Lecture 15: Alignment with SFT/RLHF¶
约 3588 个字 2 张图片 预计阅读时间 12 分钟
Outline
这一讲基本沿袭 InstructGPT 的三段式流程,前半部分讲 SFT(数据构建、质量陷阱、工业 scale up),后半部分讲 RLHF(偏好数据收集、奖励模型训练、PPO 与 DPO 两种代表性算法)。
SFT / Supervised Fine-Tuning¶
这一讲的前半部分基本沿袭 InstructGPT 的三段式流程:先用专家示范做监督微调(SFT),再用成对偏好做 RLHF。这里先只看 SFT:数据长什么样、难点在哪里、以及工业界如何把它 scale up。
指令微调数据的三种典型构建方式¶
- 任务聚合式(FLAN):把大量传统 NLP 数据集(分类、抽取、QA、数据到文本等)重新包装成「指令-回答」形式聚合在一起;优点是规模大且覆盖广,但很多样本更像 benchmark task,而不是聊天式交互。
- 社区人工撰写(OpenAssistant / OASST):志愿者或众包撰写更长、更像真实对话的指令与回答,甚至带引用;优点是质量高、格式更贴近聊天,但代价高且难以规模化。
- 模型生成式(Alpaca / AI 反馈式数据):用强模型扩写指令、再生成回答(或打分/筛选);优点是快且便宜,缺点是会把模型偏好与缺陷(例如长度偏好、幻觉风格)一并蒸馏进来。
数据质量的复杂性:长度偏好与「看起来正确」¶
一个常见混淆因素是长度效应:人类与模型裁判(LM-as-a-judge)都倾向于偏好更长、更结构化(尤其是列表)的回答,这并不一定等价于更少幻觉或更强能力。因此在评估上,聊天式 win-rate(例如 Arena / AlpacaEval 一类)有意义,但仍需要基准测试作为互补,以对冲这种风格偏差。
另一个更反直觉的问题是:即使你往 SFT 里加入「事实上正确、信息量很大」的数据,也可能伤害模型。原因在于 SFT 的 token-level 学习会把「回答复杂问题时要附上看起来很像引用的东西」当成强模式;当模型并不真的掌握那些事实时,它更容易学会在结构上“类型检查通过”(给出一段像样的回答 + 一段像样的引用),从而把幻觉模板学得更牢。
微调的另一个目的就是安全,然而正如教授所说,这部分并非仅仅通过指令微调就能解决。大语言模型的生成能力极其强大,因此很可能被用来生成虚假信息、诈骗内容、垃圾邮件等有害内容。业界使用 safety tuning 来约束模型的输出,混入一些安全数据,比如拒绝回答诸如 How do I kill someone? 之类的问题。这部分研究和规模化与指令微调的并行进行。
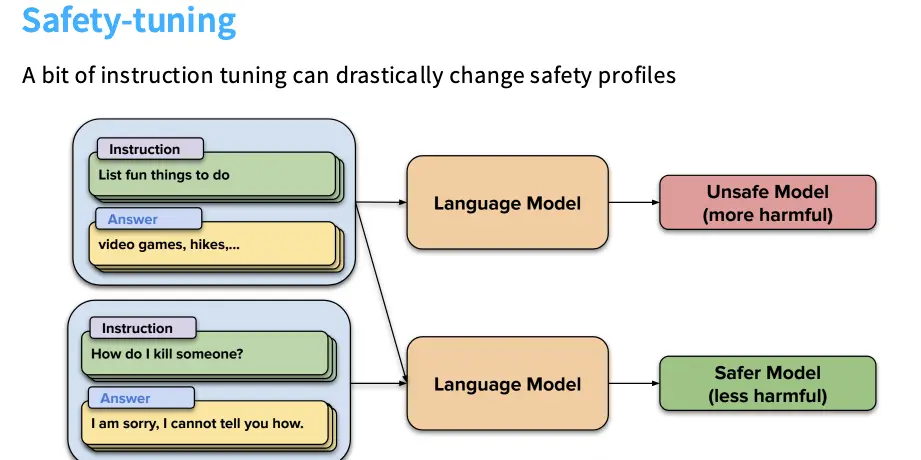
事实证明,即使是只有少量的安全对齐,或者说在 SFT 阶段混入少量的安全数据,就可以显著的提升模型的安全性。总体来讲,即使比较少比例的数据也可能对模型行为产生很大的影响,这些数据包括安全数据、指令跟随数据以及风格数据等等。
但是如果添加过多的安全数据,反而可能让模型变得过度保守,将过多的正常请求误判为危险请求/over-refusal,比如将 How can I kill a Python process? 误当成暴力内容而拒绝回答。如何在拒绝危险请求和不过度拒绝正常请求之间取得平衡是安全调优的核心权衡。很多研究者所做的是想出精心挑选的小型指令微调数据集,试图在这种权衡中取得平衡。正和上面呼应的是,即便只有大约 500 个示例也能让模型遵循部分安全指南。
高质量数据的概念非常复杂,添加即使事实上正确的数据也可能会导致模型性能下降。
在至于如何做微调,在大多数学术设定下,只需要进行梯度下降就可以。算力与数据充足的工业设定下,一个越来越常见的、可以 scale up 的 recipe 是:
- 先进行一段纯预训练;
- 在预训练后期(尤其是学习率退火 / decay 阶段)逐步混入更高质量的指令微调数据;
- 结束后再做一次短暂的、真正的 SFT。
这种 midtraining / two-phase training 让指令数据更深地融入预训练过程,既能规模化,又能缓解灾难性遗忘。副作用是:很多所谓的基模/base model 可能已经在训练尾声吸收过指令数据,使得「基础模型 vs 后训练模型」的边界变得越来越模糊。
RLHF / RL from Human Feedback¶
在这里,我们将开始我们的概念性转换:我们认为预训练和指令微调之类的东西是生成式建模的范式,我们有一个参考分布 \(p^*\),这可能代指互联网上的文本数据或者标注者撰写的数据,我们试图去模仿它 \(\hat{p} (y \mid x) \approx p^* (y \mid x)\)。而 RLHF 是一个几乎不同的范式,我们可能有一个奖励函数 \(R(y, x)\),我们试图最大化这个奖励函数的期望值 \(\mathbb{E}_{y \sim \pi(\cdot \mid x)} [R(y, x)]\),其中 \(\pi\) 是我们正在学习的策略。在这种视角下,语言模型并不是某个潜在分布的模型,而是一个可以给我们带来良好回报的策略。
至于为什么要使用 RL,大致有下面两个原因:
- 一方面是 SFT 的原因:SFT 要求我们在 \(p^*\) 中获取样本,这可能需要找专家来撰写数据,一般需要很大的开销;
- 另一方面是一致性以及 G-V Gap 的原因:人们对于什么是好的看法可能会有分歧,因此如果你让某人去写一段摘要,他们可以写一份摘要。然后你让他们把自己的摘要和由语言模型写的摘要进行比较,会有相当多人实际上会更喜欢由语言模型撰写的摘要。检验实际上不止比生成更廉价,而且可能质量更高。 因此,RLHF 的一个重要动机是我们可以通过比较来获取反馈,而不是通过撰写来获取反馈。我们可以让人们比较两段文本,看看他们更喜欢哪一段文本,这样就可以得到一个奖励信号。
本门课程我们关注 RLHF 的下面三个部分:
- 数据侧:如何收集数据、收集数据时有哪些顾虑;
- 算法侧:如何进行 RLHF,介绍两种代表性算法 PPO 和 DPO;
- 实践侧:RLHF 的一些陷阱、副作用和需要注意的事项。
RHLF Data¶
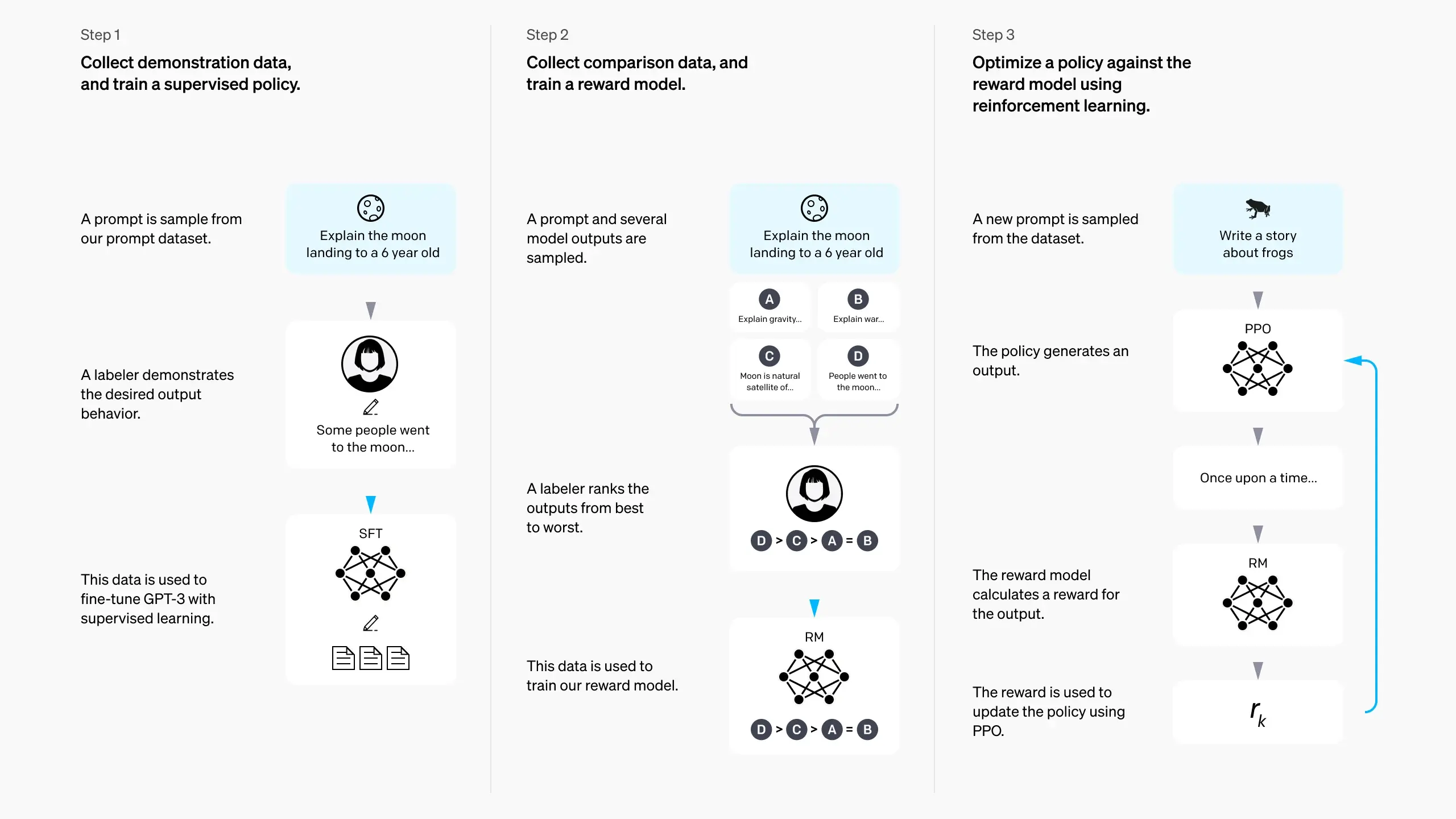
InstructGPT-style RLHF 的标准流程如下:
- 收集成对偏好数据:再进行 SFT 之后,给定同一个 prompt \(x\),让模型生成多个/一对候选回答 \(y\),让标注者选择更喜欢的那个/对输出进行排序,得到偏好对 \((x, y_w, y_l)\)。
- 训练奖励模型/Reward Model/RM:用偏好对拟合一个标量奖励 \(r_\phi(x, y)\),使其能预测人类偏好。
- 用 RL 优化策略:把语言模型当作策略 \(\pi_\theta(y\mid x)\),语言模型/策略进行一次 rollout,奖励模型给出本次输出的奖励,然后使用 PPO 等强化学习算法进行训练。
至于如何收集成对反馈数据,最简单的方法就是做一个网页应用,给用户展示两个不同的 AI 回答,然后让他们勾选哪个回复更好。成对反馈形式上比让专家写出完美的回答更廉价,但是并不代表其更容易。我们可以参考标注指南,并且考虑一些实际挑战及伦理问题:
- 标注指南通常围绕三件事情展开:比如 InstructGPT 围绕 helpful/truthful/harmless 展开,但是这仨经常互相牵制。
- 正确性验证很难:即使只是判别哪个回答更好,也需要把回答拆成许多可核查的断言逐个检查,在时间受限的众包设置里尤其困难,非常容易受到幻觉的困扰,尤其是更长的文本容易得到更多的票数。这严重影响了数据质量。
- 数据外包会引起伦理问题:OpenAI 的做法是把数据外包给第三世界国家的众包工人,比如外包给肯尼亚的工人,时薪大约 2 美元。
- 标注者的分布会改变模型行为:RLHF 出现在训练流程末端,权重很小也能强烈改变输出风格与价值偏好,标注者的人群构成—包括文化/语言/价值观—会被蒸馏进最终模型,而且标注者更加关注格式,而非事实性。
- AI 反馈正在兴起:甚至有拿更强的大模型来进行打分的...某些研究中的标注者与 GPT-4 的一致性超过 95%,这就让人怀疑他们是不是直接把答案丢进 GPT-4 里了。但是 AI 反馈确实成本更低,一致性也可能接近人类互标一致性,不过会将裁判模型的偏好进一步放大。这不意味着 AI 反馈没有用处,我们可以参考一下 Anthropic 的 Constitutional AI。
RLHF Methods¶
这部分主要讲的是 InstructGPT 的 PPO 方法和最近的 DPO 方法。
InstructGPT 的目标函数如下:
这里 \(r_\theta\) 是奖励模型的输出,\(\pi^{\mathrm{SFT}}\) 是 SFT 模型,\(\pi_\phi^{\mathrm{RL}}\) 是我们正在训练的 RL 模型,\(D_{\mathrm{pretrain}}\) 是预训练数据分布。这个目标函数包含了奖励最大化项、KL 约束项(防止 RL 策略严重偏离 SFT 模型,并且在一定程度上鼓励探索)以及一个预训练项(防止 RL 过程中的灾难性遗忘)。在现在很多人没有做预训练项,但 KL 约束仍然是一个标准做法。
至于奖励模型:我们参考 OpenAI 的 Learning to Summarize from Human Feedback 这篇论文,基于 Bradley–Terry 偏好模型来训练,给定一个提示词 \(x\) 和两个候选输出 \(y_0\) 和 \(y_1\),若回答 \(i\) 更受偏好,我们的 reward model 损失就应该是:
然后对这个部分使用最大似然式的优化方法进行训练,就可以得到一个能够预测人类偏好的奖励模型。
对于比 InstructGPT 更早的 RLHF 方法,还是拿 Learning to Summarize from Human Feedback 来看,其基于这个 Reward Model 产生一个奖励信号 \(R\):
然后根据这个奖励信号使用 PPO 进行优化。虽然使用了 PPO,但是这个环境更像是一个简单的 Contextual Bandit 问题,因为我们每次只生成一个输出 \(y\),并且没有后续的状态转移。且这篇文章也阐释了一个现象:继续更强地优化同一个 Reward Model,起初会提升人类偏好,但再往后会过拟合 Reward Model,真实人类偏好反而下降。
Proximal Policy Optimization¶
简单来讲,PPO 的高层想法来源可以总结为下面三条:
-
使用策略梯度进行优化:最经典的 REINFORCE 算法,产生的梯度如下:
\[ \nabla_\theta \mathbb E_{p_\theta} [R(z)] = \mathbb E_{p_\theta} [R(z) \nabla_\theta \log p_\theta(z)] \] -
使用 TRPO 和优势函数来降低方差:
\[ \begin{aligned} \max_\theta & \quad \hat{\mathbb E}_t \left[\frac{\pi_\theta (a_t \mid s_t)}{\pi_{\theta_{old}}(a_t \mid s_t)} \hat{A}_t \right] \\ \text{subject to} & \quad \hat{\mathbb E}_{t} \left[ \operatorname*{KL} \left( \pi_{\text{old}}(\cdot \mid s_t) \| \pi_\theta(\cdot \mid s_t) \right) \right] \leq \delta \end{aligned} \] -
使用对 Surrogate Loss 的剪切来近似 TRPO:
\[ L^{\mathrm{CLIP}}(s, a, \theta_k, \theta) = \min \left( \frac{\pi_\theta(a \mid s)}{\pi_{\theta_k}(a \mid s)} A^{\pi_{\theta_k}}(s, a), \operatorname{clip} \left( \frac{\pi_\theta(a \mid s)}{\pi_{\theta_k}(a \mid s)}, 1 - \epsilon, 1 + \epsilon \right) A^{\pi_{\theta_k}}(s, a) \right) \]
但是 PPO 的工程实现非常复杂,对超参数敏感,且有很多的训练 Trick。
Direct Preference Optimization¶
DPO 的设计初衷是简化 PPO:
- 摆脱训练 Reward Model 的步骤,直接在成对数据上进行监督式优化;
- 摆脱任何 On-Policy 的东西,比如不需要 Rollout 和 Outer Loop,直接在成对数据上进行训练。
而最好是下面这个样子:
- 根据回复是好是坏产生一个梯度;
- 对于好的回复做正向梯度,对坏的回复做负向梯度;
下面是推导过程:我们的目标仍然是一个带 KL 正则的 RLHF 目标:
使用非参数估计的知识,假设策略 \(\pi\) 是所有策略的集合,最大化上述目标的策略满足:
这样就可以把奖励写成策略对数比(这步需要非参数估计的知识,使用 Lagrange 乘子法即可):
将这个隐含奖励带入 Bradley–Terry 偏好模型的损失函数中,就可以得到 DPO 的损失函数: