Thread Level Parallelism¶
约 1616 个字 25 张图片 预计阅读时间 5 分钟
Outline
高僧预测
重点在缓存一致性,细节来讲在监听协议和 MSI 协议。存储器一致性不重要。





Flynn 分类法
1. 多处理器体系结构¶
由于利用指令级并行的收益越来越少,单处理器的性能增长逐渐放缓,在新的时代背景下,多处理器在从低端到高端的各个领域都扮演了重要的角色。本章主要研究线程级并行的利用。
线程级并行和指令集并行的重要区别是:线程级并行由软件系统或者程序员在较高层级上确认,并行执行的是包含大量指令的线程。TLP 意味着需要同时执行多个独立的线程,每一个线程都具有自己的程序计数器追踪执行位置,主要通过 MIMD 利用。
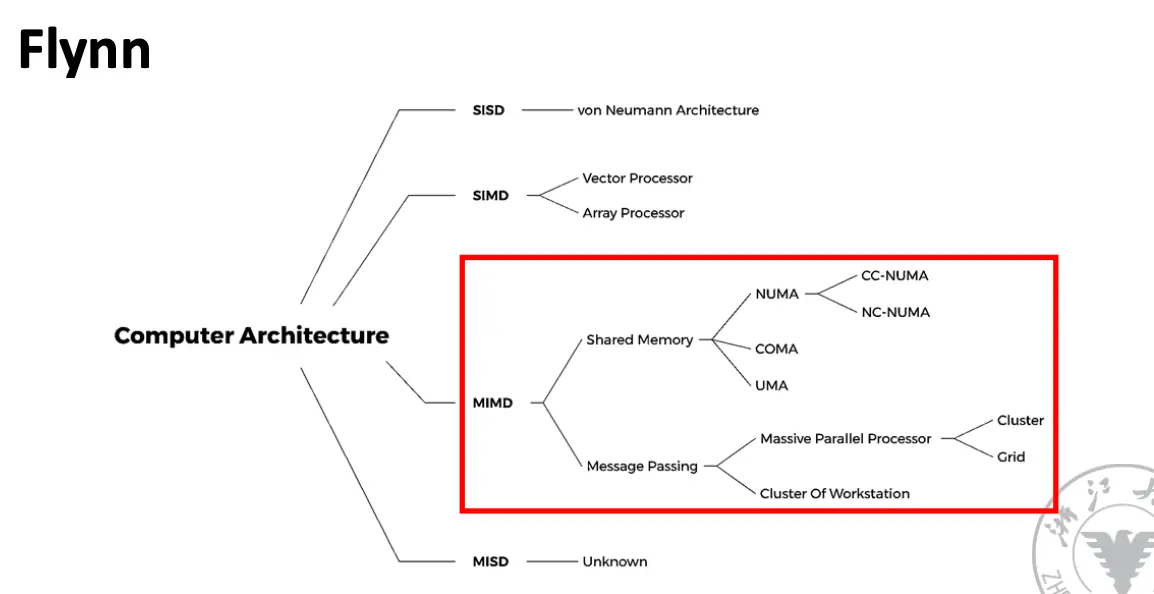
MIMD 架构主要分为两大类:
- Multiprocessor System/多处理器系统,其基于共享地址空间:
- 整个系统只存在一个地址空间,所有的处理器都共享这个地址空间;
- 但是只有一个地址空间并不意味着只有一个物理内存,实际上可以通过一块物理共享的内存实现,也可以通过分布式的内存实现。
- Multicomputer System/多计算机系统,其基于消息传递/Message Passing:
- 每一个处理器都有自己的局部内存/Local Memory 或者叫私有内存/Private Memory,其只可以被这个处理器访问,不能被别的处理器直接访问;
- 因此,处理器之间的通信必须通过显式地发送和接收消息来完成。
1.1 MIMD 多处理器架构¶
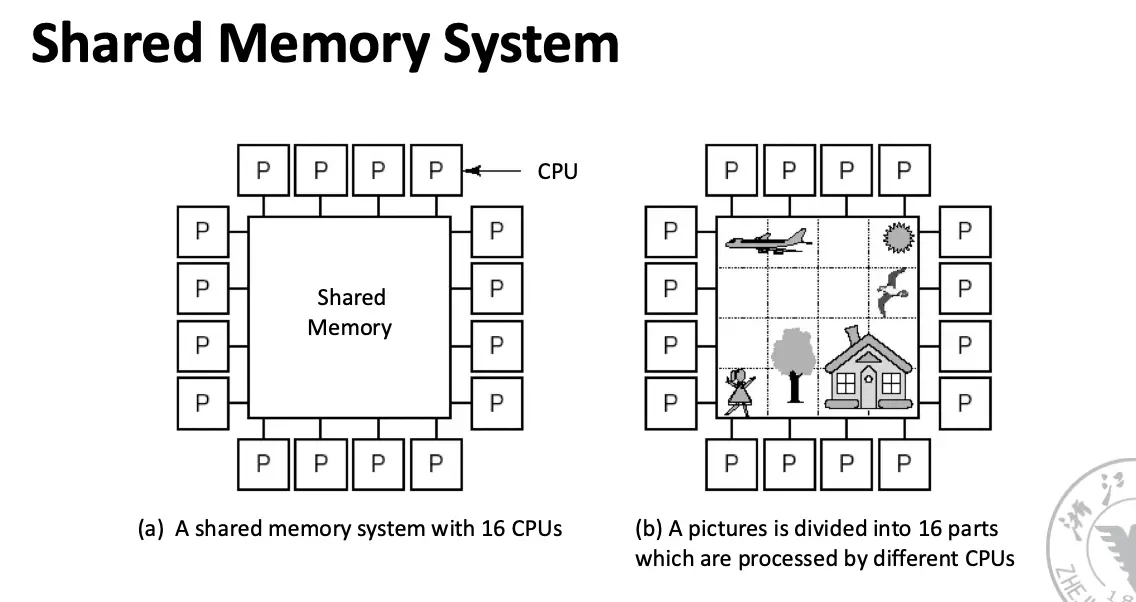
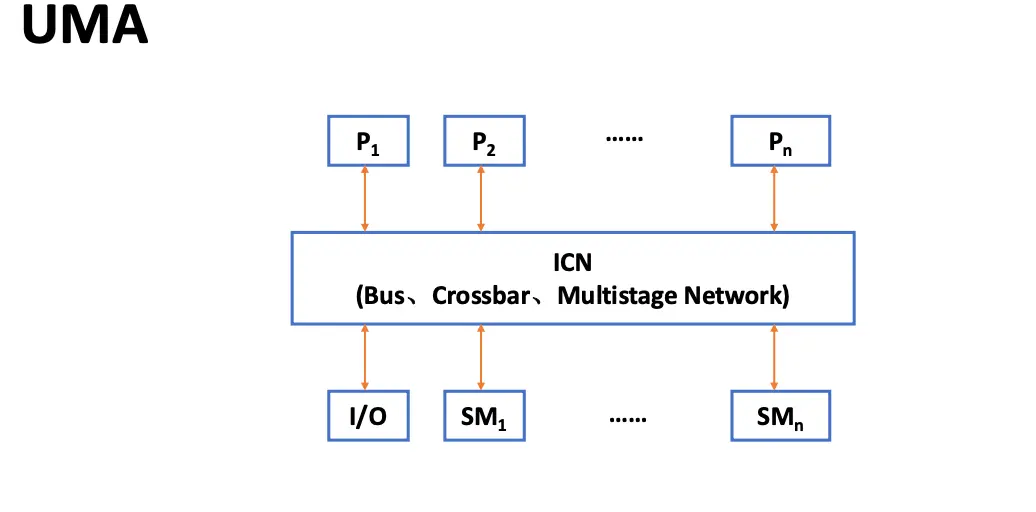
根据所包含的处理器数量,可以将现有共享存储器的多处理器分为两类,而处理器的数量又决定了存储器的组织方式和互联策略,因此我们按照存储器的组织方式来称呼多处理器:
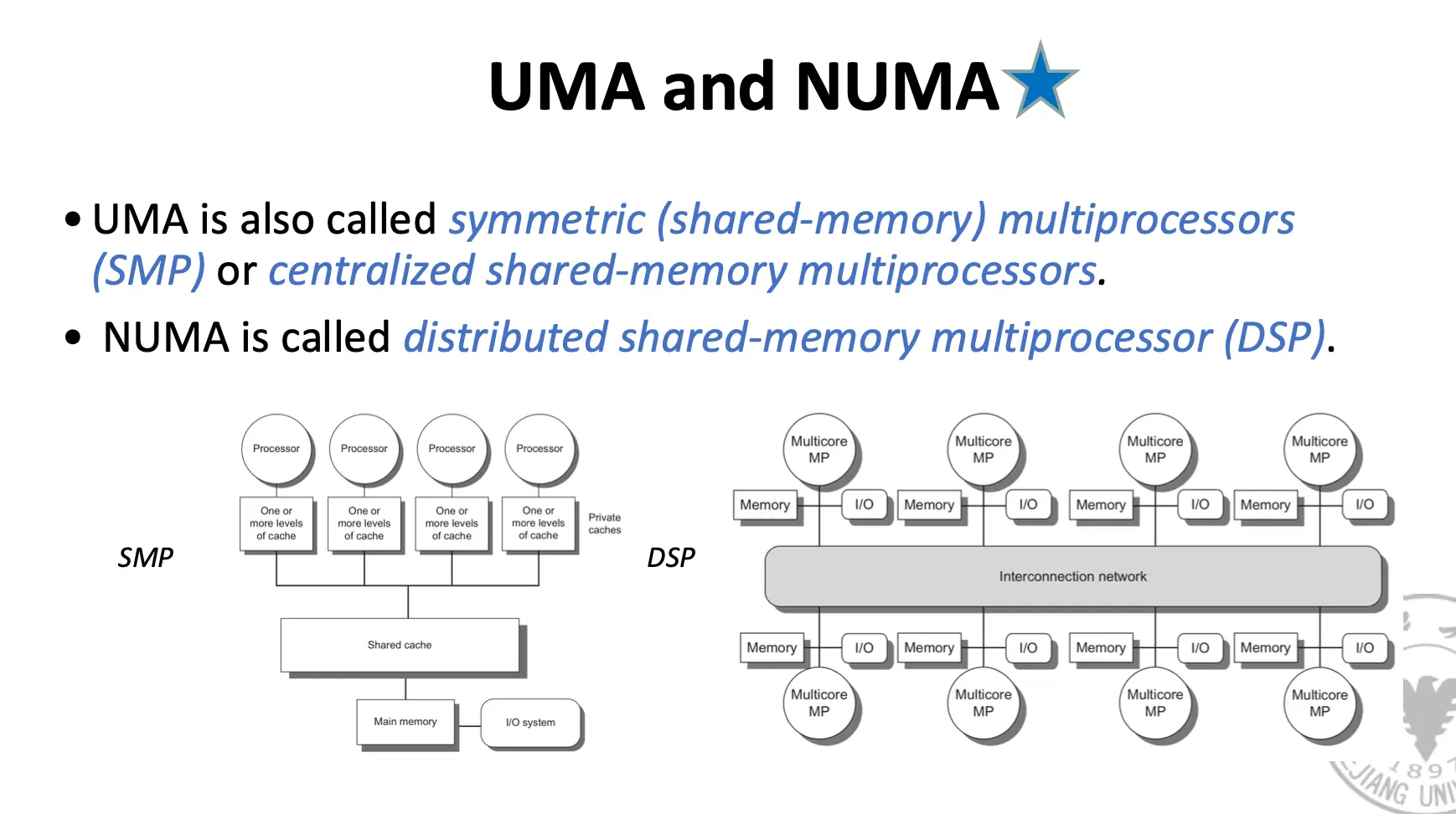
- 对称多处理器/Symmetric Multiprocessor/SMP:也称为集中式共享存储器多处理器/Centralized Shared-Memory Multiprocessor
- 核心数量较少,一般不超过 32 个,因此处理器可以共享一个集中式存储并且平等访问之,这就是对称一词的来源;
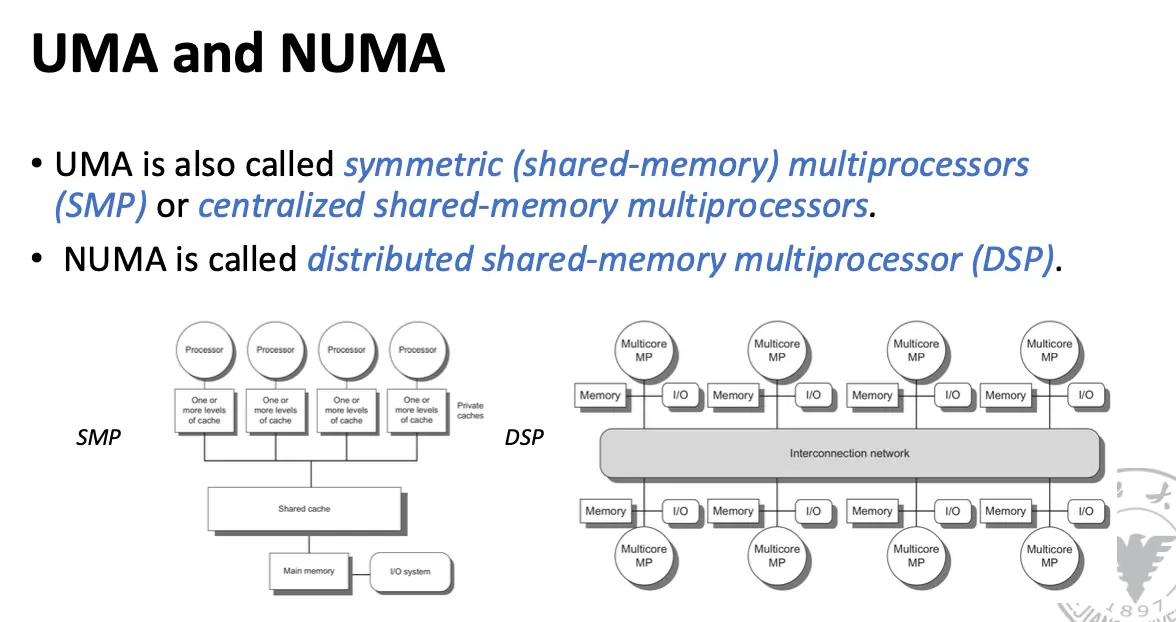
- SMP 体系结构有时也称为一致存储器访问/Uniform Memory Access/UMA 多处理器,这是因为所有处理器访问存储器的延迟都是一致的,即使存储器被分为多个组的时候也是如此;
- 某些多核处理器对最外层高速缓存的访问是非均匀的,这种结构被称为非均匀高速缓存访问/Nonuniform Cache Access/NUCA,因此即便它们拥有单一主内存,也并非真正的 SMP;
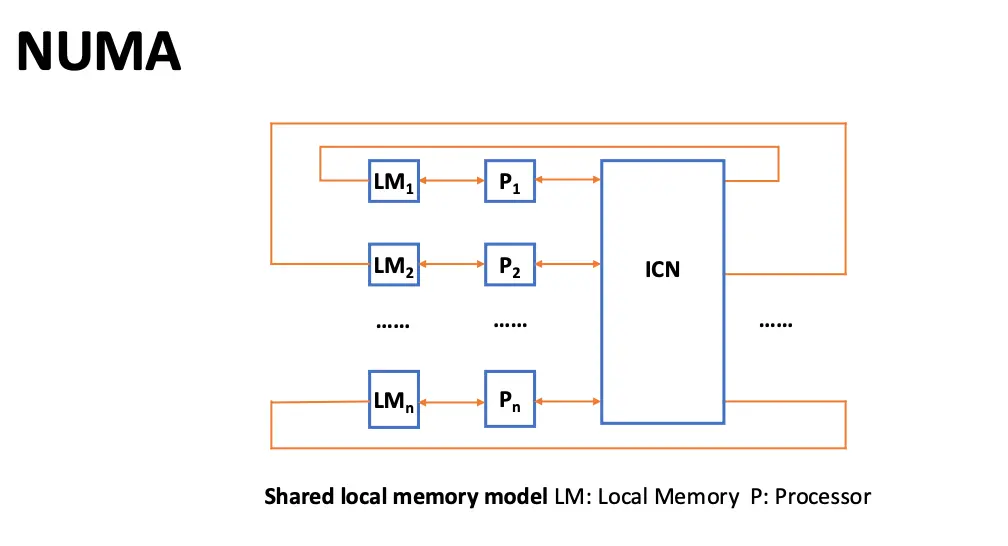
- 分布式共享存储器/Distributed Shared Memory/DSM 多处理器:也称为非一致存储器访问/Non-Uniform Memory Access/NUMA 多处理器
- 多处理器采用物理分布式存储器,这是为了支持更多的处理器,存储器必须分布在处理器之间,否则存储器系统就无法在不答复延长访问延迟的情况下为大量处理器提供高带宽支持;
- 之所以 DSM 多处理器也被称为 NUMA 多处理器,这是因为数据的访问时间取决于数据在存储器中的位置,显然,访问本地内存比访问远程内存要快;
- 缺点是 DSM 让在处理之间传输数据的过程变得更加复杂了,需要软件开发人员编写额外的代码来处理数据传输。
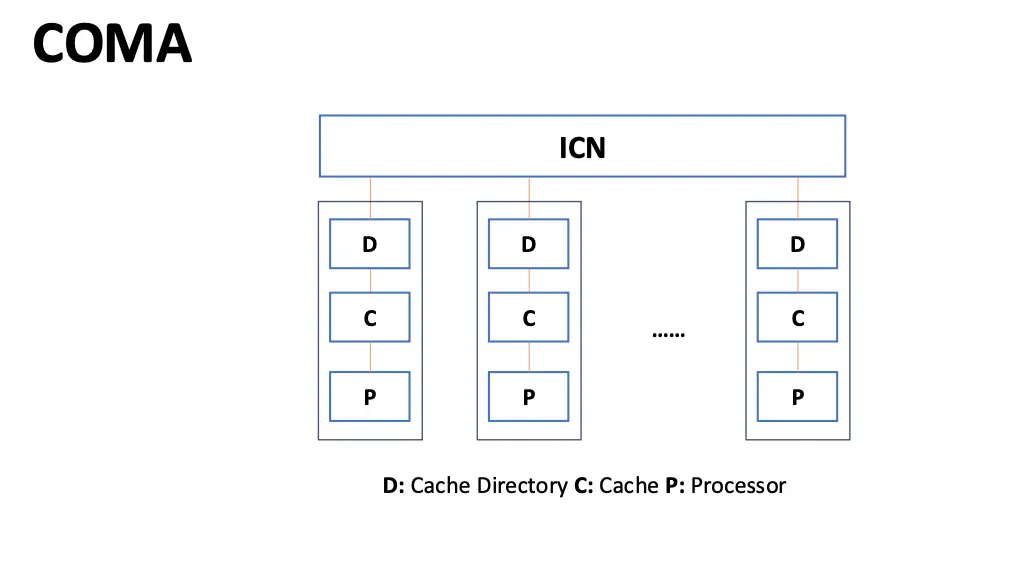
在 NUMA 多处理器之上,还有一种更特殊的结构叫做 COMA,即全缓存内存访问/Cache Only Memory Access/COMA 多处理器,每个处理器节点中没有固定的存储层次结构,所有缓存构成一个统一的地址空间。
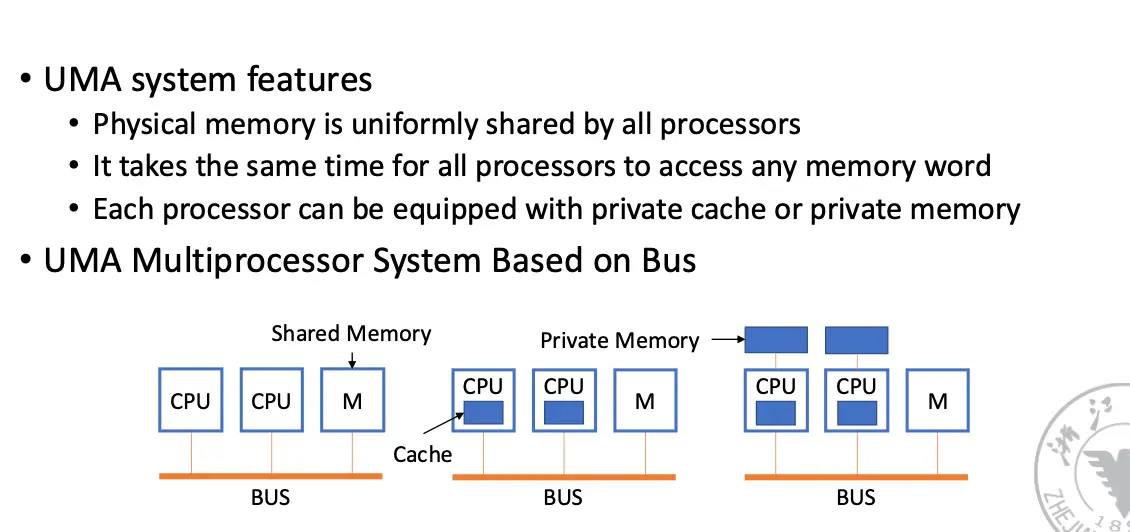
特征:物理内存被所有处理器统一共享,所有处理器访问任何内存字的时间相同,每个处理器可以配备私有缓存或私有内存。
因为 UMA 有 Shared Cache,其 Cache 一致性是有保证的。
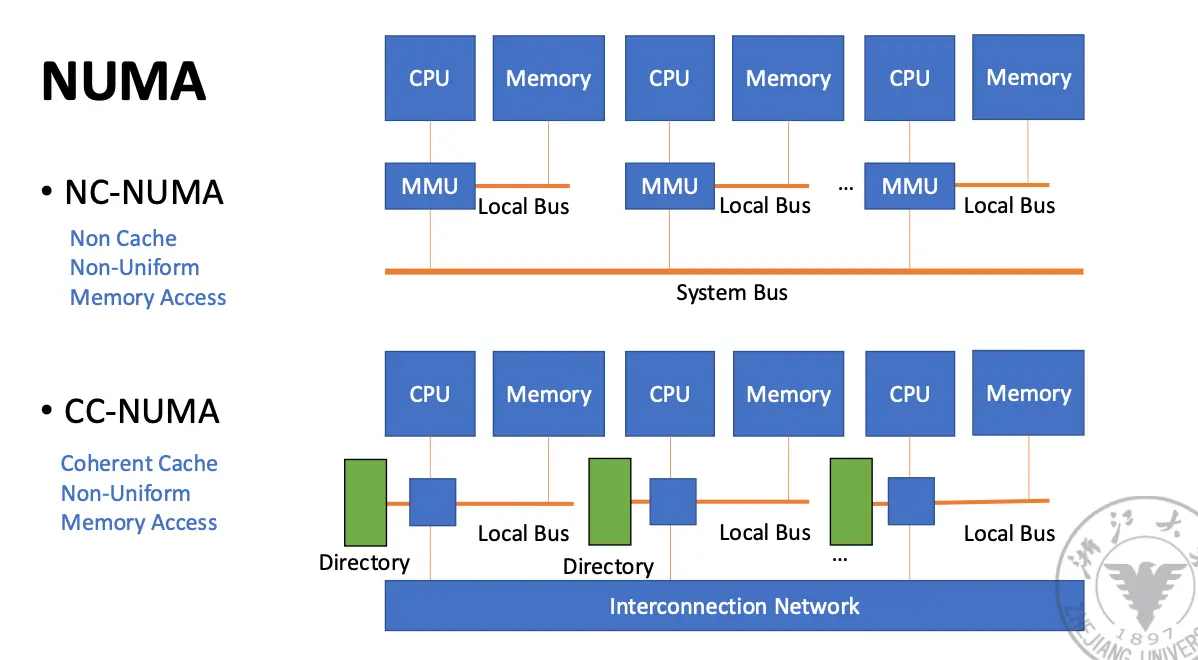
特征:所有的 CPU 共享一个一致的地址空间,使用 LOAD 和 STORE 指令访问远程内存,访问远程内存比访问本地内存慢,处理器可以使用缓存。
我们也区分 NC-NUMA/Non-Cache Non-Uniform Memory Access 和 CC-NUMA/Cache Coherent NUMA,前者不使用 Cache,后者有 Cache。使用 Cache 就必须要保证 Cache 一致性,后面会讲。
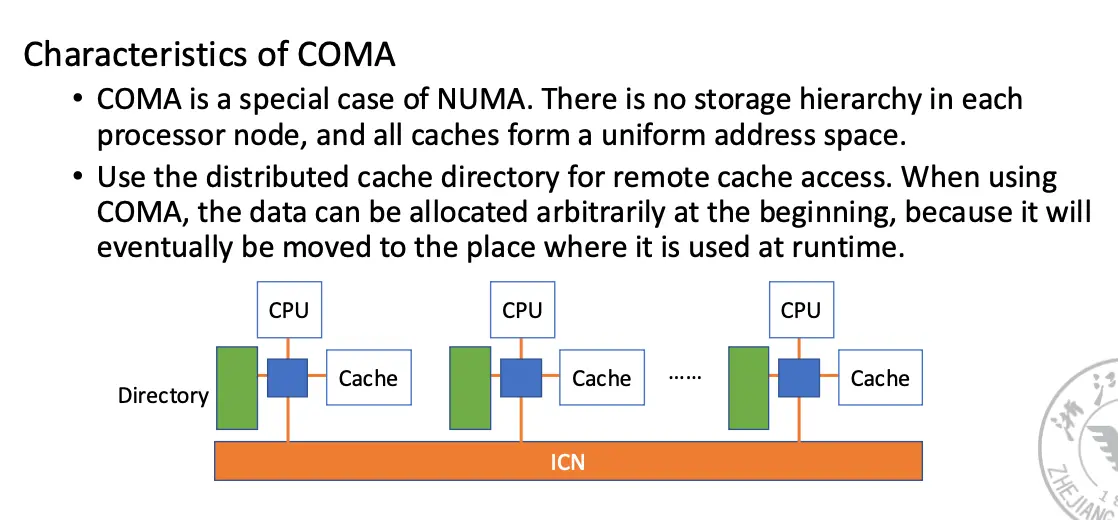
特征:所有 Cache 形成一个统一的地址空间,存在数据迁移,使用分布式的缓存目录进行远端 Cache 的访问。数据在最开始时可以被分配在任意 Cache 中,但程序开始执行后这些数据会被移动到需要使用的地方去。
1.2 MIMD 多计算机架构¶
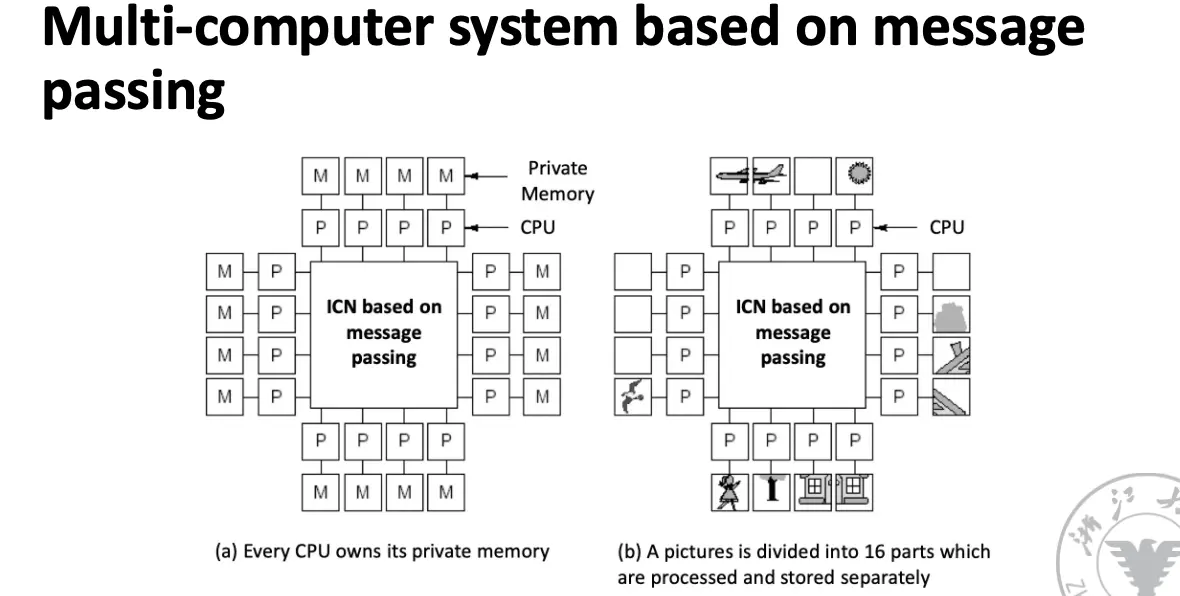
每一个线程/处理器都有自己的私有内存,他们通过 ICN/Interconnection Network 进行通信,模型被概括为 NORMA/No-Remote Memory Access。
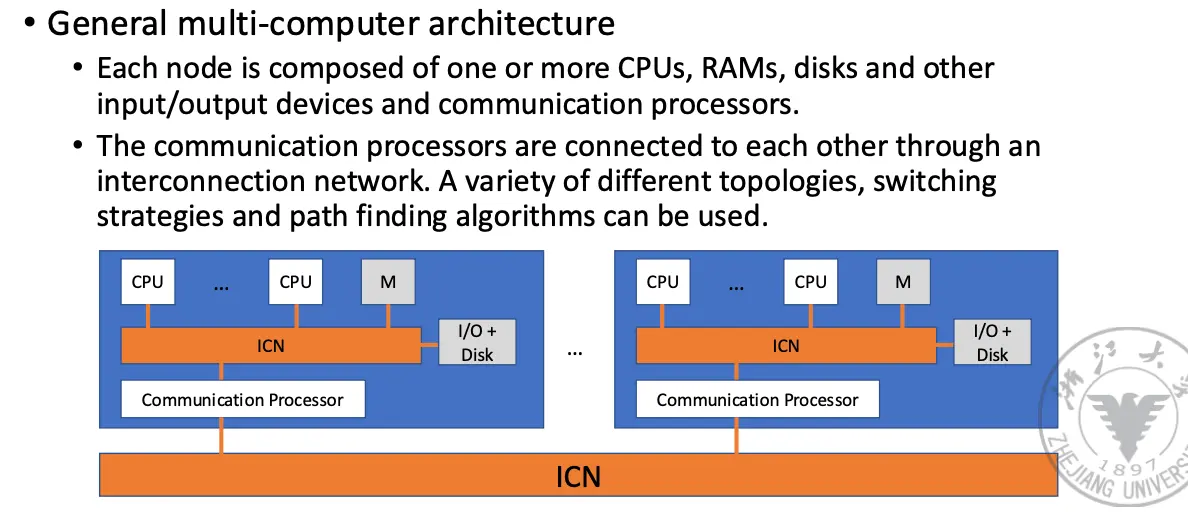
每一个节点由一个或者多个 CPU、RAM、硬盘和 I/O 设备组成,这些节点通过 ICN 连接,利用一系列拓扑机构、开关策略和路径寻找算法来实现通信。
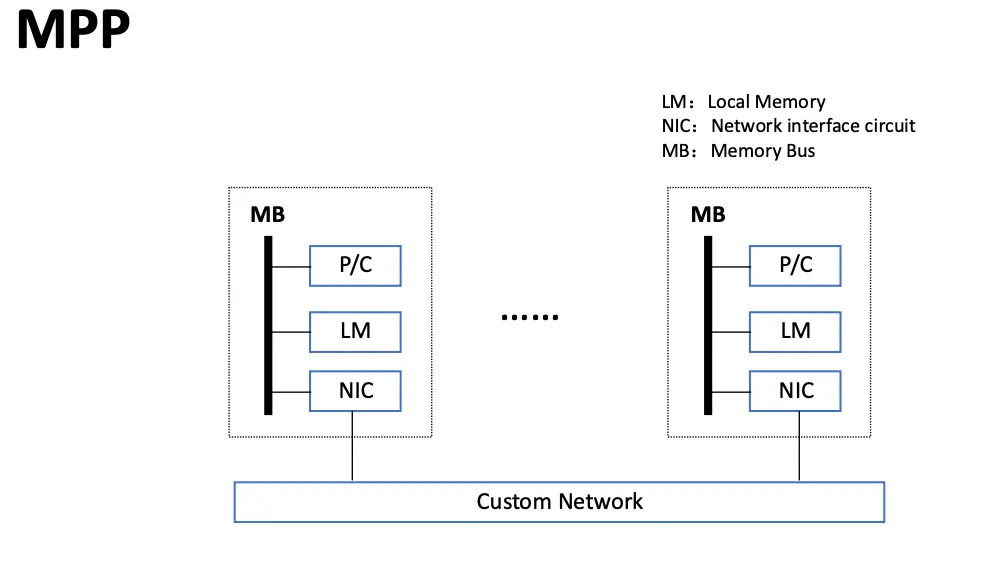
MPP 是由数百个处理器构成的,大规模并行计算系统,现在也广泛用于商业和网络应用,开发难度大,价格高,市场有限。
特征:一般使用标准的商用 CPU 作为处理器,使用高性能的私有互连网络,能以低延迟和高带宽传递消息,具备强大的输入/输出能力,具备特殊的容错处理能力。
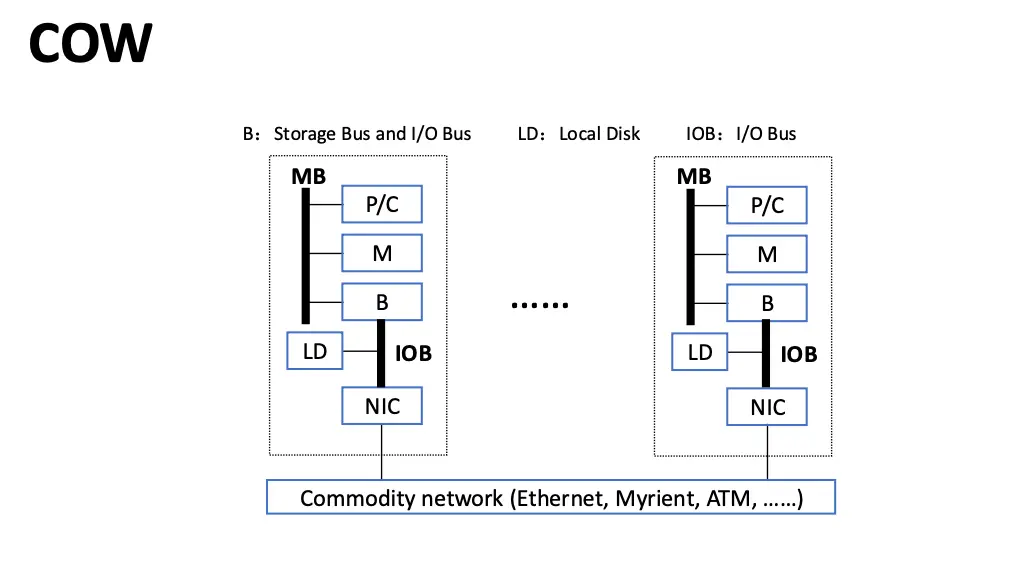
COW 是由大量通过商用网络连接在一起的 PC 或工作站组成的系统,可以完全使用打屁模生产的商用组件组装,性价比很高。也分为集中式和非集中式两种类型。
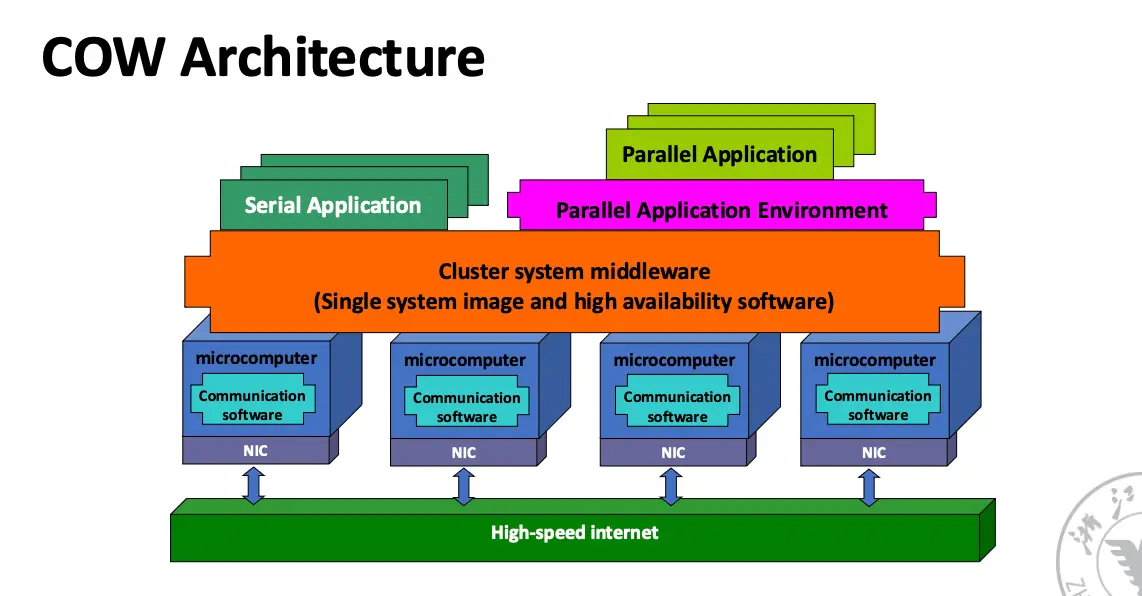
1.3 并行计算的挑战¶
没啥可说的,学会使用 Amdahl 定律就行:



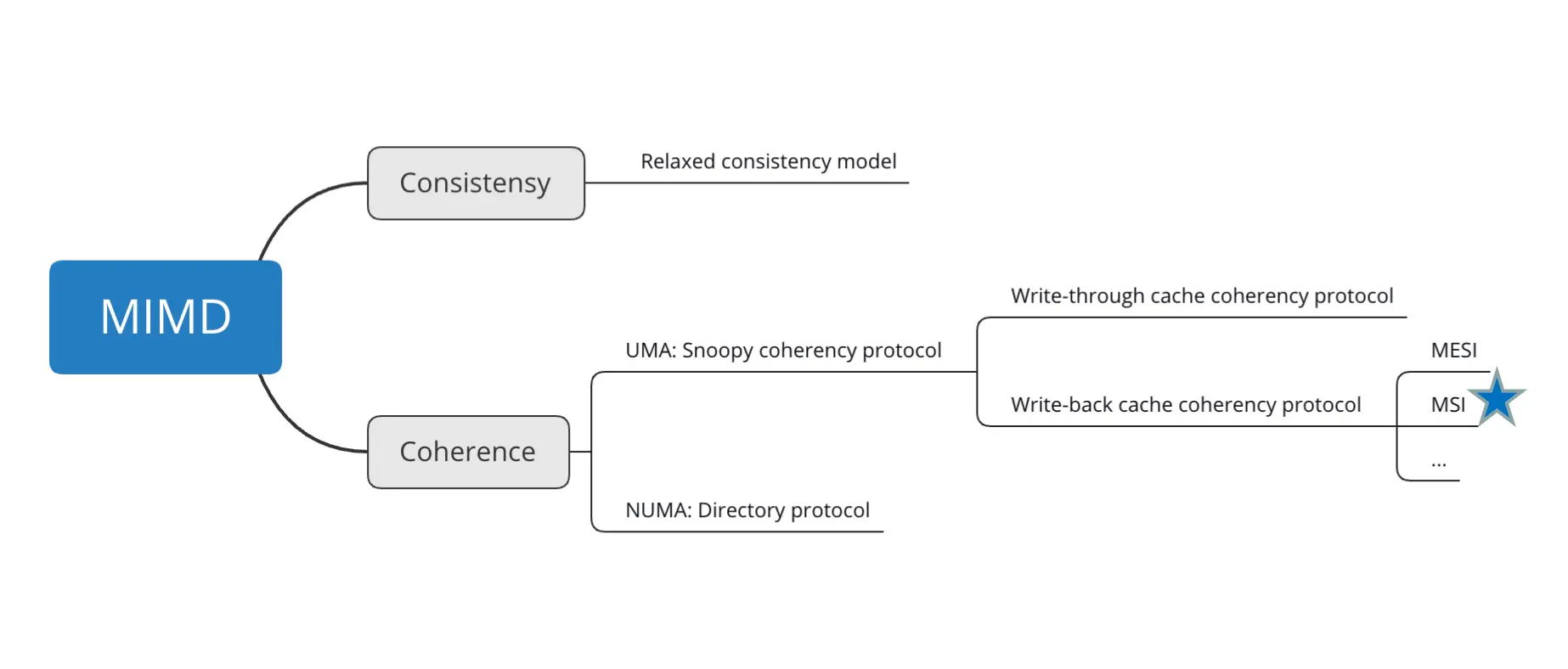
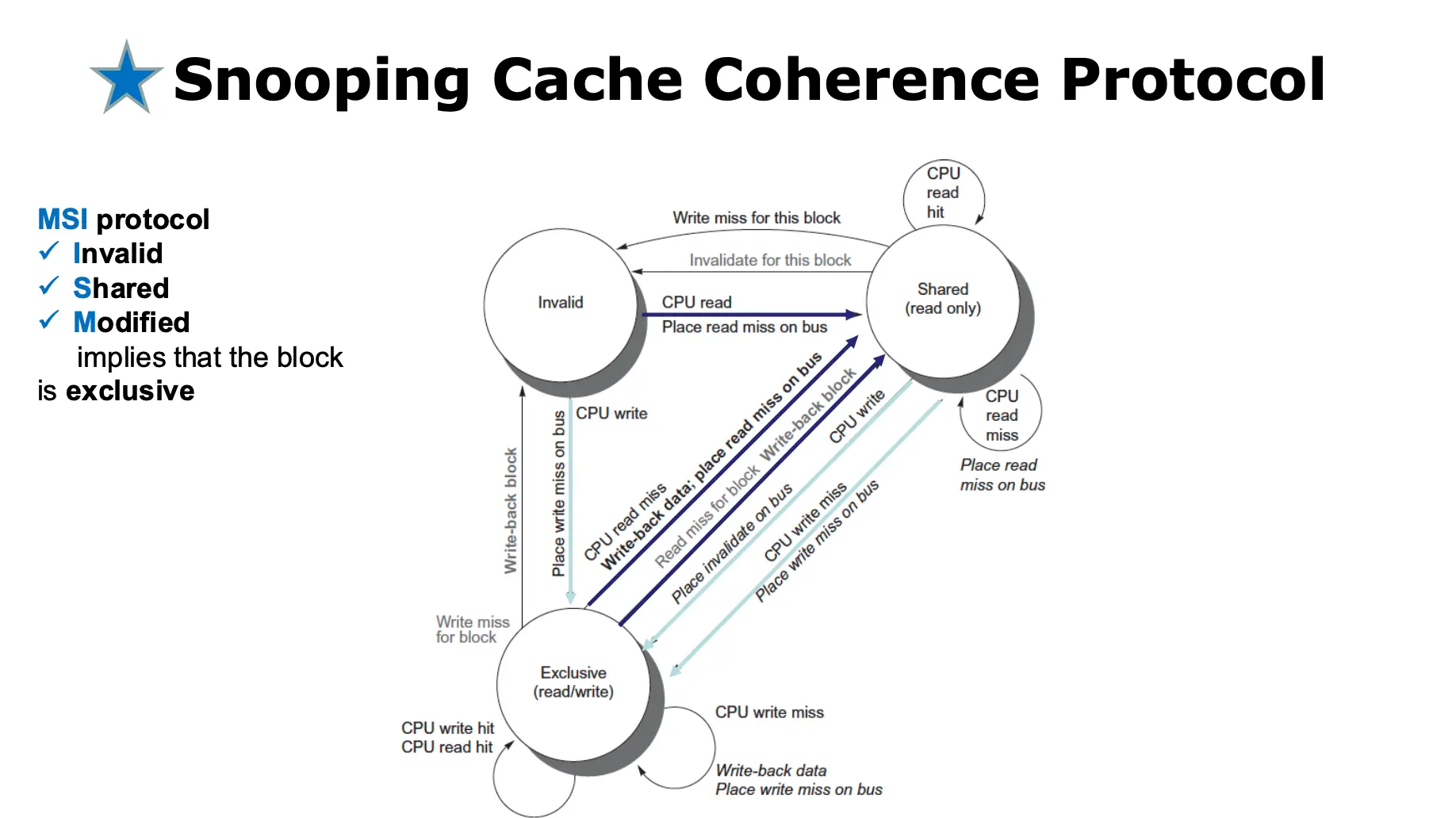
2. 缓存一致性协议¶
卧槽内容太多了,我觉得我意会了