Memory Hierarchy¶
约 2608 个字 31 张图片 预计阅读时间 9 分钟
Outline
高僧预测


1. 内存类型与局部性原理¶
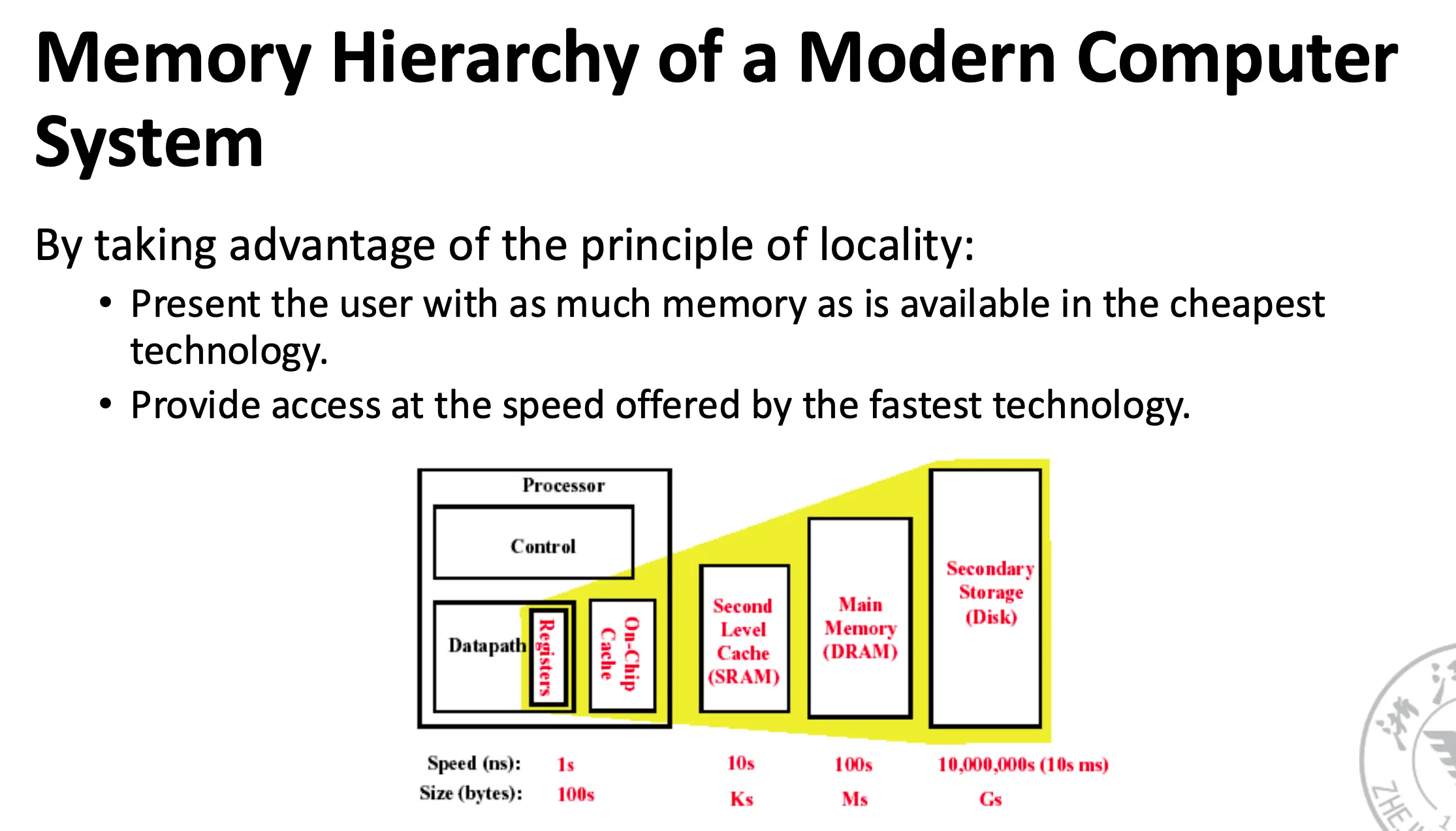
根据用途的差别,我们可以将内存层次结构分为:寄存器/Register、高速缓存/Cache、主存/Main Memory、磁盘/Disk。
根据介质的不同,我们可以看见下面这些可能的介质:
- 机械存储器:声波/扭矩波延迟线存储器、磁芯存储器、磁鼓存储器;
- 电子存储器:SRAM/静态随机存取存储器(速度快,成本高)、DRAM/动态随机存取存储器(主存常用技术)、SDRAM/同步动态随机存取存储器、Flash/闪存、ROM/只读存储器。
- 光学存储器。
- 时间局部性/Temporal Locality:如果一个数据项被引用,他在不就得将来很可能会被再次引用。
- 空间局部性/Spatial Locality:如果一个数据项被引用,那么与它相邻的数据项也很可能被引用。
2. Cache¶
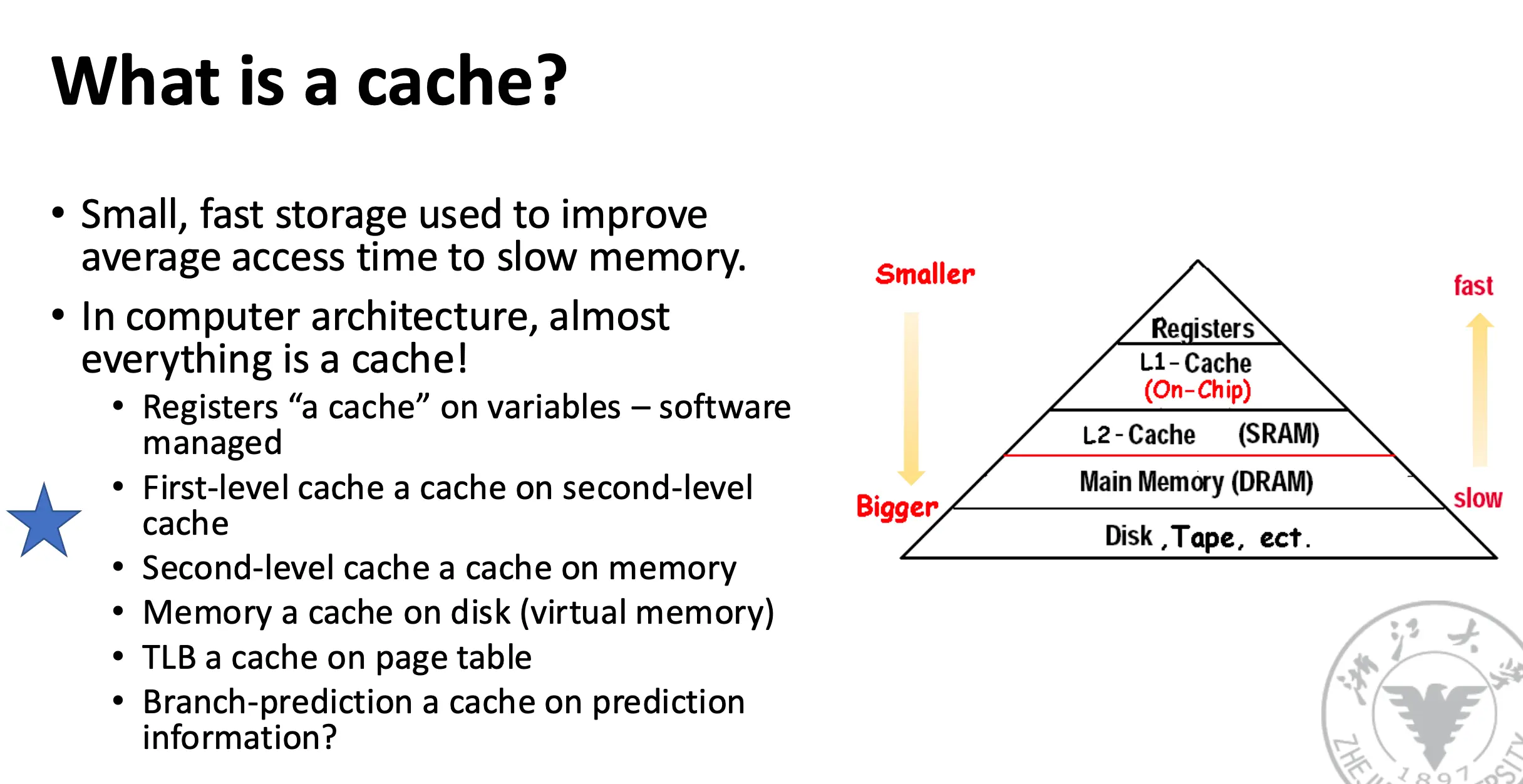
Cache:最初定义为 A safe place for hiding or storing things.
- 地址离开处理器后访问的第一个/最高的内存层次结构;
- 利用缓冲技术复用常用的数据项,提升访问速度。
Cache Hit/Miss:处理器能/不能在缓存中找到请求的数据。性能指标包括:命中率/Hit Rate、缺失率/Miss Rate、命中时间/Hit Time、缺失惩罚/Miss Penalty。
Block/Line Run:对 Cache 管理的基本单位。A fixed collection of data containing the requested word, received from the main memory and placed into the cache.
Cache 充分利用了内存架构的局部性原理:
- 时间局部性:访问过的数据在时间尺度上很快就会被再次访问;
- 空间局部性:接下来需要访问的数据很可能是和当前访问的数据是临近的。
缓存缺失的时间开销来自于两个方面:
- 响应时间/Latency:获取该块的第一个字的时间;
- 带宽/Bandwidth:获取该块的剩余字的时间。
缓存缺失的原因:
- 强制性缺失/Compulsory:第一次引用对应的数据块的时候会发生;
- 容量性缺失/Capacity:缓存空间有限,数据块被丢弃后又被访问;
- 冲突性缺失/Conflict:程序重复引用映射到缓存的同一位置的不同数据块。
缓存的本质是用于提升对慢速内存访问时间的小型快速存储器,在计算机架构中无处不在,比如:
- 寄存器:软件管理着的变量的缓存;
- 一级缓存是二级缓存的缓存;
- 二级缓存是主存的缓存;
- 内存是磁盘/虚拟内存的缓存;
- TLB 是页表的缓存,分支预测器甚至是指令缓存的缓存。
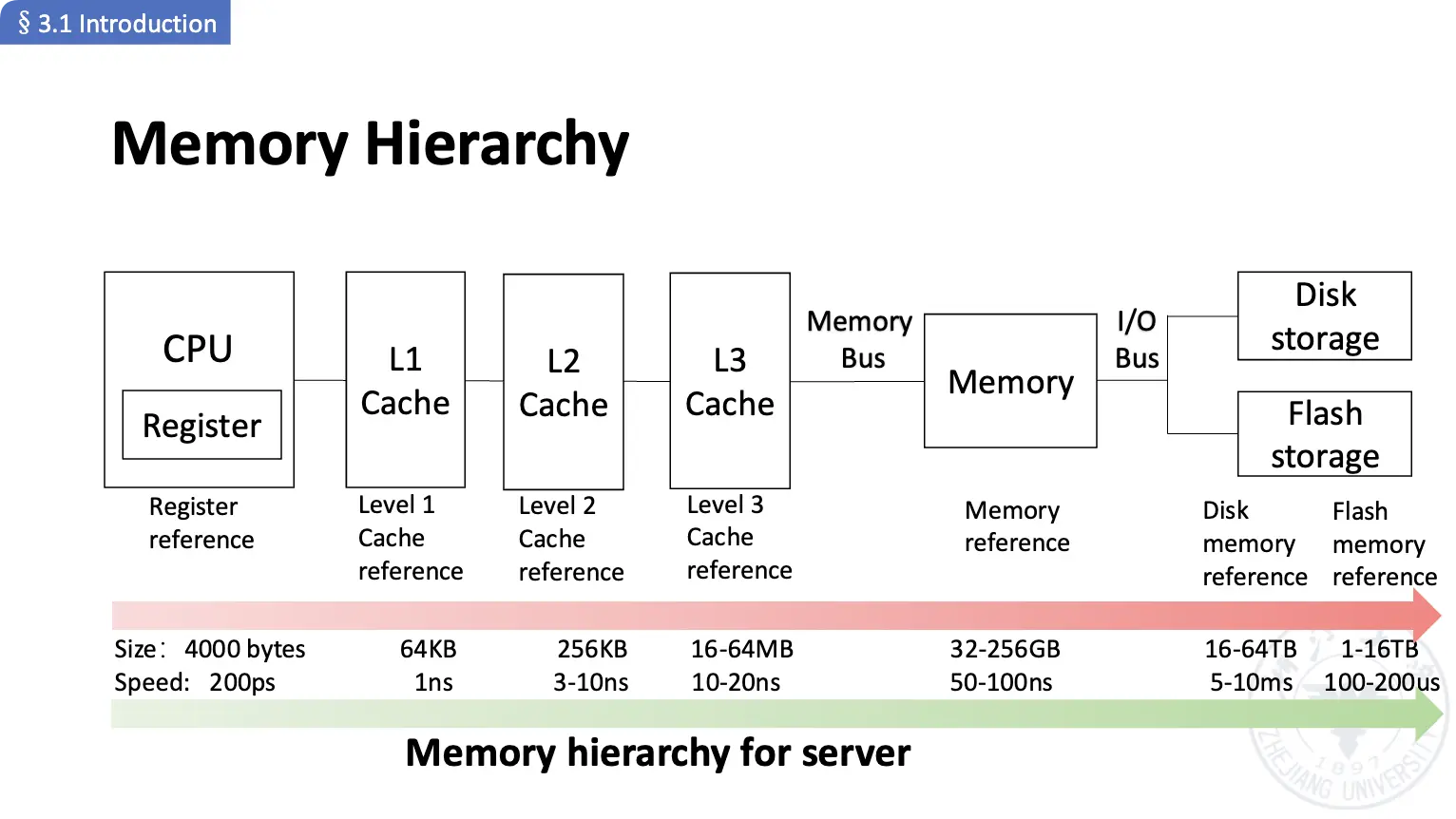
下面是一个典型的内存系统:
Cache 设计的核心问题:我们如何知道访问的数据是否在 Cache 内?如果在的话,我们怎么知道它在 Cache 的哪个位置?如果不在的话,我们应该将哪些数据块从缓存中丢弃?往 Cache 内写数据的时候都发生了什么?
3. Block Placement¶
Where can a block be placed in the upper level/main memory?
Fully Associative, Set Associative, Direct Mapped
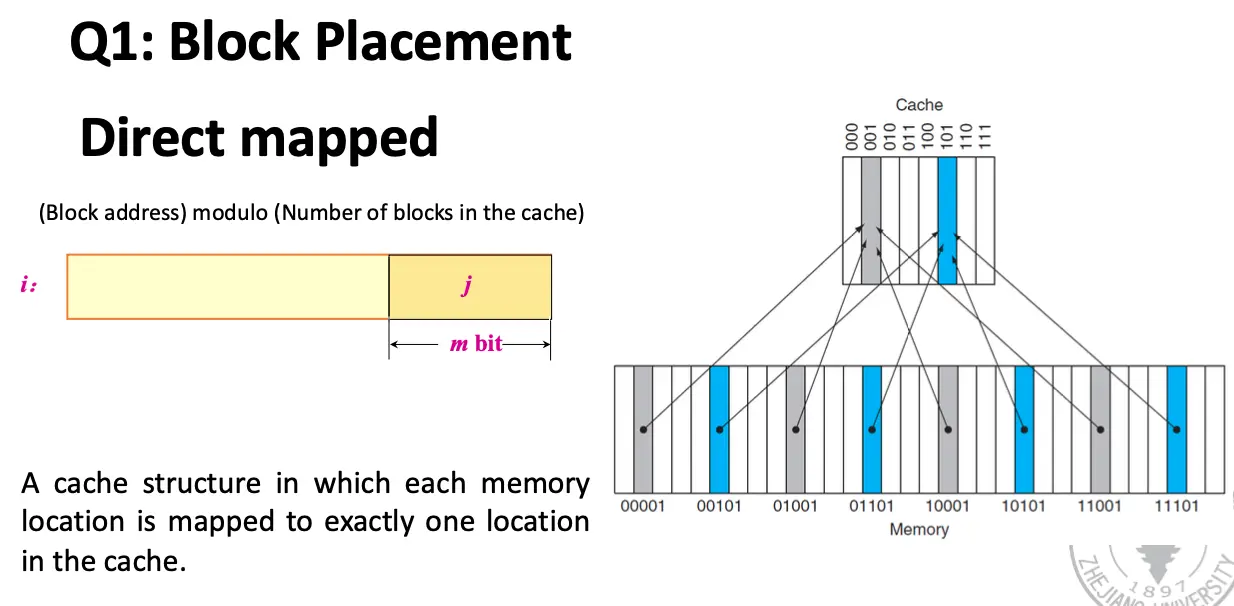
Direct Mapped/直接映射缓存:一个内存块只能出现在缓存的一个特定的位置,映射函数通常是 \(\mathrm{Cache Index} = \mathrm{Block Address} \mod \mathrm{Cache Size}\)。
Fully Associative/全相联缓存:一个内存块可以出现在缓存的任何一个位置,不需要考虑映射函数,需要遍历整个缓存才可以找到。
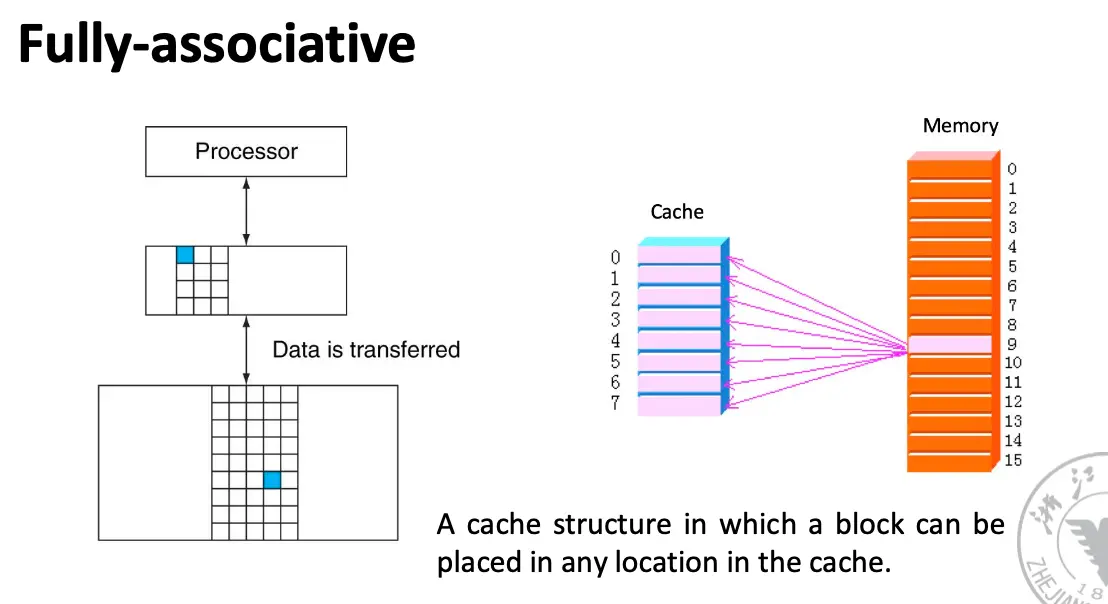
Set Associative/组相联缓存:一个内存块可以放在缓存中由有限个位置组成的组/Set 内,块首先映射到组,然后这个块可以放在这个组中的任何一个位置,通常是通过位选择的方式来选择组,一般通过高位选择 \(\mathrm{Cache Index} = \mathrm{Block Address} \mod \mathrm{Set Size}\)。
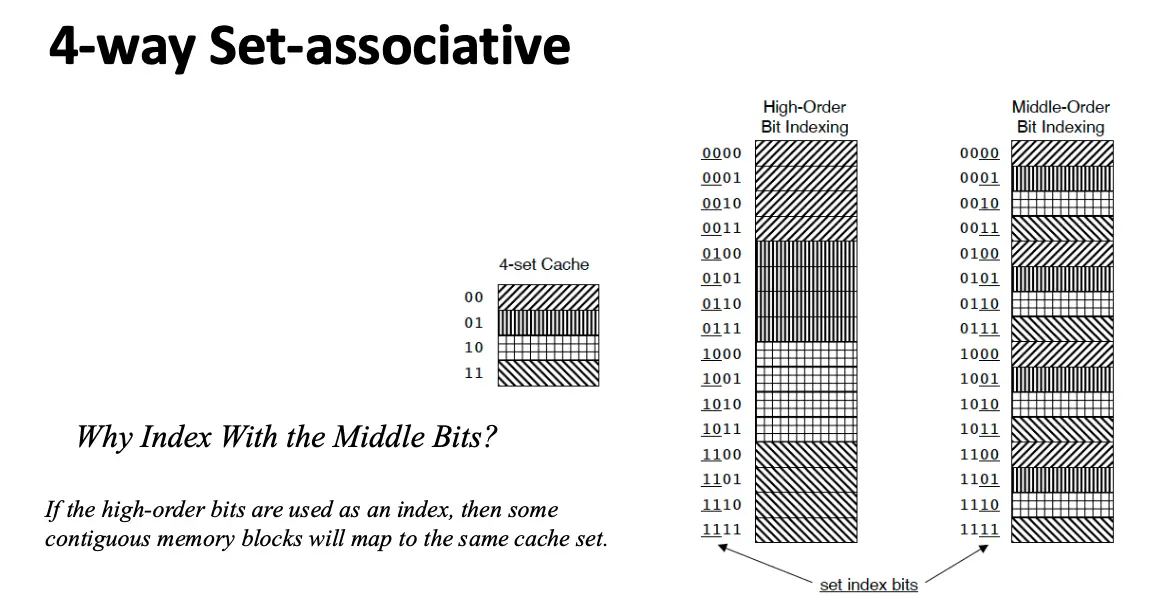
这个例子提到了使用中间位进行选择,这是因为如果使用高位进行选择,那么一些连续的内存块将会映射到同一个缓存组,导致严重的冲突。
直接映射缓存相当于 1 路组相联缓存,全相联缓存相当于 m 路组相联缓存。
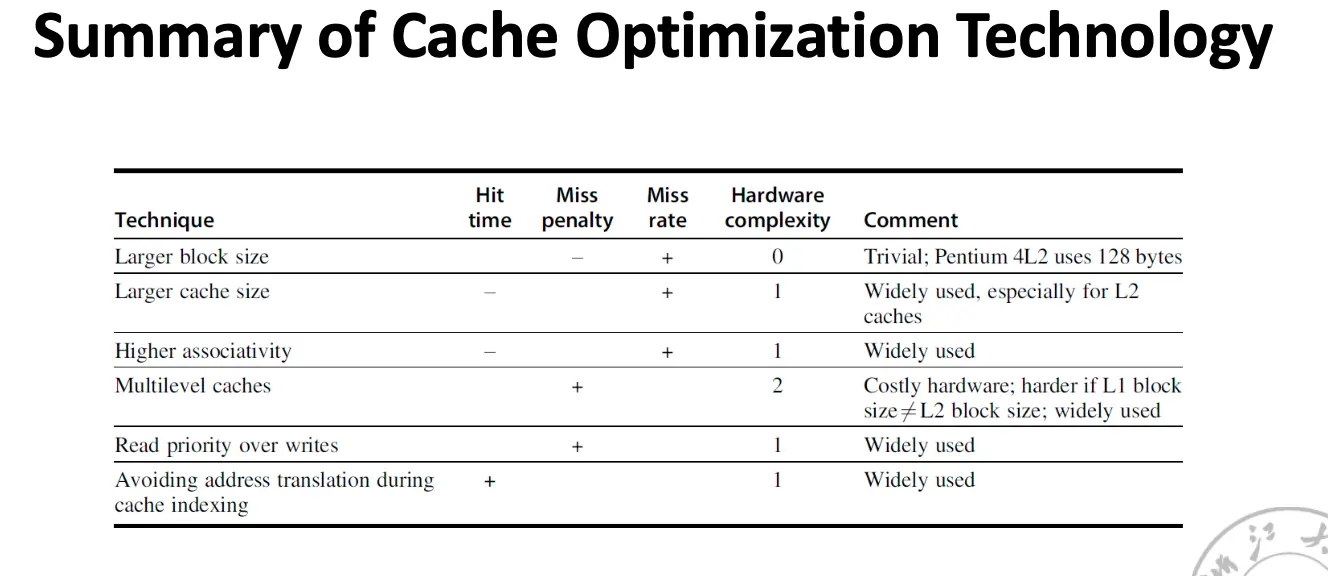
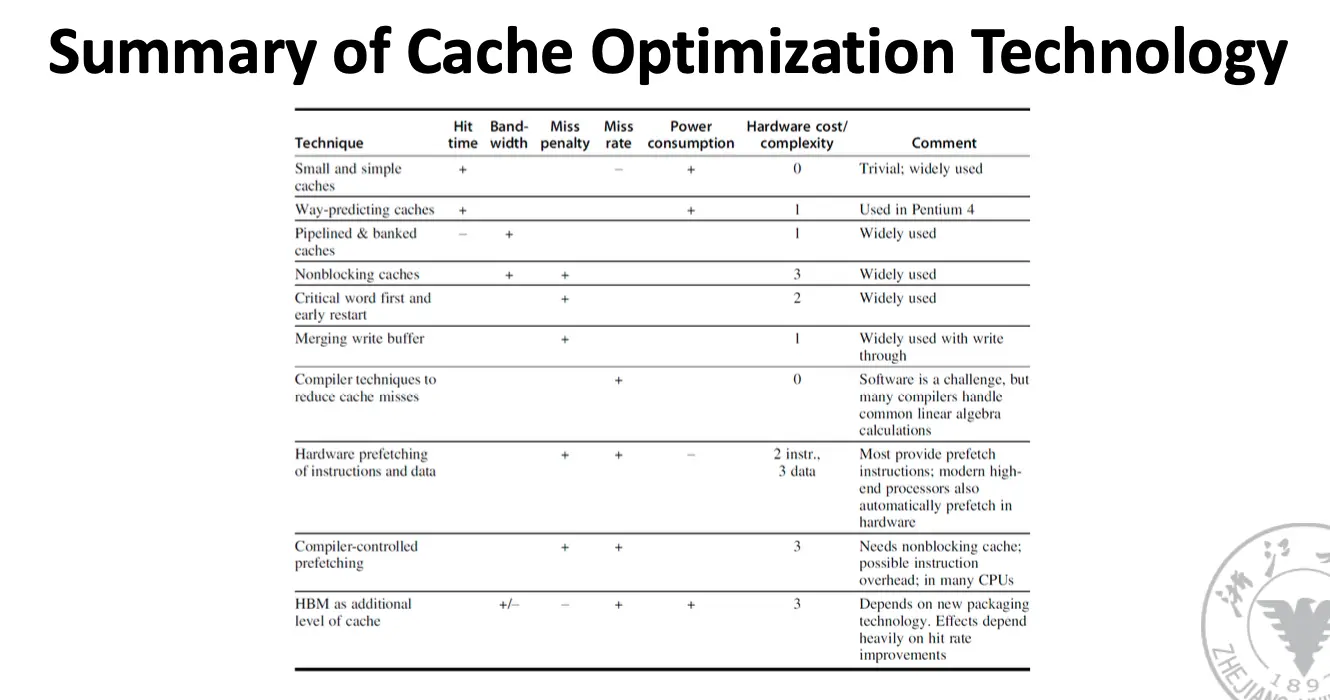
一般来讲,相连程度越高,缓存空间的利用率就越高,缓存块冲突的概率就越低,缓存未命中的概率就越低,但是正如下面一节所讲,查询效率就会越低,硬件实现更加复杂,成本越高。
4. Block Identification¶
How is a block found if it is in the upper level/main memory?
Tag/Block Number
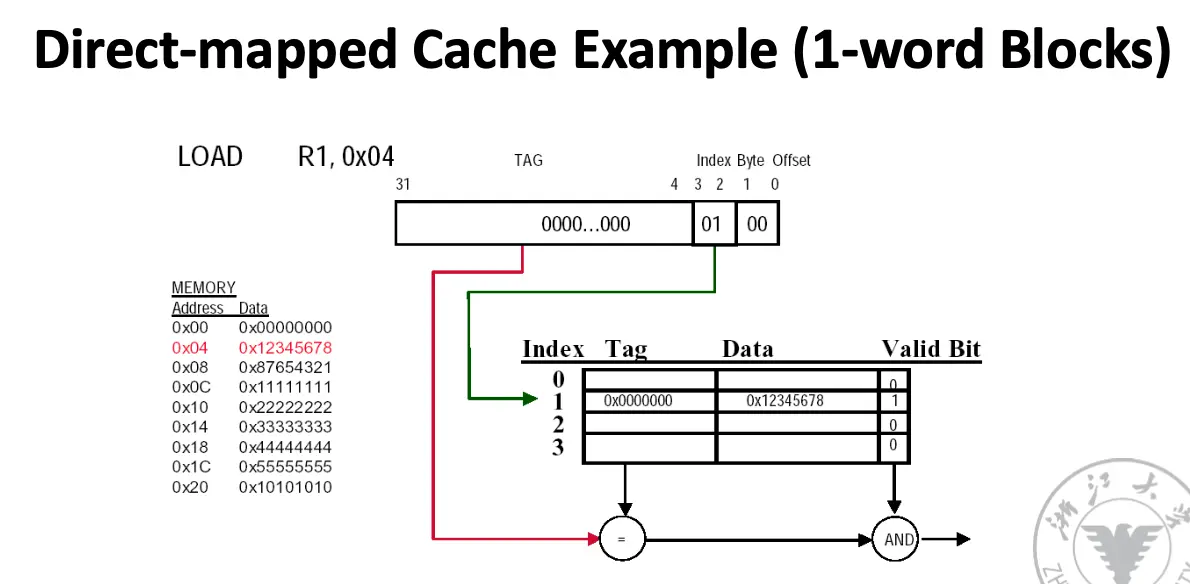
宏观来讲,我们可以将物理地址分为两个部分,分别是块地址和块内偏移,块地址用于选择缓存组,块内偏移用于选择缓存块内的字节。具体如何选择缓存组,我们将块地址又分为标记字段/Tag 和索引字段/Index。块偏移字段在块内选择所需数据,索引字段选择组,标记字段用来比较判断是否命中。

块内偏移有 \(\log_2 \operatorname*{sizeof}(\text{block})\) 位(这个 \(\operatorname*{sizeof}\) 表示的是字节数,因此如果块大小为 4 字节/一个字,那么块内偏移就两位),索引字段有 \(\log_2 \operatorname*{numberof}(\text{sets})\) 位(对于组相连)或者 \(\log_2 \operatorname*{numberof}(\text{blocks})\) 位(对于直接映射),剩下的全是标记字段。
除此之外,缓存内还需要添加一个有效位/Valid Bit,用于标记缓存块中的数据是否有效/是否包含有效地址,如果没有设置这个位,那么地址将无法匹配。下面指示了匹配方法:

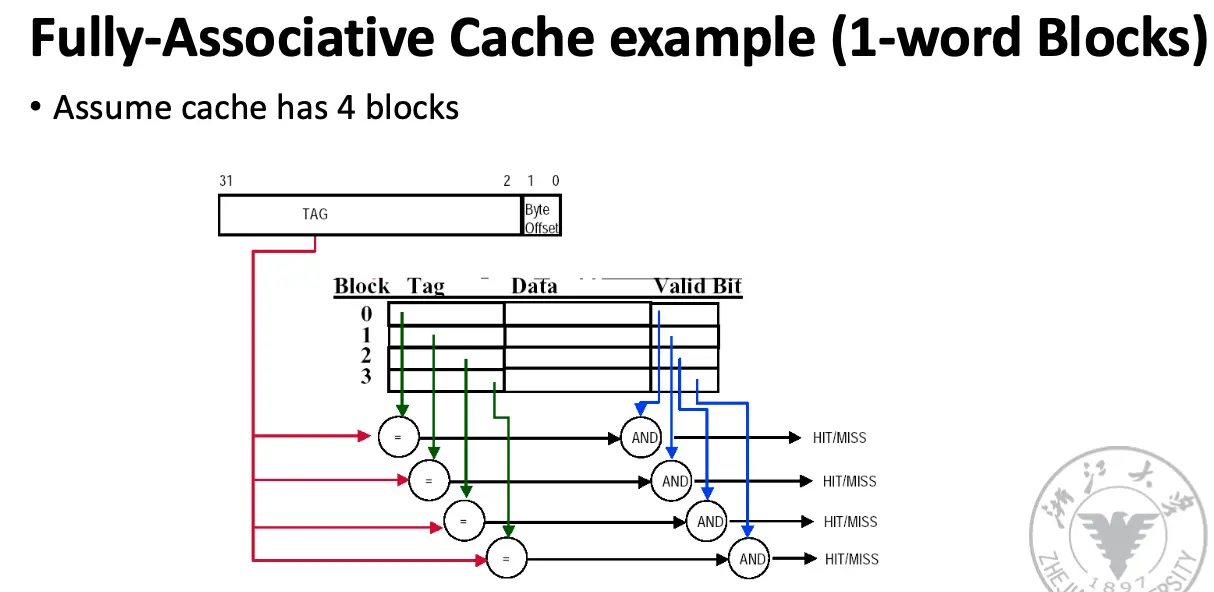
可以看见,对于全相联缓存,其实没有了索引字段,需要并行(最好并行)比较所有缓存块的标记字段。
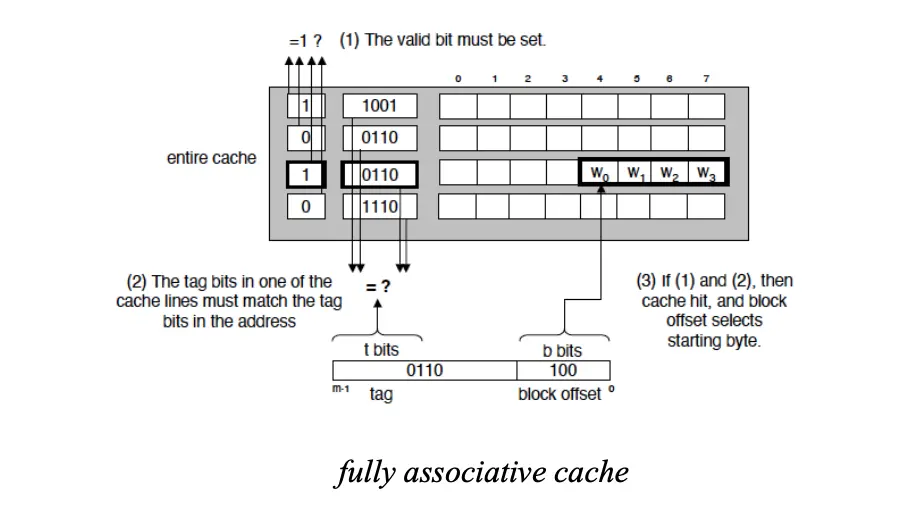
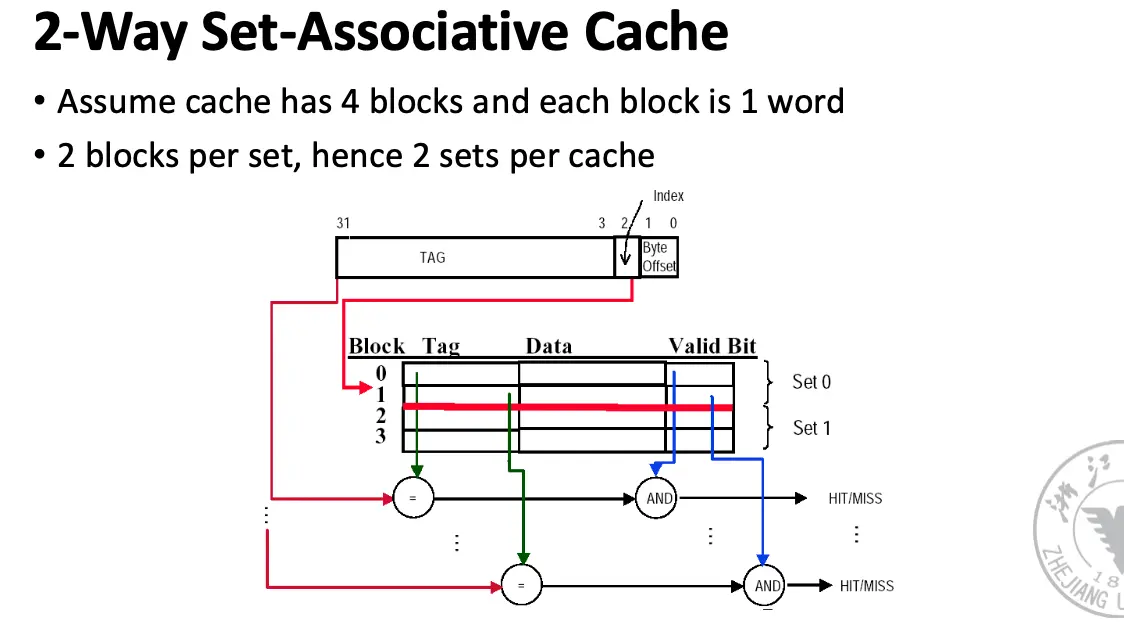
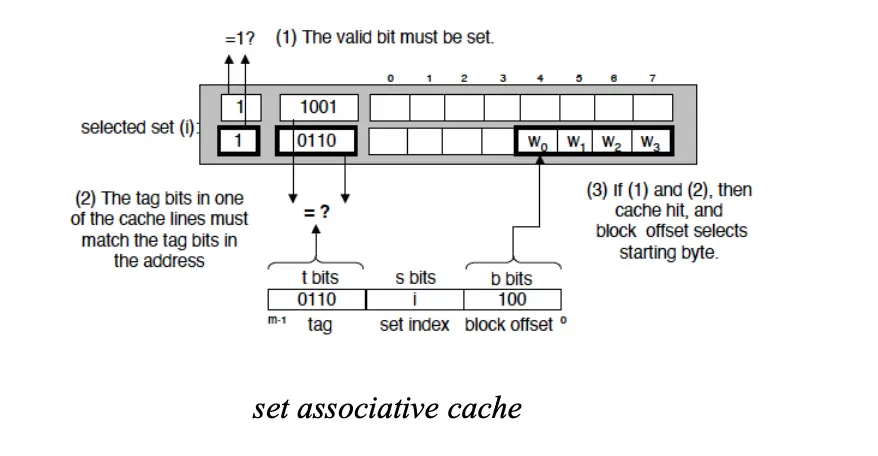


涉及计算细节如下:
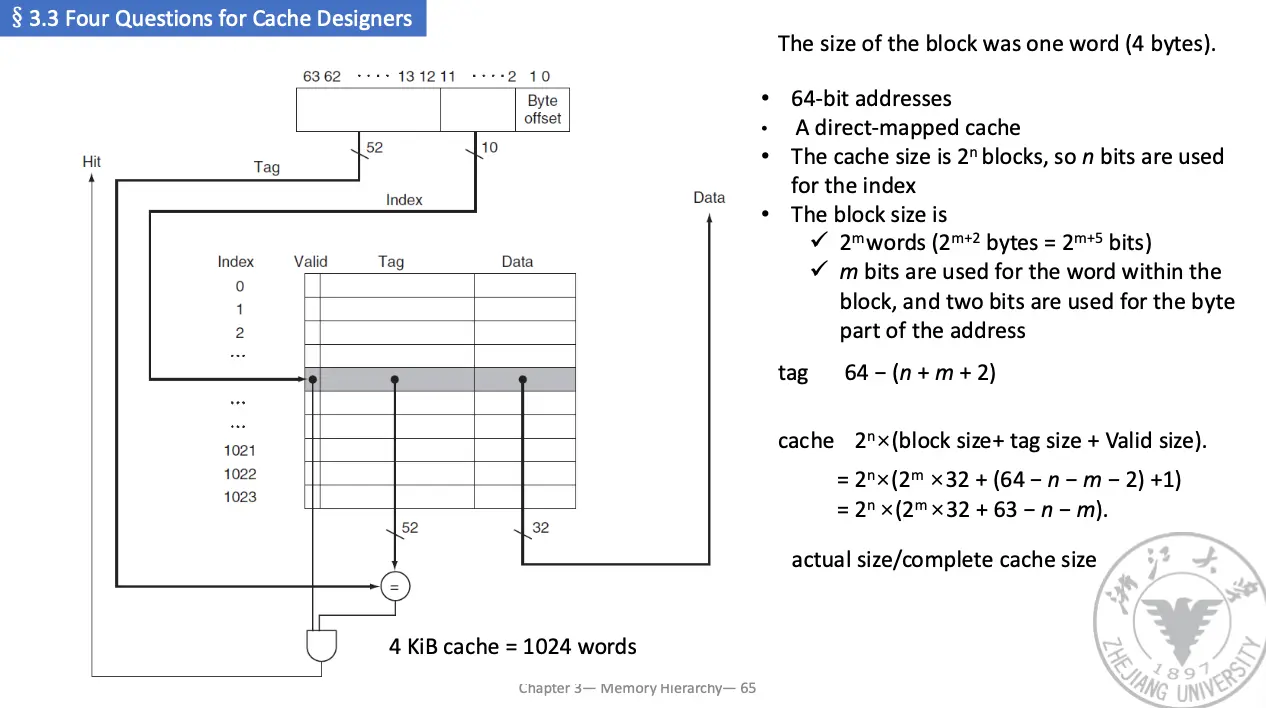
时刻记住块偏移实际上是记载的字节偏移,表示数据在缓存的第几个字节,因此块地址实际上的计算方法为物理地址除以块的字节数目。
5. Block Replacement¶
Which block should be replaced on a Cache/main memory miss?
Random, LRU, FIFO
对于直接映射缓存,由于一个块只能映射到一个缓存组,因此 Cache Miss 的时候替换策略很简单,就是直接替换,无需选择,非常简单。对于其余的缓存,由于一个块可以映射到多个缓存组,因此需要选择一个块进行替换,这就有很多种替换策略。典型的有三种:
- Random:随机选择一个块替换,实现简单,只需要一个随机数生成器,可以将数据均匀的分布在缓存中,但是可能把一个将要被访问的块替换掉;
- LRU:最近最少使用,选择最近一段时间内没有被访问的/最少被访问的/最久没有被访问的块替换掉,这假设了时间局部性,也就是最近被访问的块更有可能在不久的将来被再次访问,但是需要在 Cache 中添加额外的位;
- FIFO:先进先出,选择最早进入缓存的块替换掉,在某种程度上也假设了时间局部性,也需要额外的数据位,但是实现相对简单。
假设缓存块大小为 3,访问序列为 2, 3, 2, 1, 5, 2, 4, 5, 3, 4,那么我们可以得到下面的替换过程:
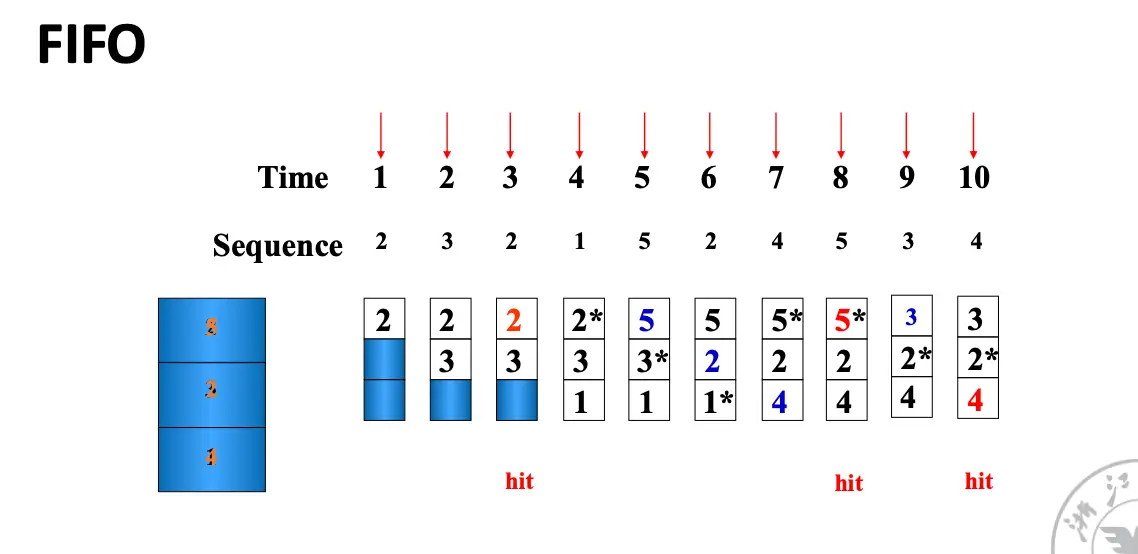
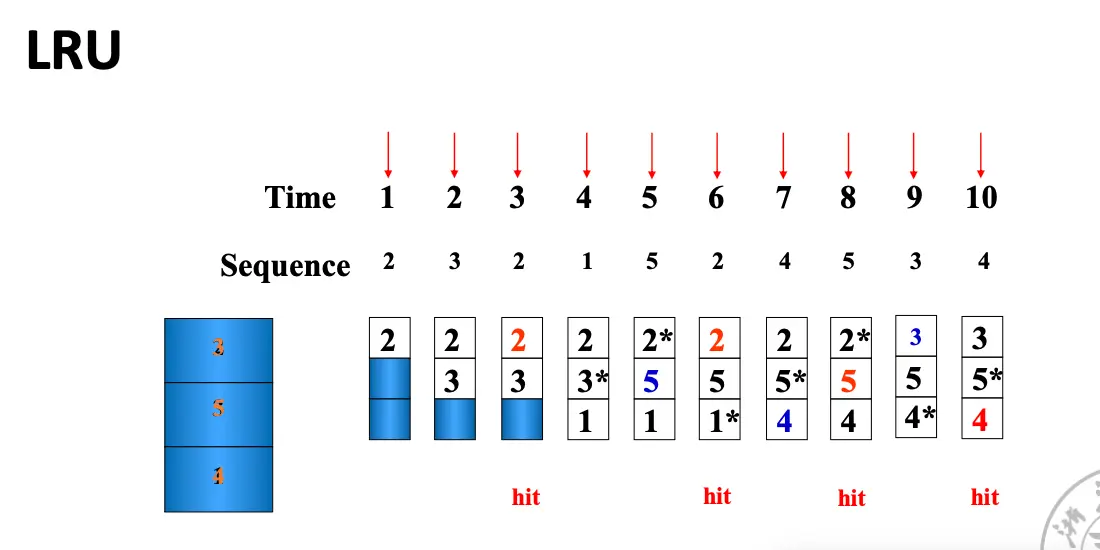
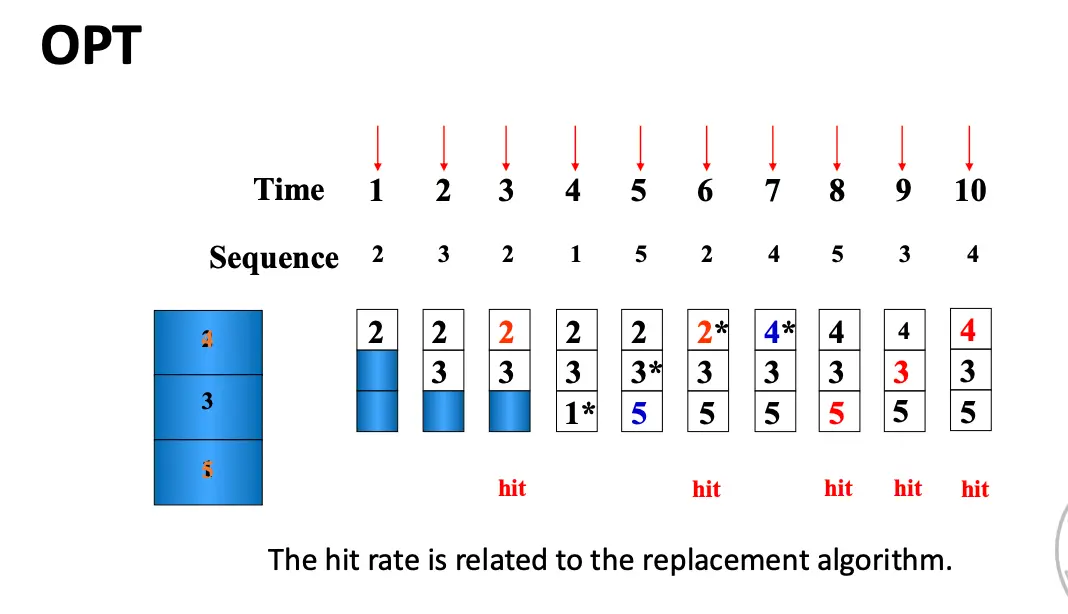
命中率很很多因素都有关系,包括缓存块数目、替换算法、访问序列等。甚至有的神人算法随着缓存块数目增大,命中率反而下降,这就是著名的Belady 异常。对于那些缓存块数目增大,命中率不下降的算法为栈替换算法/Stack Replacement Algorithm。
令 \(B_t(n)\) 表示在时间 \(t\) 时,大小为 \(n\) 的缓存块中包含的访问序列。如果 \(B_t(n) \subset B_t(n+1)\),那么这个算法就是一个栈替换算法。
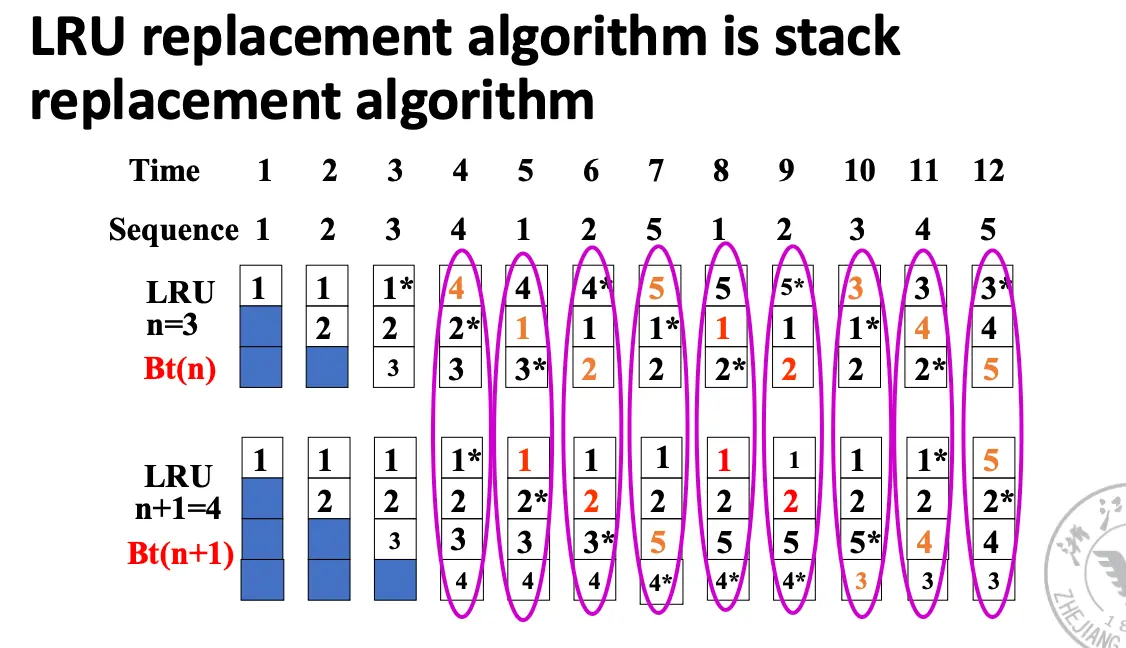
LRU 算法是栈替换算法,FIFO 算法不是栈替换算法。
可以用栈来模拟 LRU,栈顶是最近访问的,栈底是最久未访问的,每次要替换的时候,替换栈底的元素。
可以只使用门和触发器来实现 LRU 算法:让所有的 Cache 块两两结对,使用一个触发器来记录这两个块最近的访问次序(例如 \(T_{AB}\) 为 1 表示 A 比 B 最近被访问过,0 表示 B 比 A 最近被访问过),然后使用门电路将每个触发器的状态结合起来,就可以找到最久没有被访问的块了。其实是利用了序关系。
6. Write Strategy¶
What happens on a write?
Write-through, Write-back
一张图解决:
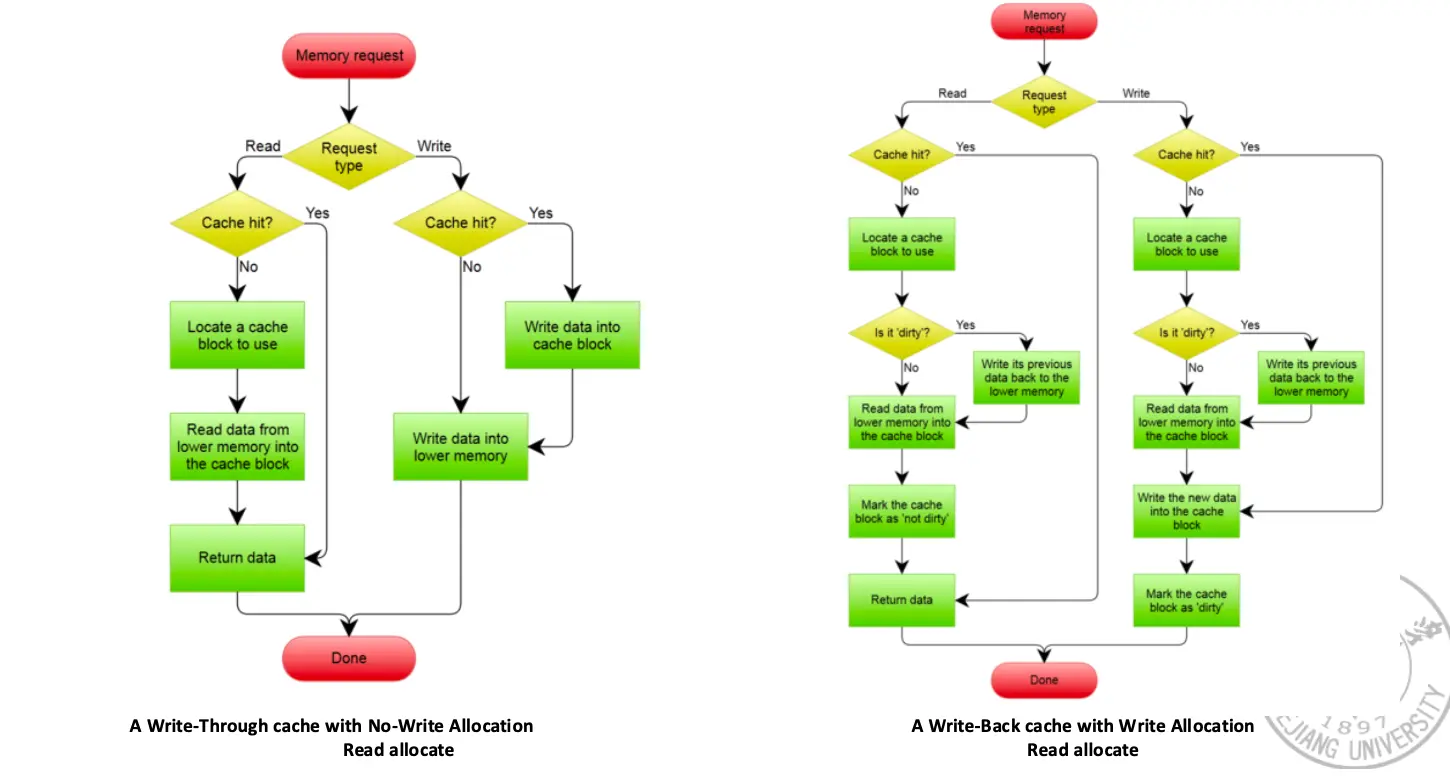
详细来说,总体根据写操作是否同时写入内存分为两种策略:
- Write Through/写直达:直接把数据同时写入 Cache 和主存中,只需要一个 Valid Bit,内存总是有最新的数据,实现相对简单,读操作 Miss 不会导致写操作,内存结构一致;
- Write Back/写回:只写入 Cache,不写入主存,只有当 Cache 块被替换出去时,才需要写回主存,需要一个 Dirty Bit 指示 Cache 块是否被修改过,实现相对复杂,写速度快,就是访问缓存的速度,同时对带宽要求低;
上面两种分类是针对写操作 Cache Hit 的,对于写操作 Cache Miss 的情况也分两种:
- Write Allocate/写分配:将数据对应的块加载到 Cache 后再写;
- No Write Allocate/不写分配/Write Around:直接往内存写。
总的来说,写直达一般和不写分配一起使用,写回一般和写分配一起使用。
我们仍然知道,在执行写操作的时候,CPU 必须等待,流水线必须停顿,直到写操作完成,解决方法是加一个 buffer,虽然不完全消除等待,但是确实有帮助。
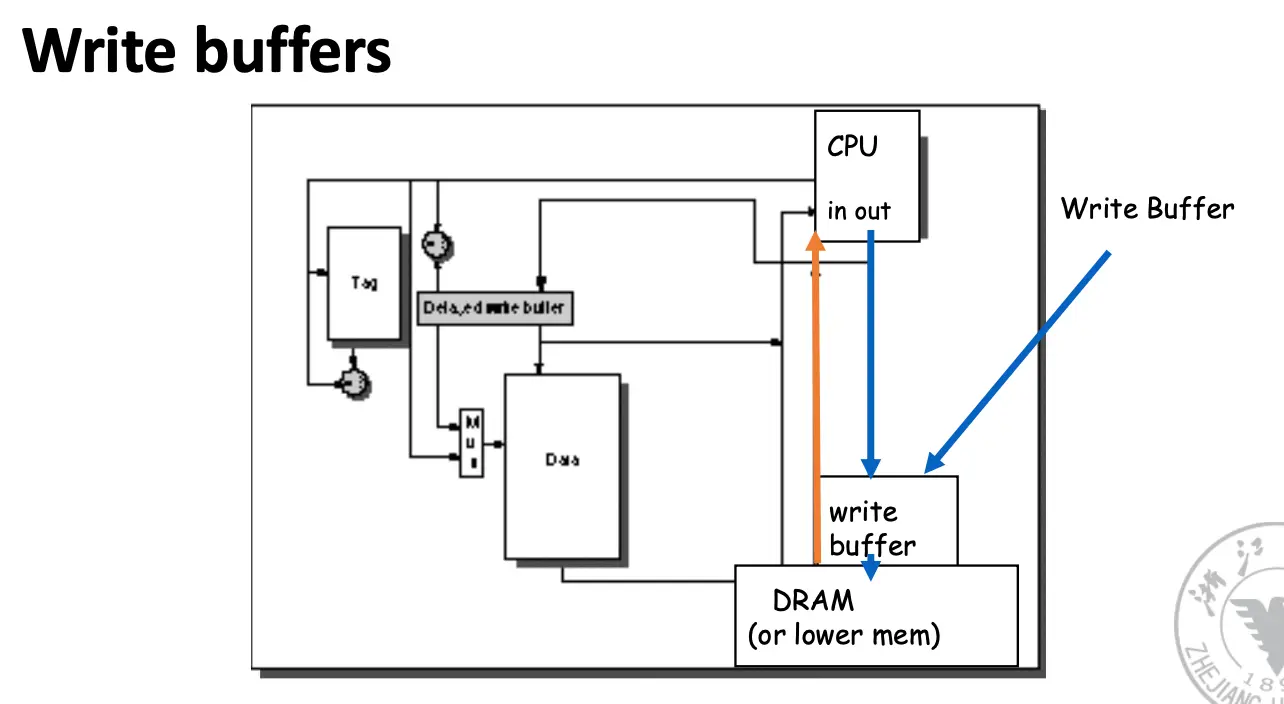
下面是例子了:

7. Memory System Performance¶

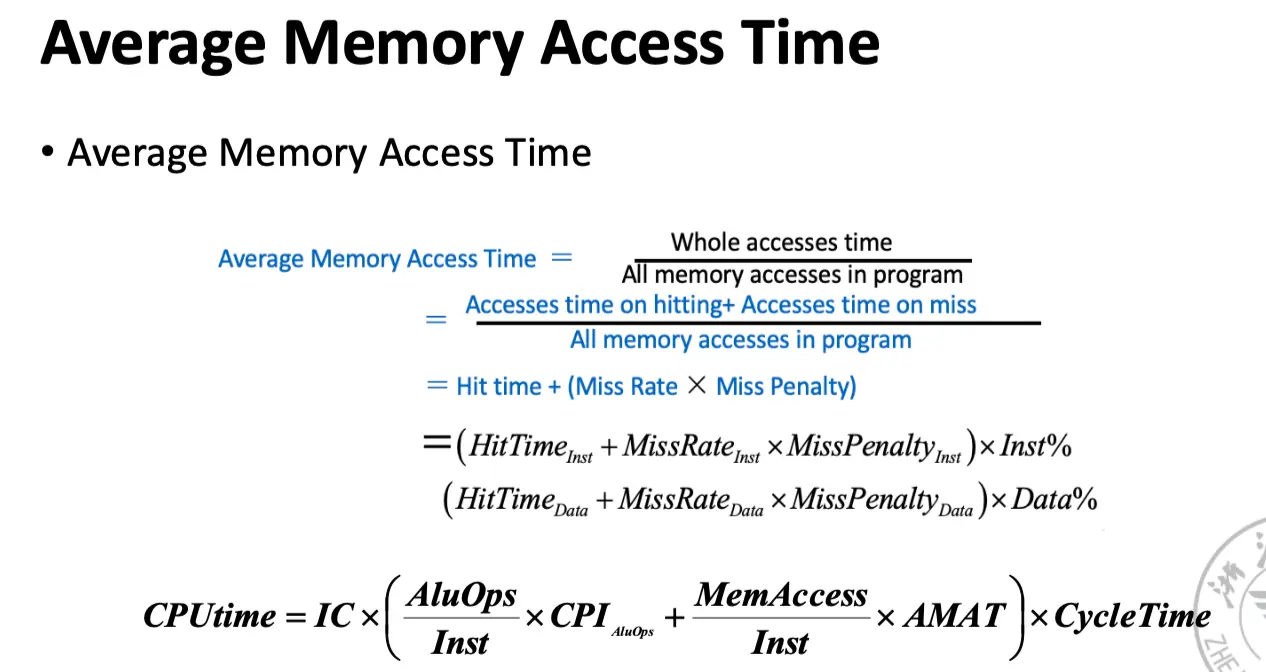
How to Improve?
- Reduce the miss penalty;
- Reduce the miss rate;
- Reduce the time to hit in the cache;
- Reduce the miss penalty and miss rate via parallelism.