Data-Level Parallelism in Vector, SIMD, and GPU Architectures¶
约 1133 个字 32 张图片 预计阅读时间 4 分钟
高僧预测
完全不是重点。




Flynn 分类法
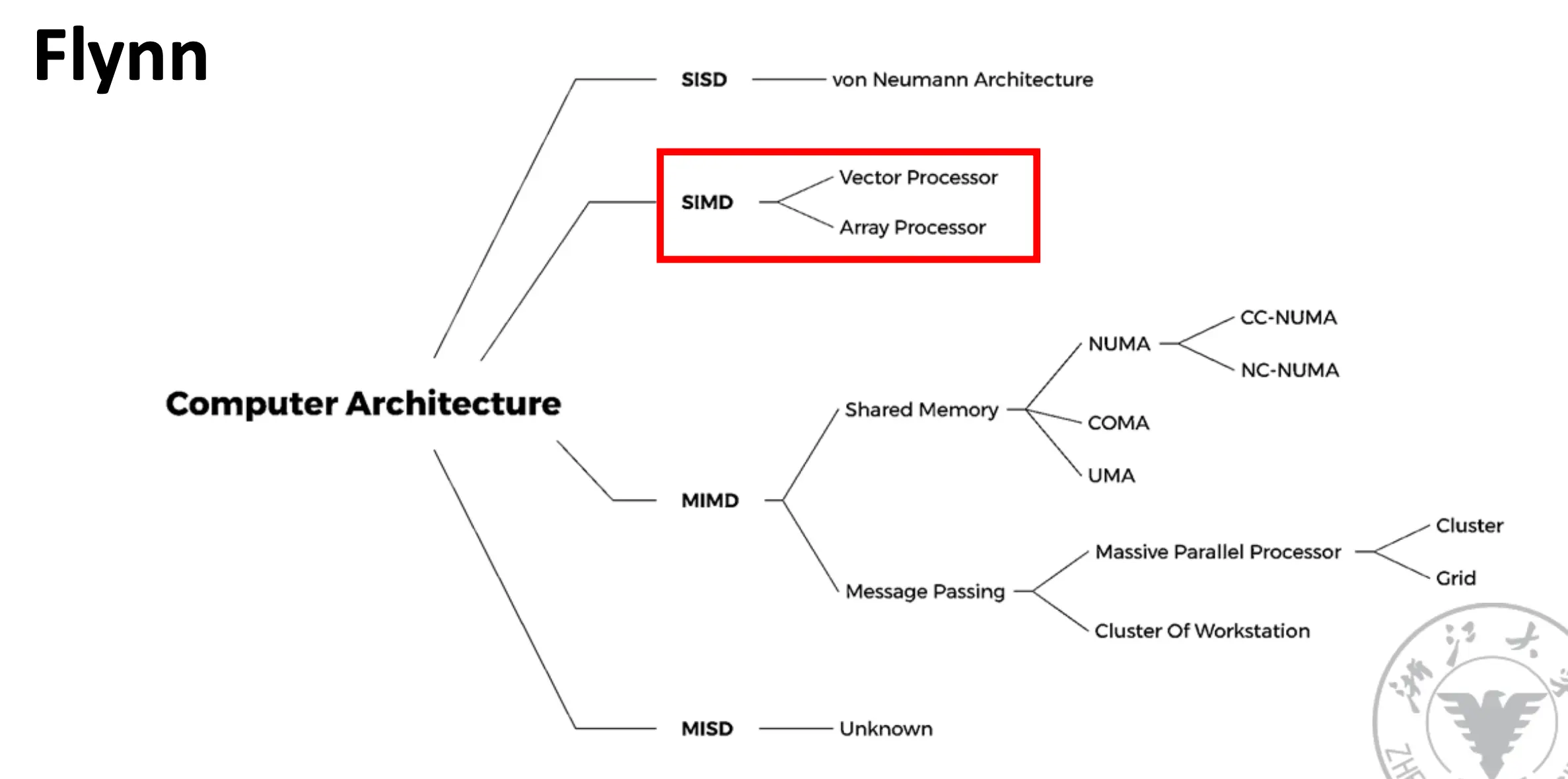
1. SIMD:向量处理器/向量机¶
1.1 Vector Processor & Scalar Processor¶
- 向量处理器/Vector Processor:在硬件中使用了向量数据表示和向量指令集的流水线处理器;
- 标量处理器/Scalar Processor:不具备向量数据表示,也不支持一次处理多个数据元素的向量指令的流水线处理器。
流水线处理器的特点:
- 向量内各元素在运算过程中通常彼此独立,元素之间几乎不存在相关性。
- 如果向量操作编排不合理,会引发数据相关问题与运算功能的频繁切换,降低流水线效率。
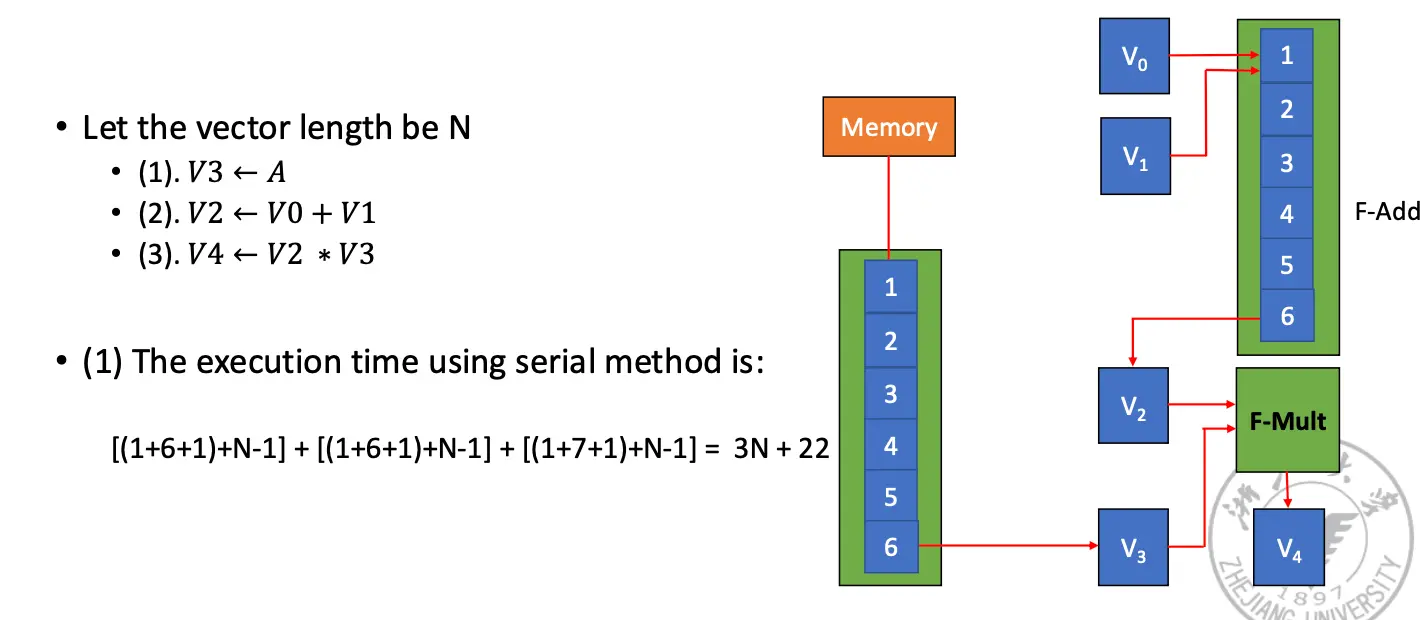
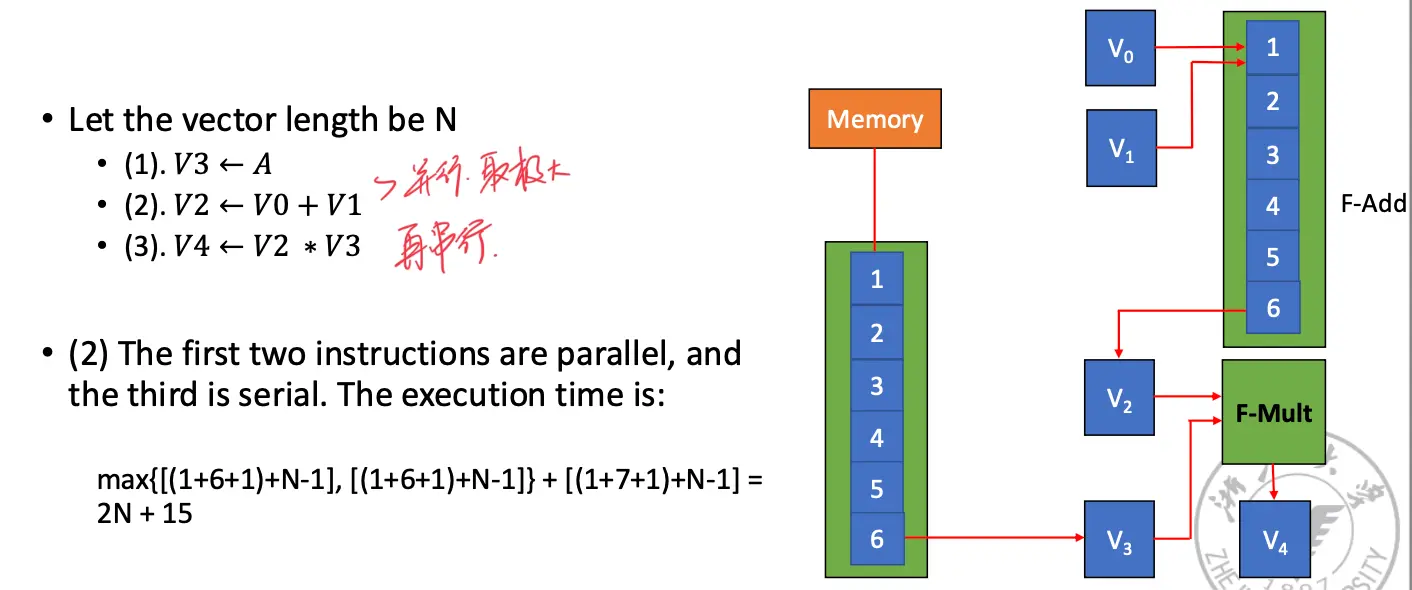
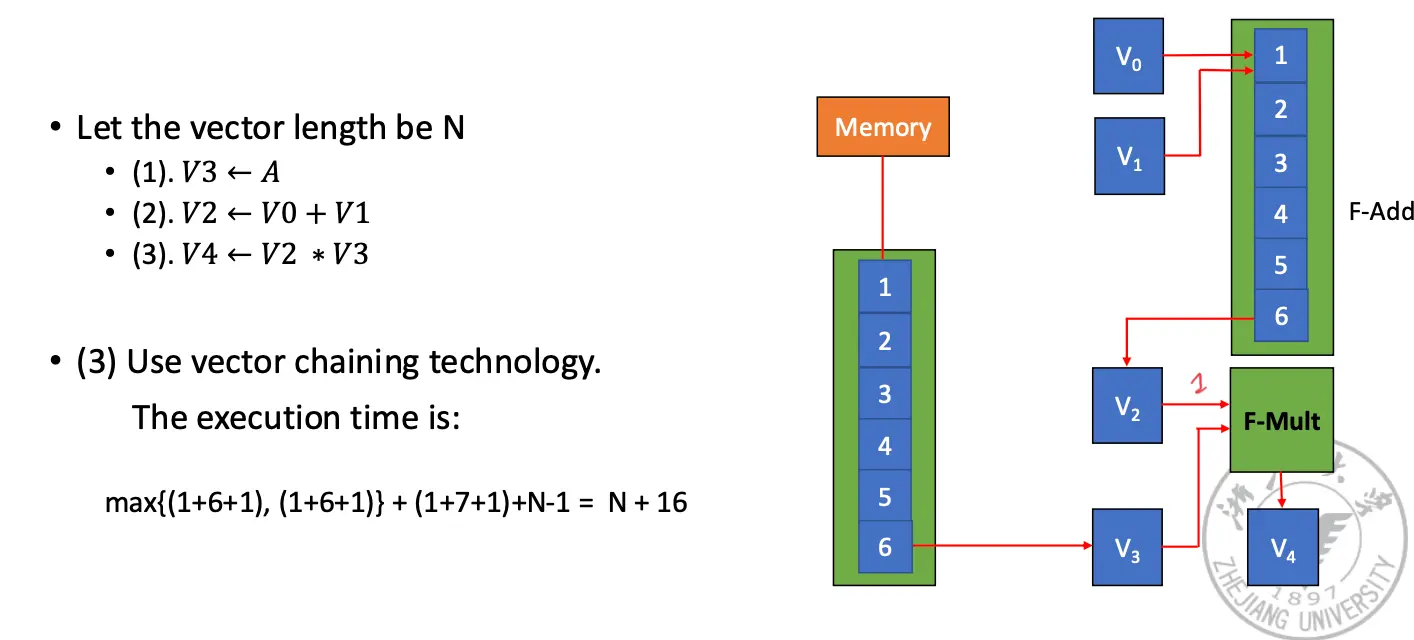
因此考虑下面三种不同的计算数据的方式,均以计算 \(D = A \times (B + C)\) 为例,这里的每一个向量的长度都是 \(N\):
意味着向量计算对每一个位置分别计算。

问题很多:
- 对每一个位置进行计算的时候,很可能出现 RAW 相关,导致流水线效率低下;
- 如果使用静态多功能流水线,流水线功能必须经常切换,需要等到前一个功能部件排空才可以继续进行,因此流水线的吞吐率反而不及传统的串行执行;
- 这种方法不适合向量处理器。
意味着对整个向量进行操作。虽然极大减少了数据相关性和功能切换次数,但是整体方式收到 \(N\) 的制约,且没有完全流水化。
因为整个向量的长度不固定,这行的处理器架构需要为 Memory-Memory 结构,源寄存器和目标寄存器都存储在内存之中,中间结果也需要被放回内存之中,虽然可以在内存和流水线之间加入 Buffer,但是访存瓶颈依旧存在。

将向量拆分成多组,组内垂直处理,组间水平处理。
处理器架构可以是 Register-Register 结构,因为组内垂直处理可以完全放到寄存器上,也就是流水线的输入输出都连接到寄存器上。可以降低访存次数。

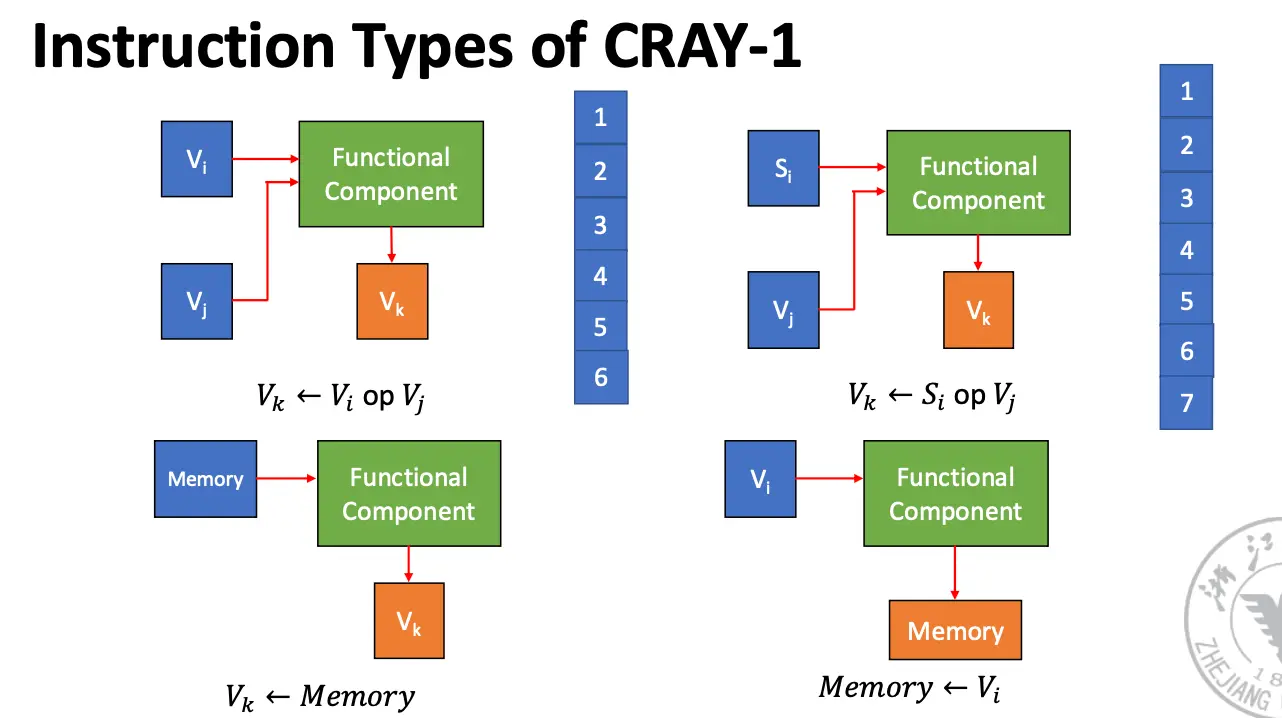
1.2 Cray-1 Vector Processor¶
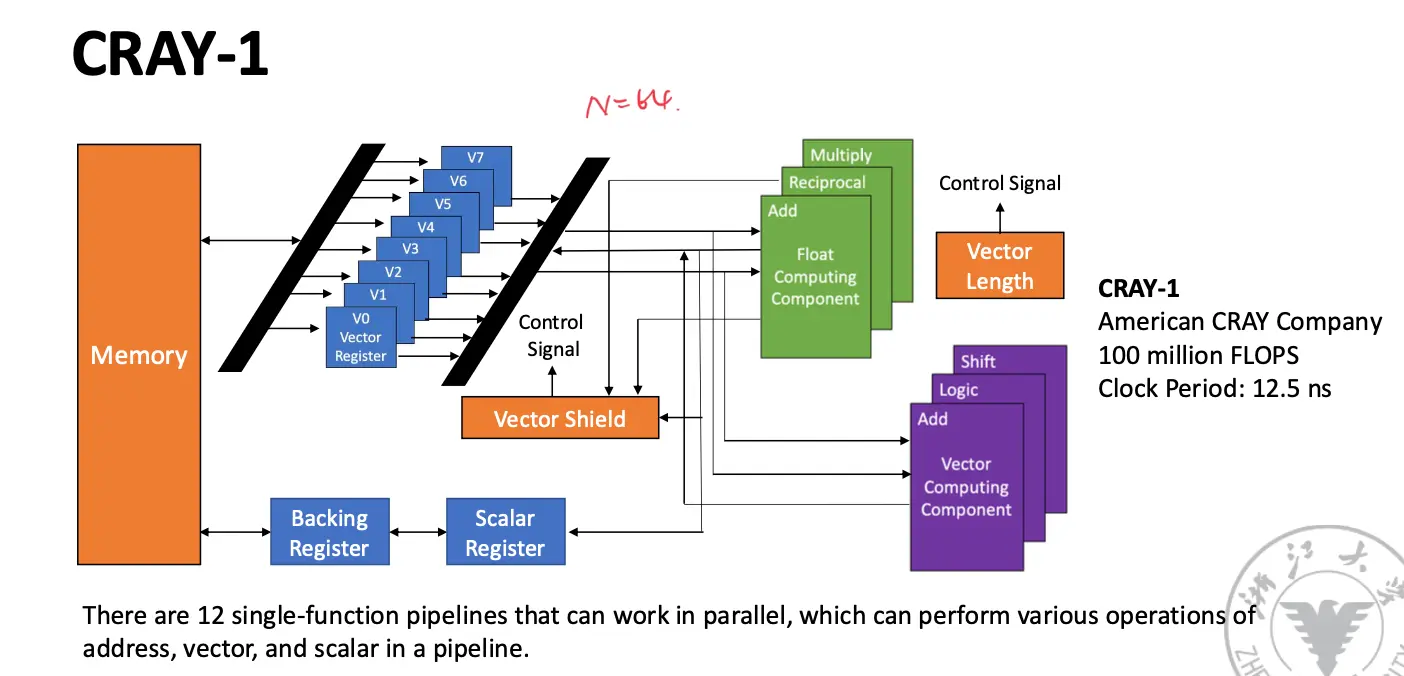
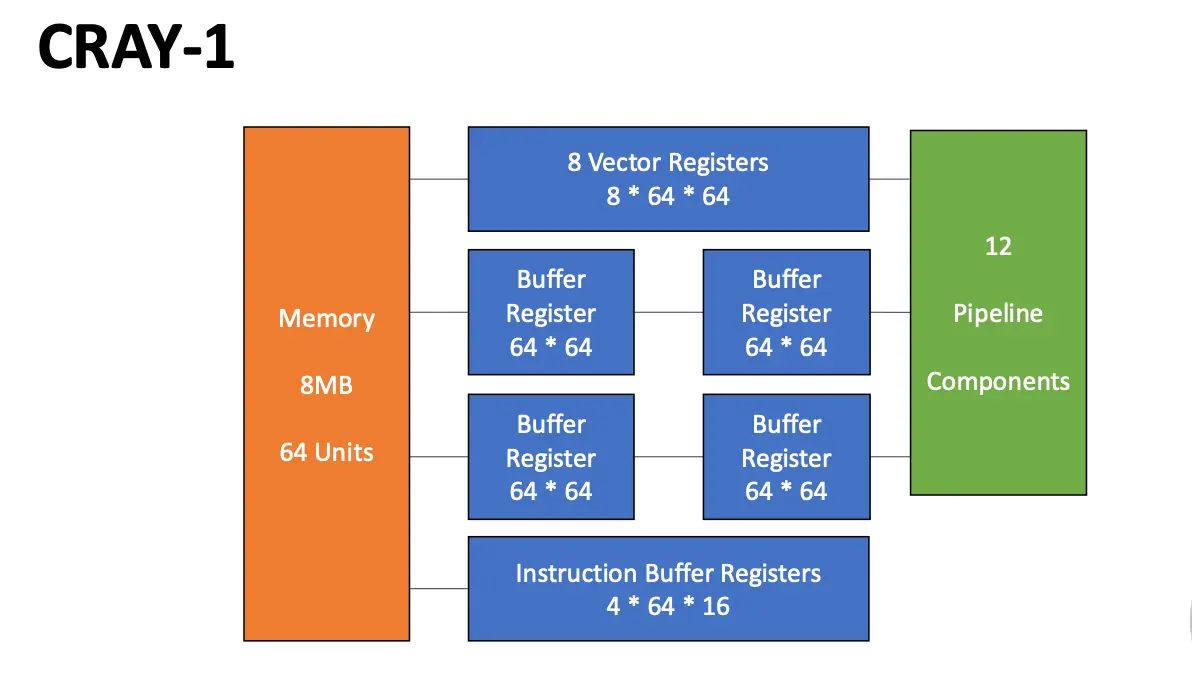
- 每一个向量寄存器都有一条独立总线连接到 6 个向量功能单元;
- 每一个向量功能单元都有一条总线,返回操作结果到向量寄存器总线;
-
只要没有寄存器冲突/Vi 冲突和功能冲突,每一个向量寄存器和向量功能单元可以并行执行。
-
向量寄存器冲突/Vi 冲突:并行执行的指令访问相同的向量寄存器,就发生冲突/The source vector or result vector of each vector instruction working in parallel uses the same Vi.
-
读写数据相关:
\[\begin{aligned} V_0 &\leftarrow V_1 + V_2 \\ V_3 &\leftarrow V_0 \times V_4 \end{aligned}\] -
读数据相关:
\[\begin{aligned} V_0 &\leftarrow V_1 + V_2 \\ V_3 &\leftarrow V_1 \times V_4 \end{aligned}\]
-
-
功能冲突:并行执行的每一个向量指令必须不使用相同的向量功能单元/Each vector instruction working in parallel must use the same functional unit.
\[\begin{aligned} V_3 &\leftarrow V_1 \times V_2 \\ V_5 &\leftarrow V_4 \times V_6 \end{aligned}\]只有当第一条向量指令完全执行完毕,这时候浮点乘法单元被释放,第二条向量指令才开始执行。
-
指令类型以及执行时间:
1.3 提升向量处理器的性能¶
主要有几种方法:使用多个功能部件,另其并行执行;使用 Vector Chaining 加速指令串的执行;使用 Recycle Mining 加速数据重用,使用多处理器系统。
假设:将向量数据元素送到功能部件、将结果存在向量寄存器以及将数据从内存送到 fetch function unit (可以看作是向量寄存器)都需要一拍。

1.4 RV64 Vector Extension¶
大致基于 Cray-1 架构,但是有改进和不同。
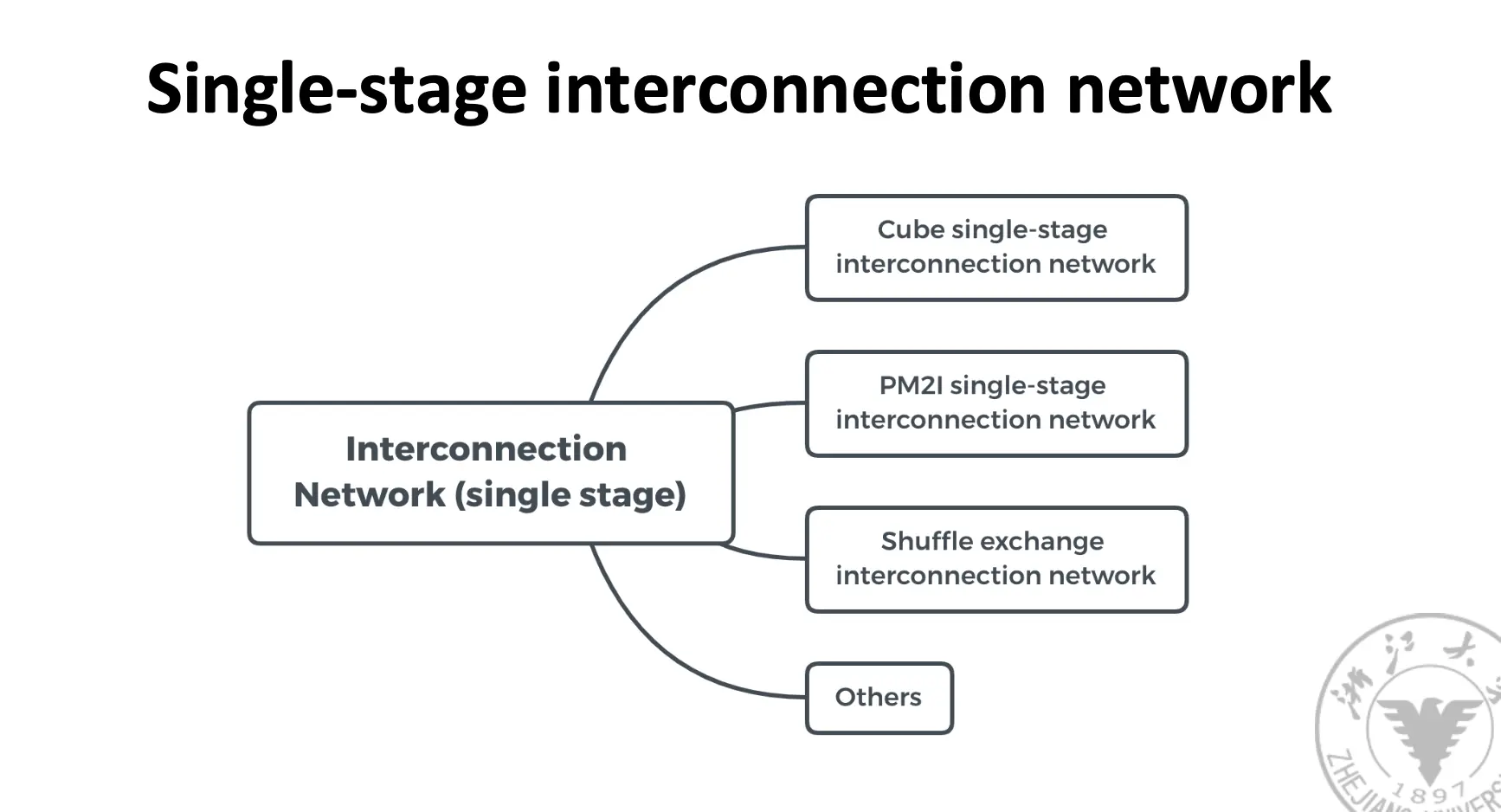
2. SIMD:Array Processor/阵列机¶
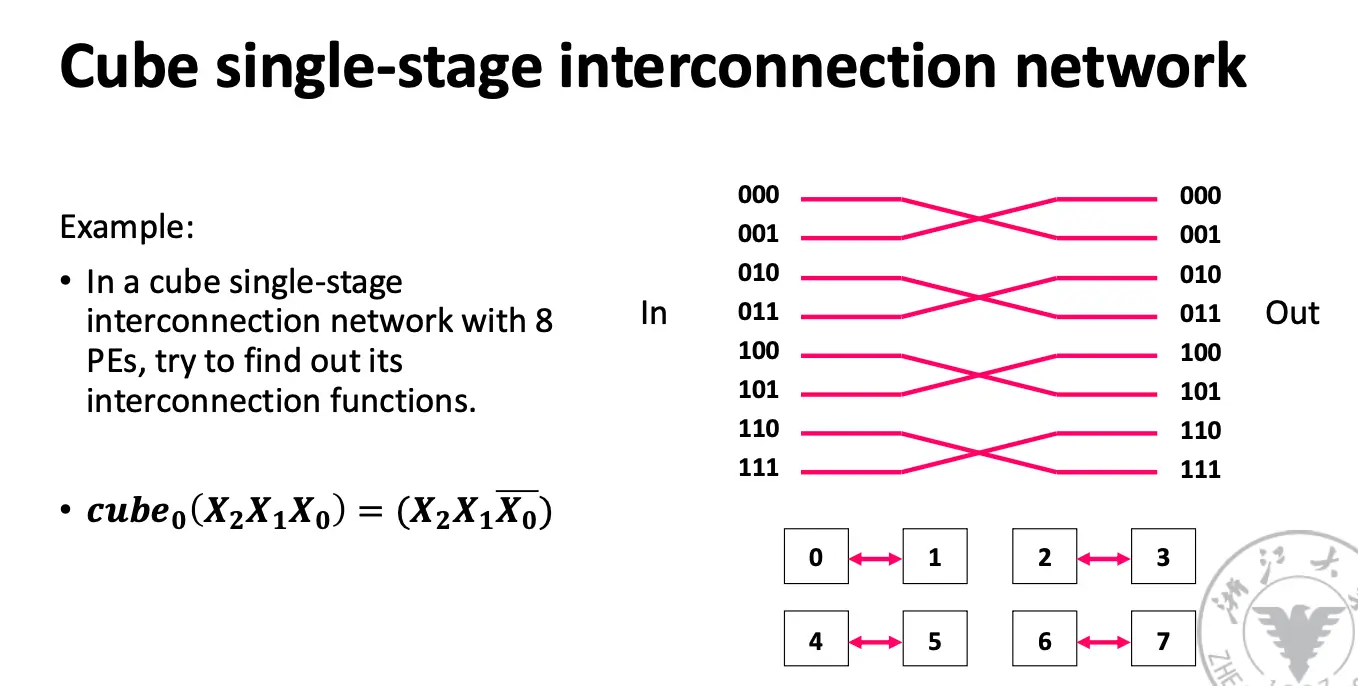
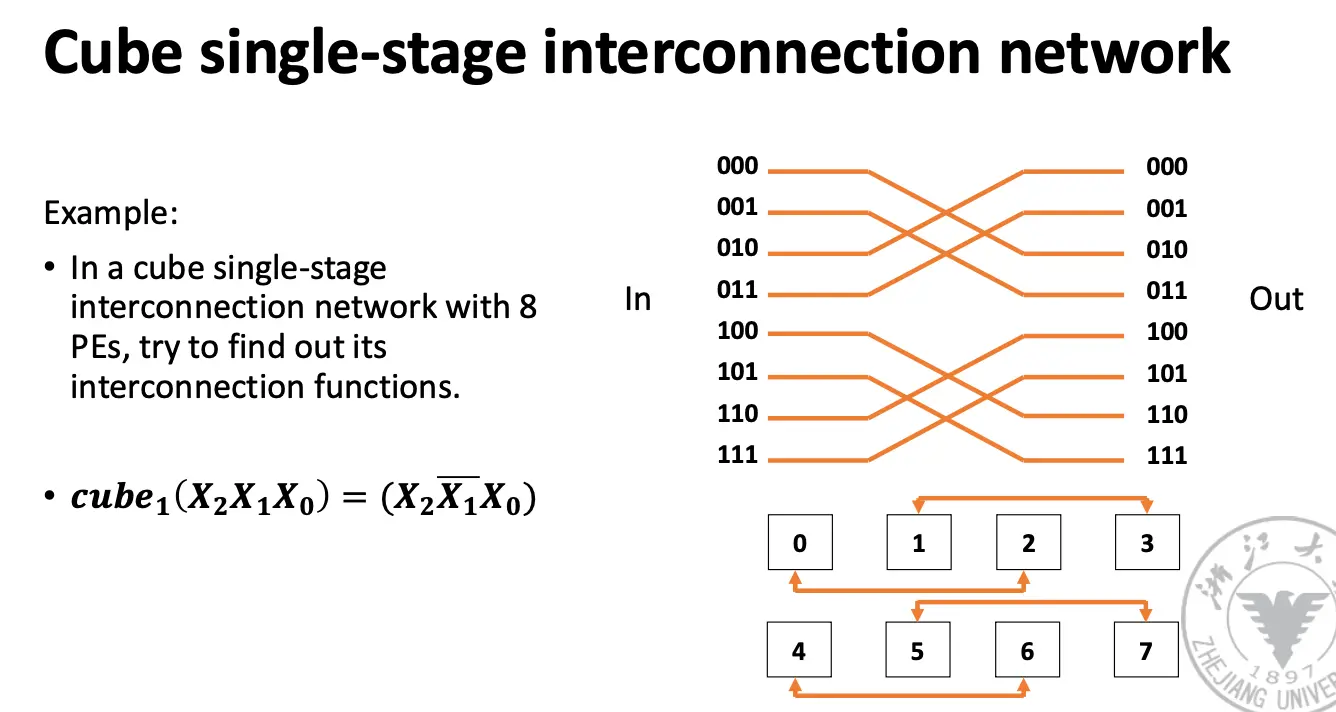
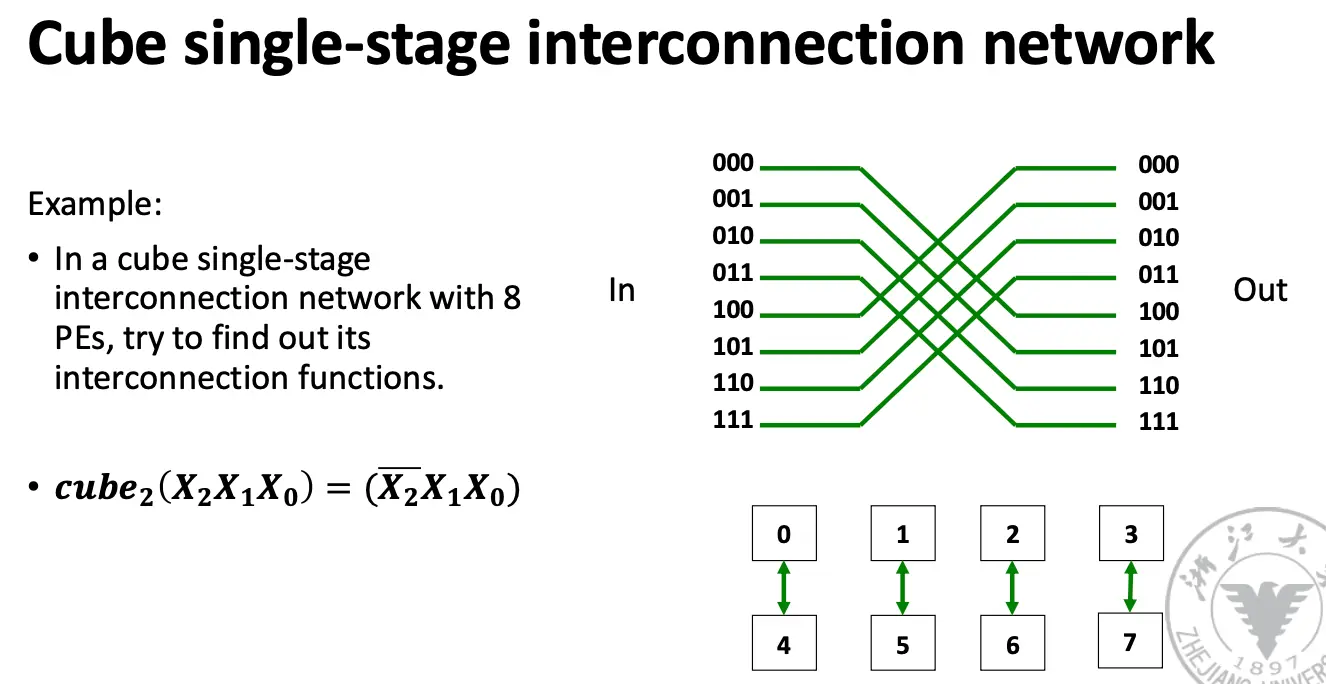
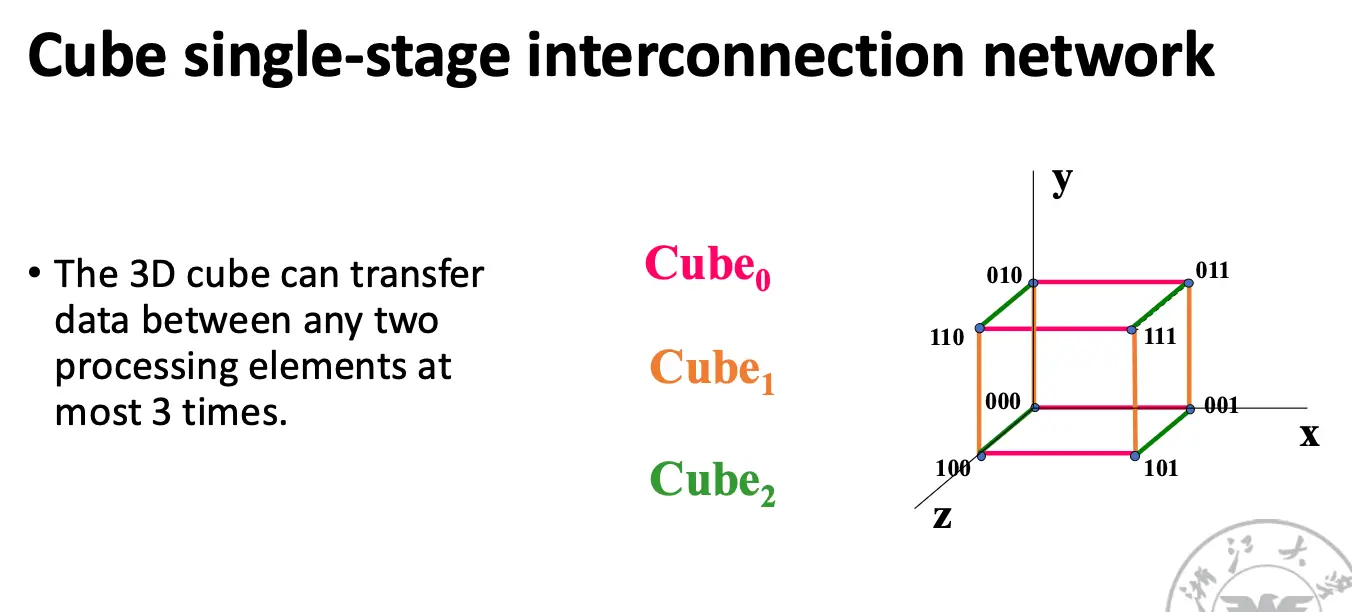
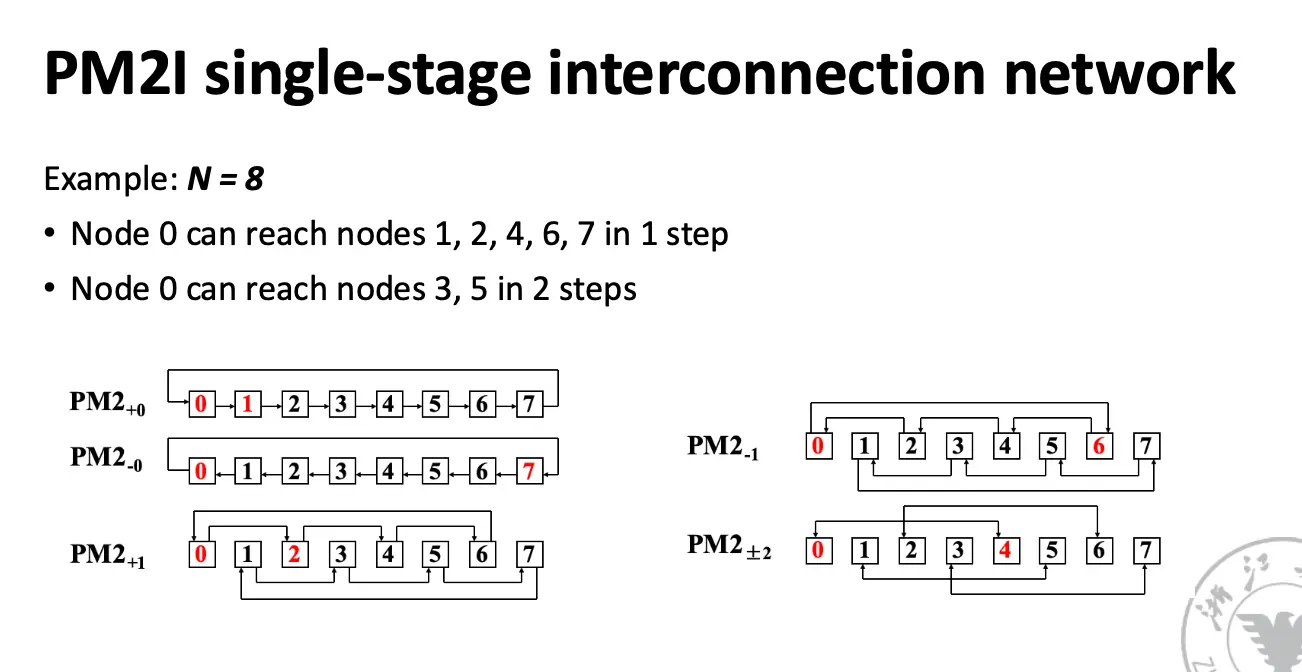
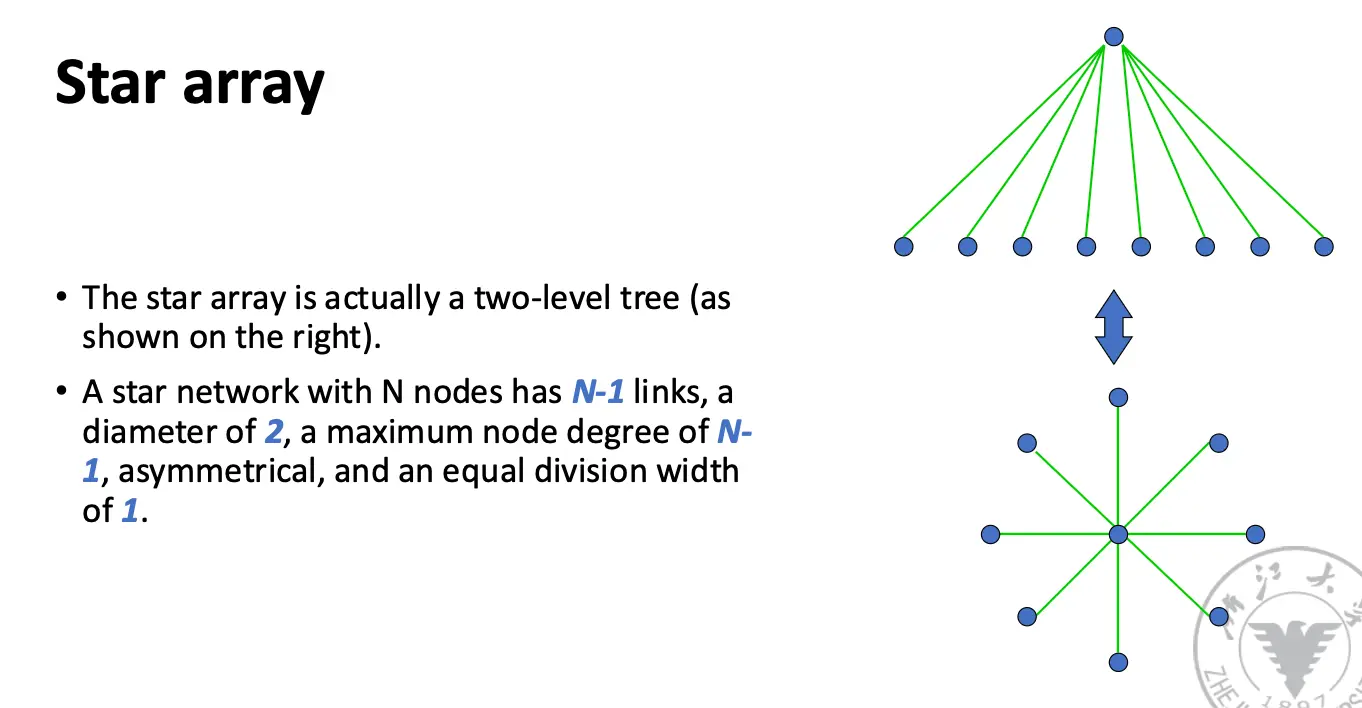
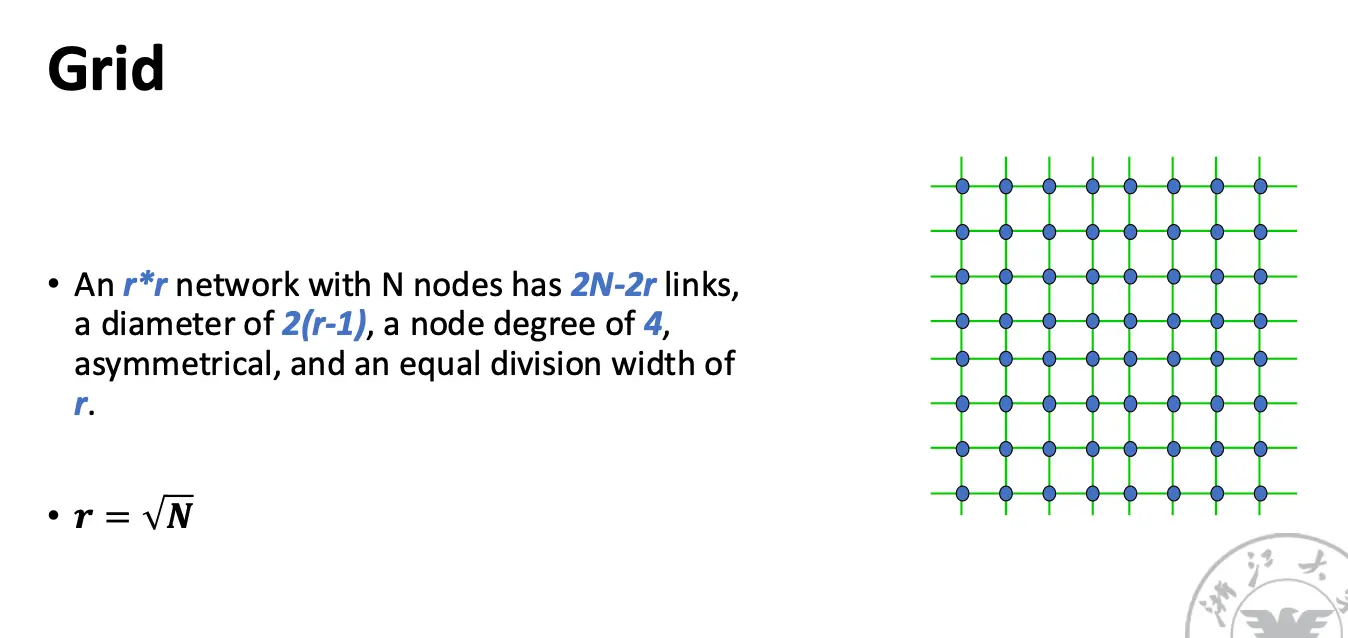
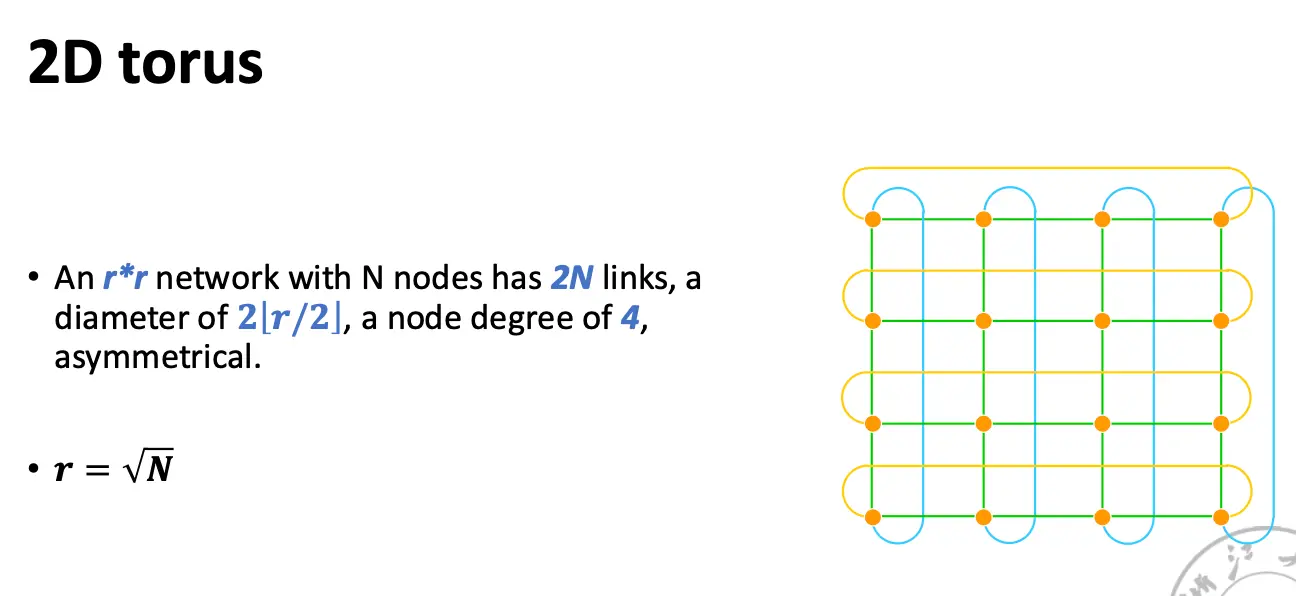
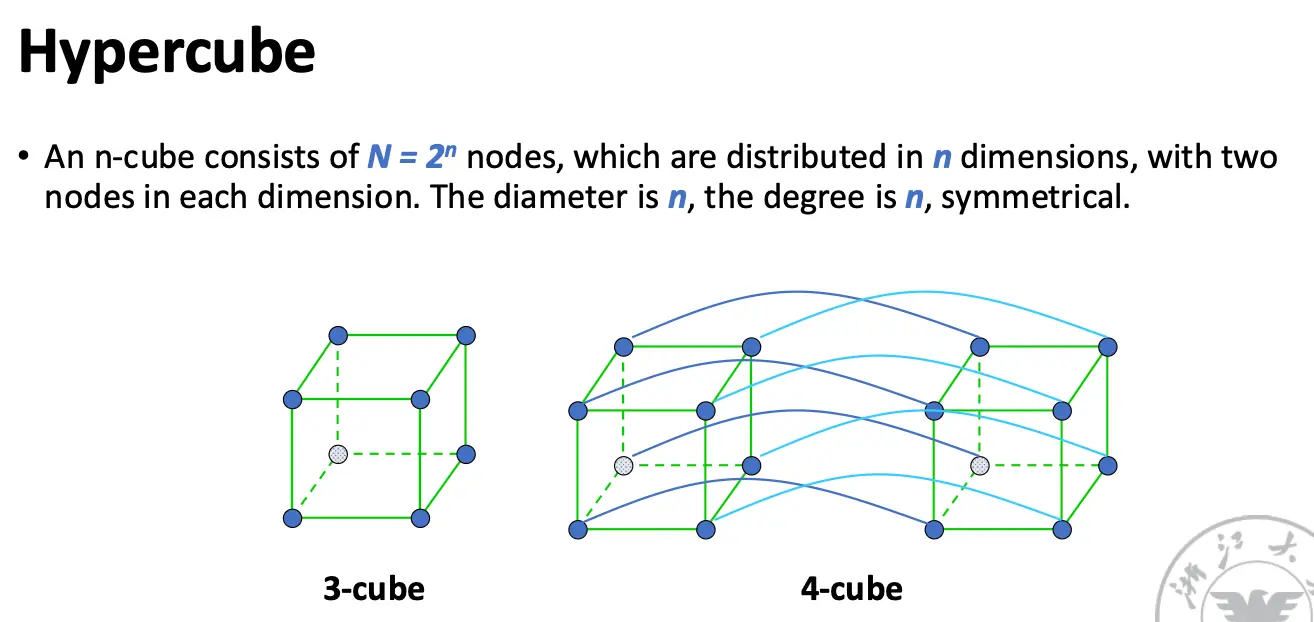
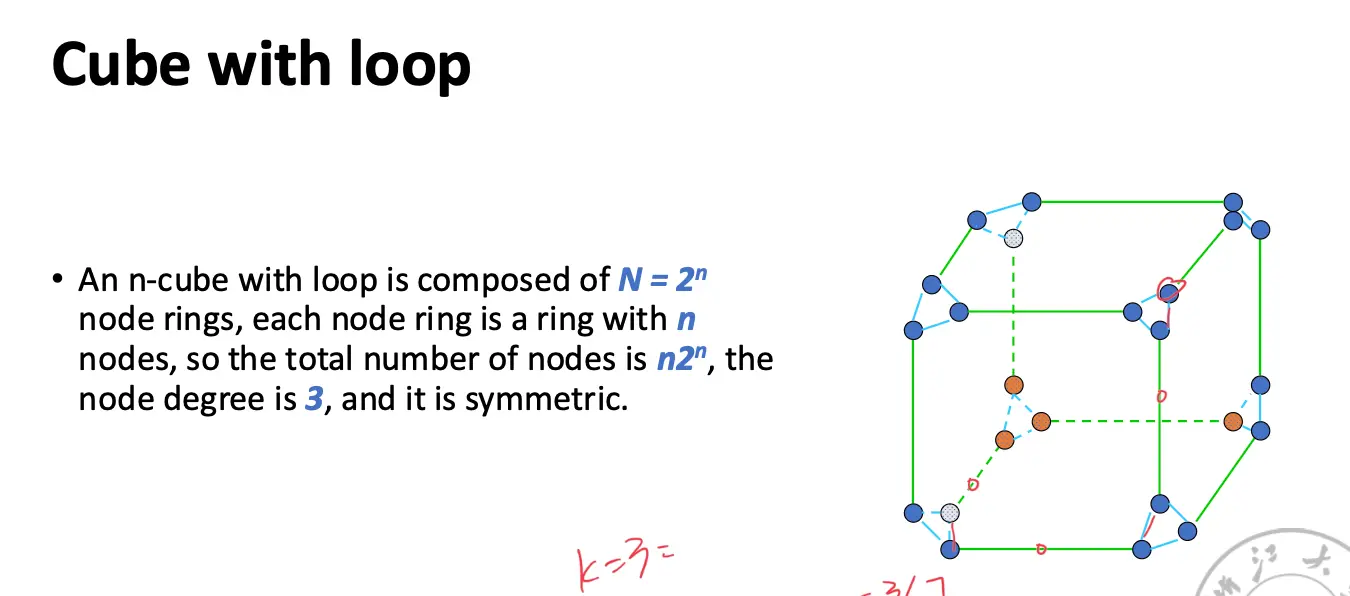
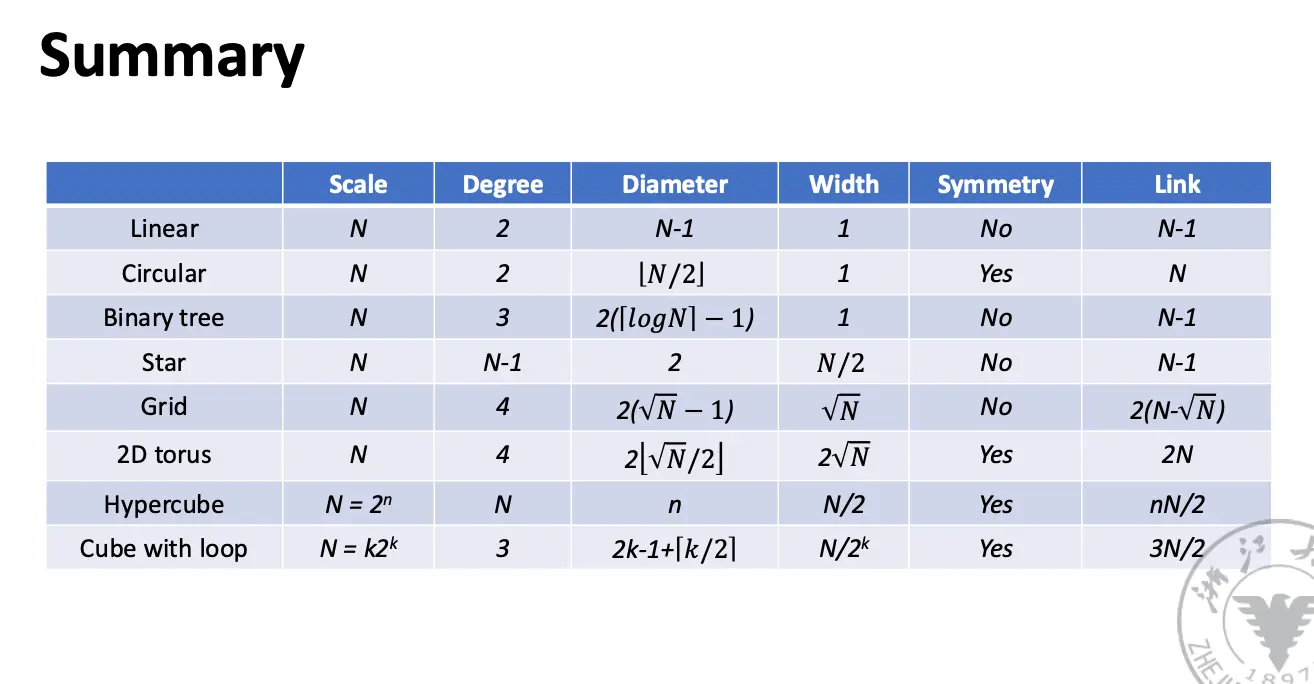
奇形怪状的网络:

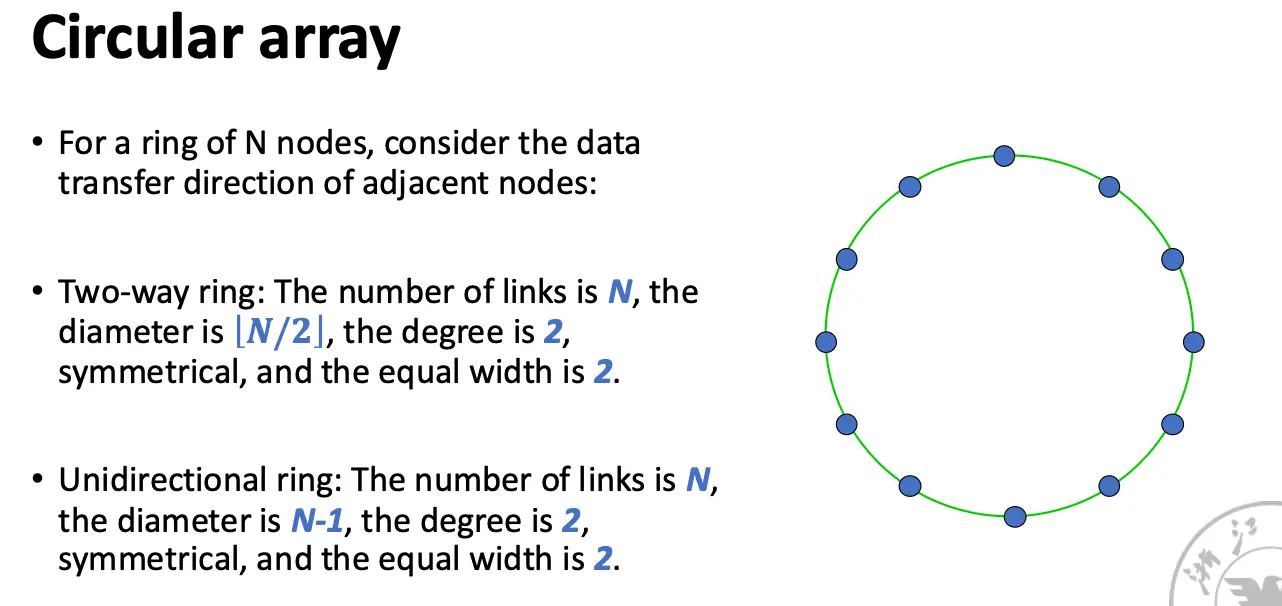
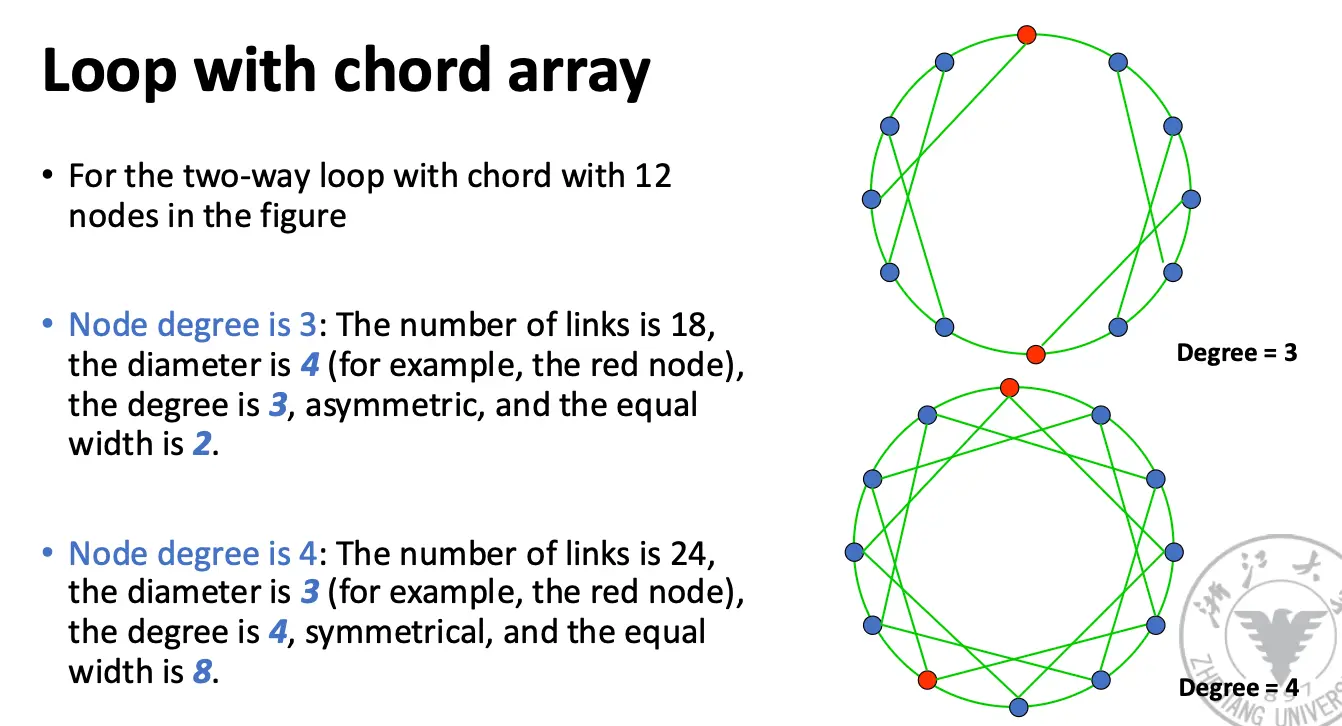
环形网络以及带有弦的环形网络:
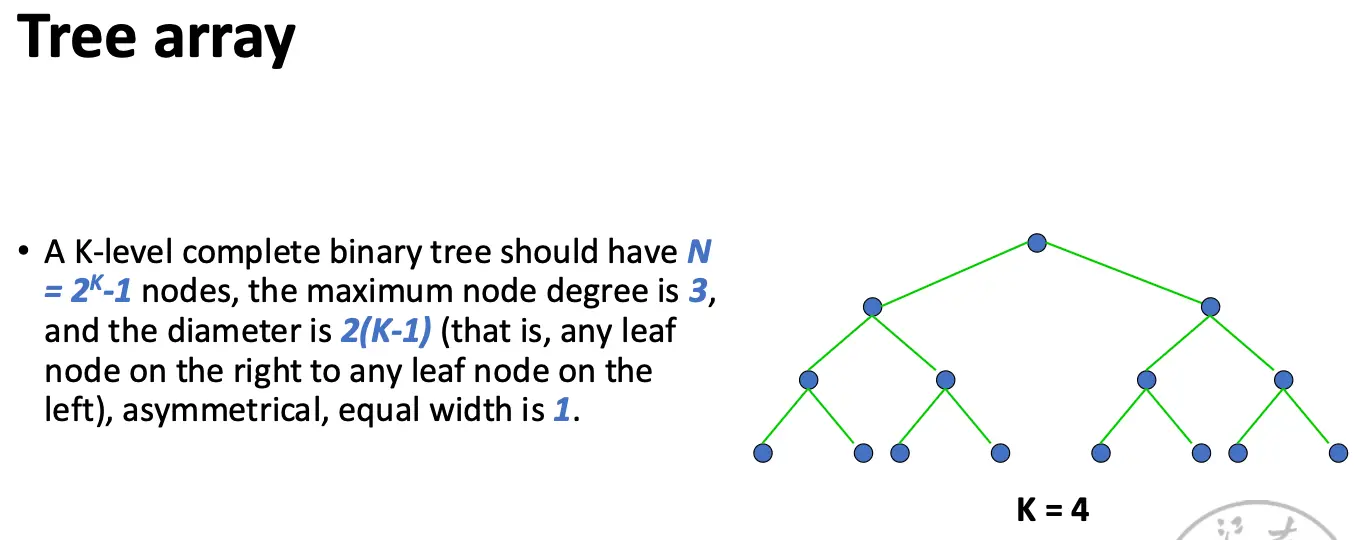
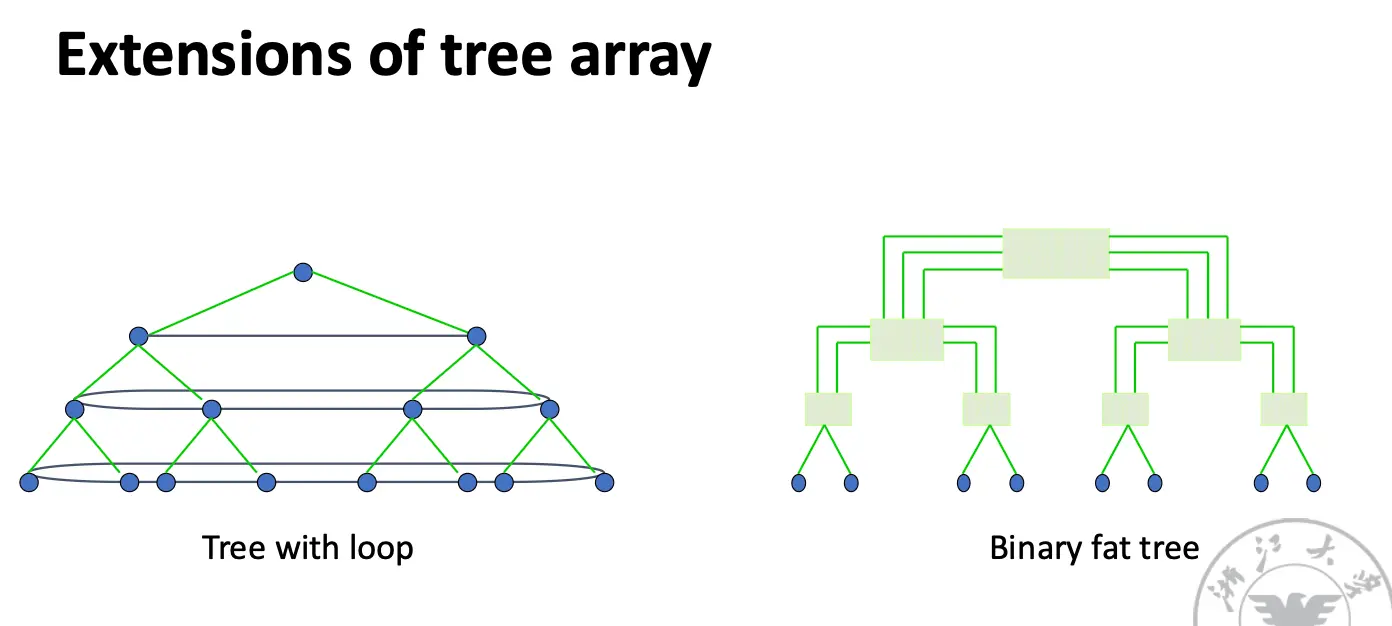
树形网络以及带有循环的树形网络、Binary Fat Tree: