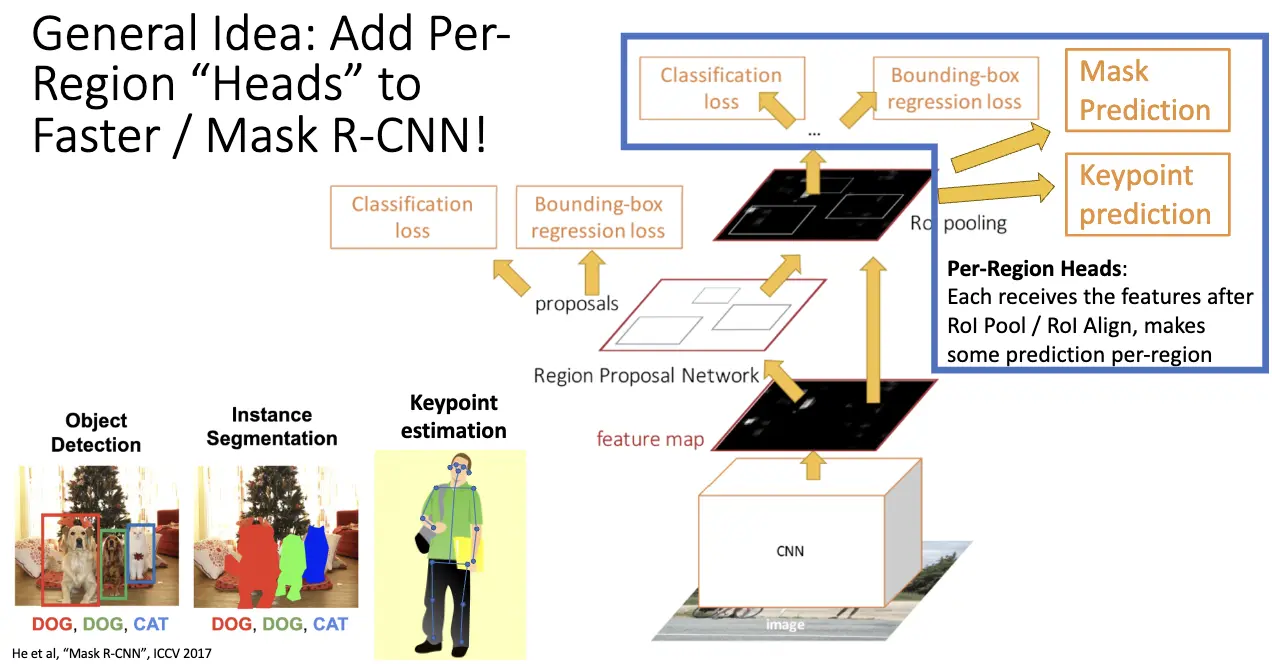
回顾计算机视觉的任务:分类、语义分割、目标检测、实例分割。语义分割会将相邻的同类实例合并在一起,并且不区分 Things 和 Stuff,目标检测检测目标实例,区分 Things 和 Stuff,但是只给出框框。实例分割会检测出图片中的所有物体,将 Things 的每一个像素鉴定出属于哪一个物体。方法是执行目标检测,然后预测出一个 Segmentation Mask。
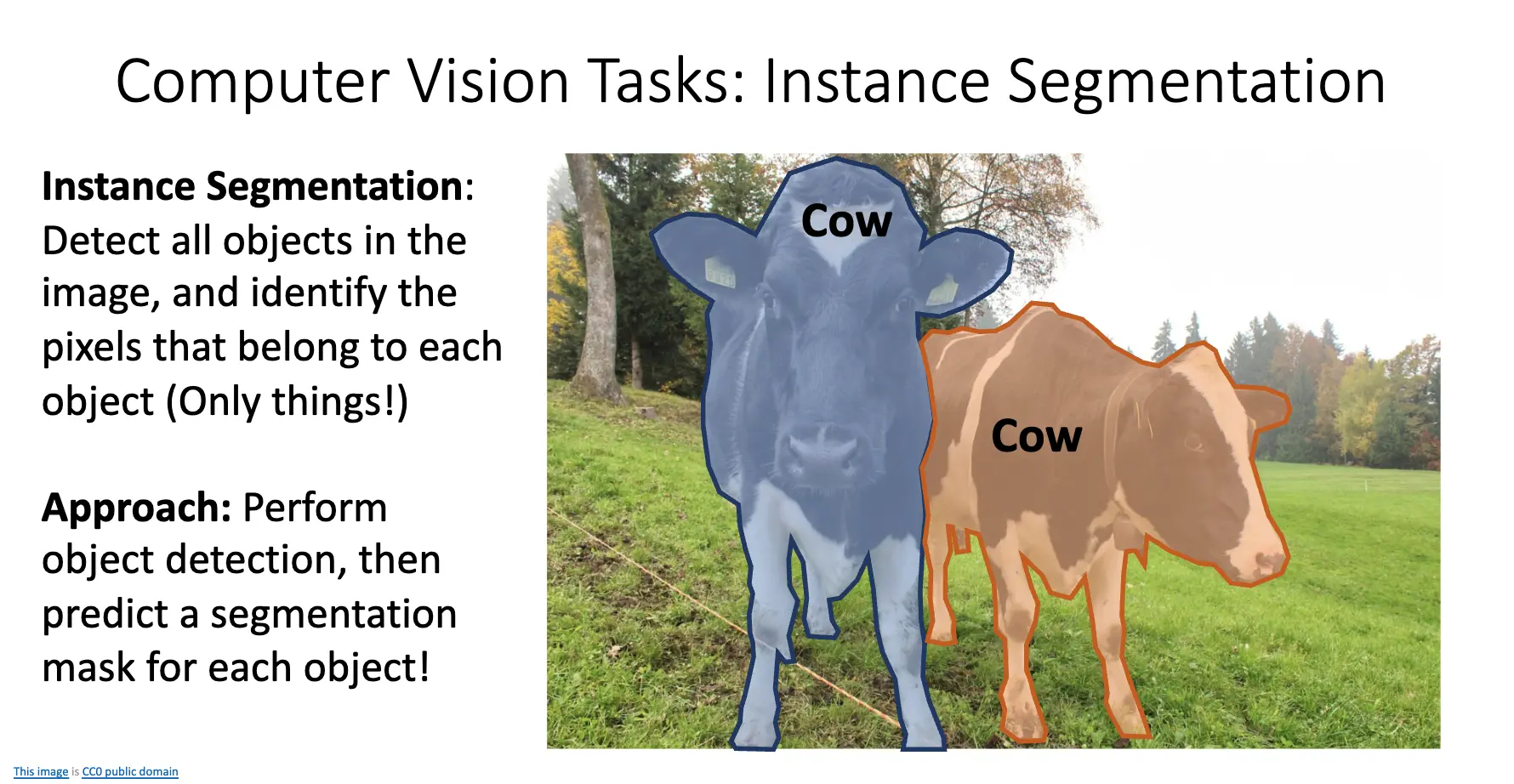
对应地,我们实现了 Mask R-CNN,其在 Faster R-CNN 的基础上,添加了一个 Mask Prediction 分支,来预测每一个 RoI 的二值掩码。
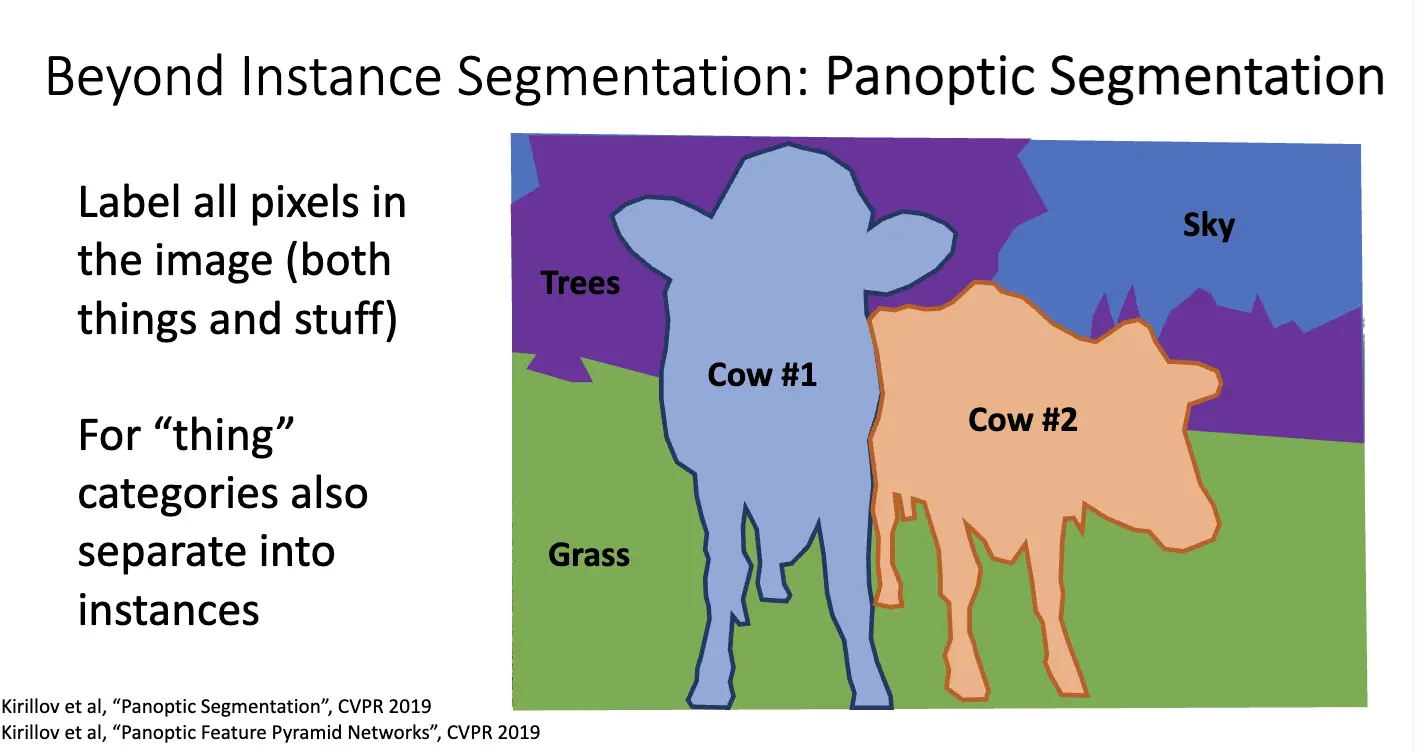
比实例分割更丰富的任务是全景分割/Panoptic Segmentation,其旨在统一实例分割和语义分割,目标是为图像中的每一个像素分配一个语义标签,同时区分不同的物体实例。
另一个任务是 Human Keypoint Detection/人体关键点检测,也称为 Pose Estimation/姿态估计,目标是通过定位一组关键点来描述人体姿态。

对神经网络的想法也不复杂,在 Mask R-CNN 的基础上加一个关键点预测分支即可。
更一般的想法是在 Faster/Mask R-CNN 上加入 Per-Region Heads,其在 RoI Pool 和 RoI Align 之后接收特征并且做出预测。我们通过修改任务头来扩展功能,比如 Dense Captioning/密集字幕,其目标是预测图像中所有可能的物体实例的密集描述;3D Shape Prediction/3D 形状预测,其目标是预测图像中物体的 3D 形状……等等。