CS106L 笔记
Lecture 8:模版类
Info
注意模版类 和类模版 的区别:
类模版/Class Template :是一个模版,用于生成类的定义,编译器会使用它来实例化各种具体的类。模版类/Template Class :是一个类模版实例化后的具体类,当使用类模版定义对象时,需要指定实际的类型参数,从而生成模版类。
「this 指针」
对于如下定义的类 Point:
class Point {
public :
Point () = default ;
Point ( int x , int y ) : x ( x ), y ( y ) {}
int getX () const { return x ; }
int getY () const { return y ; }
void setX ( int x ) { this -> x = x ; }
void setY ( int y ) { this -> y = y ; }
private :
int x = 0 ;
int y = 0 ;
};
this 是一个指向当前类实例的指针,通过上个例子中的 Point::setX 函数,可以看到 this 指针的作用。
首先定义一个类模版 Vector:
template < typename T >
class Vector {
public :
T & at ( size_t index );
void push_back ( const T & elem );
private :
T * elems ;
};
模版声明:Vector 是一个模版,接受类型参数 T;
模版实例化:当使用对应的实例的时候,编译器会根据指定的具体类型生成相应的代码。
Vector < int > intVector ;
Vector < std :: string > stringVector ;
Vector<int> 和 Vector<std::string> 是 Vector 的两个实例,但是这两个实例是完全不同的。
These two instantiations (of the same template) are completely different (runtime and compile-time) types.
除了 typename,模版参数还可以是别的类型,并且在模版中,typename 和 class 是等价的。
template < typename T , std :: size_t N >
struct std :: array ;
std :: array < int , 5 > arr ; // An array of exactly 5 integers
template < class T , std :: size_t N >
struct std :: array ; // Equivalent to the above
声明成员函数的时候需要注意,对于上面类模版 Vector 而言,Vector 不是一个类型,但是 Vector<T> 是一个类型。
template < typename T >
T & Vector < T >:: at ( size_t index ) {
return elems [ index ];
}
注意类模版的实现:在 .h 文件中定义接口,在 .cpp 文件中实现对应函数,在 .h 文件的结尾 #include 对应的 .cpp 文件。
关于 const:
template < typename T >
class Vector {
public :
size_t size ();
T & at ( size_t index );
};
void printVec ( const Vector < int >& vec ) {
for ( size_t i = 0 ; i < vec . size (); ++ i ) {
std :: cout << vec . at ( i ) << std :: endl ;
}
}
我们注意到第 8 行的 const,这个 const 表示传入的 vec 是一个常量引用,我们承诺不修改 vec,但是对应的 size 和 at 函数并没有声明为 const,编译器不能确定这两个函数是否会修改 vec,所以会报错。修改成下面的样子就好了。
size_t size () const ;
T & at ( size_t index ) const ; // 更应该是 const T& at(size_t index) const;
对于 const 成员函数,传入的 this 指针是一个指向常量的指针,在上面就是 const Vector<int>* this,这样就不能在成员函数内修改成员变量了。
对于定义成 const 的对象,我们只能使用 const 接口 ,其中 const 接口是指那些被定义成 const 的成员函数。
基于 const,我们可以实现重载。这样,接受 const 参数的函数就不能随便修改对应的 const 对象,而接受非 const 参数的函数可以修改对应的对象,编译器会自动选择合适的函数。
const T & at ( size_t index ) const ;
T & at ( size_t index );
关于 const_cast:使用为 const_cast<target_type>(expr),cast away the const-ness of a variable。
template < typename T >
T & Vector < T >:: findElement ( const T & value ) {
for ( size_t i = 0 ; i < size ; ++ i ) {
if ( elems [ i ] == value ) return elems [ i ];
}
throw std :: runtime_error ( "Element not found" );
}
template < typename T >
const T & Vector < T >:: findElement ( const T & value ) const {
return const_cast < Vector < T >&> ( * this ). findElement ( value );
}
这里我们使用 const_cast 来将 const 的 *this 转换为非 const 饮用 const Vector<T>&,然后调用非 const 版本的 findElement 函数。但是整体还是 const 函数。
关于 mutable:mutable 修饰的成员变量可以在 const 函数中修改。
Lecture 9:模版函数
9.1 简单的例子
函数模版是一种泛型函数/Generic Function。
template < typename T >
T min ( const T & a , const T & b ) {
return a < b ? a : b ;
}
template < typename T , typename U >
auto min ( const T & a , const U & b ) {
return a < b ? a : b ;
}
实例化方法对应有两种:可以直接指定类型,也可以让编译器自行推断,但是推断的结果不一定如使用者本意(比如会把字符串字面量推断成 const char*):
min < int > ( 3 , 4 ); // 显式实例化:编译器帮我们生成对应代码
min ( 3.14 , 2.71 ); // 隐式实例化:编译器自行推断数据类型
min ( "hello" , "world" ); // 隐式实例化:编译器自行推断数据类型
min < const char *> ( "hello" , "world" ); // 显式实例化:上一行对应的其实是这个
还可以写更复杂的模版:
template < class InputIt , class T >
InputIt find ( InputIt first , InputIt last , const T & value );
9.2 Concepts
想法:要求模版函数的类型参数需要有某种特定的属性,比如 min 需要类型参数支持 < 运算符,find 需要类型参数 InputIt 是一个迭代器。
template < typename T >
concept Comparable = requires ( const T & a , const T & b ) {
{ a < b } -> std :: convertible_to < bool > ;
};
其中:
concept requires ( const T & a , const T & b ) T 必须满足的条件,这里我们要求类型 T 必须能够接受两个常量引用参数,并且满足下面条件;{ a < b } -> std :: convertible_to < bool > {} 内的 a < b 必须不存在编译错误,并且返回值必须可以转换为 bool 类型。注意到 std::convertible_to 也是一个 concept。
使用 concept,我们可以修改我们的代码,下面两种写法都是对的:
template < typename T > requires Comparable < T >
T min ( const T & a , const T & b );
template < Comparable T >
T min ( const T & a , const T & b );
template < std :: input_iterator InputIt , class T >
InputIt find ( InputIt first , InputIt last , const T & value );
9.3 变参模版
想法:我们希望创建可以接受任意数量参数的模版函数,但是函数重载的实现太过笨拙,考虑用递归的形式简化实现。
template < Comparable T >
T min ( const T & v ) { return v ; }
template < Comparable T , Comparable ... Args >
T min ( const T & v , const Args & ... args ) {
auto m = min ( args ...);
return v < m ? v : m ;
}
注意:
只有一个参数的版本是 Base Case Function;
Args 是一个参数包,对应着 0 个或者更多种类型,args 是实际的参数值;在 auto m = min ( args ...); args... 展开成了真正的参数。
在 min < int , int , int , int > ( 2 , 7 , 5 , 1 ) T = int Args = [ int , int , int ]
编译器通过递归生成任意数量的重载,这使得我们可以支持任意数量的函数参数;实例化发生在编译时。
Example for sum()
#include <string>
#include <string_view>
#include <type_traits>
inline double convertStringToNumber ( const std :: string_view & str ) { return std :: stod ( std :: string ( str )); }
template < typename T >
typename std :: enable_if < std :: is_arithmetic < T >:: value , double >:: type convertToNumber ( T value ) {
return static_cast < double > ( value );
}
template < typename T >
typename std :: enable_if < std :: is_convertible < T , std :: string_view >:: value , double >:: type convertToNumber ( const T & value ) {
return convertStringToNumber ( value );
}
inline double sum () { return 0.0 ; }
template < typename T , typename ... Args >
double sum ( T first , Args ... rest ) {
return convertToNumber ( first ) + sum ( rest ...);
}
9.4 模版元编程
我们可以利用函数模板的特性来进行一些编译期的计算,这被称为模板元编程/Templates Metaprogramming。
template <>
struct Factorial < 0 > {
enum { value = 1 }; // enum: One way to store a compile-time constant
};
template < std :: size_t N >
struct Factorial {
enum { value = N * Factorial < N - 1 >:: value };
};
std :: cout << Factorial < 5 >:: value << std :: endl ; // 120
TMP 是图灵完备的,我们可以在编译期执行任何代码(但是写出来一般很丑)。constexpr 和 consteval 为我们提供了 TMP 的一个替代品:
constexpr std :: size_t factorial ( std :: size_t n ) {
if ( n == 0 ) return 1 ;
return n * factorial ( n - 1 );
}
consteval std :: size_t factorial ( std :: size_t n ) {
if ( n == 0 ) return 1 ;
return n * factorial ( n - 1 );
}
constexpr
要求:参数和返回值必须是字面值类型,不能有副作用,只能调用 constexpr 函数。
性质:对应函数是纯函数,返回值隐含 const 属性。
consteval
要求:不能有静态变量,不能有副作用,不能在运行时上下文中调用。
Lecture 10:函数与 Lambda 表达式
10.1 谓词函数
「谓词函数」
谓词函数/Predicate 是一个返回 bool 类型的函数,通常用于 STL 中。
bool isEven ( int x ) {
return x % 2 == 0 ;
}
bool isLessThan ( int x , int y ) {
return x < y ;
}
想法:通过传入谓词函数,可以进一步简化上一节中的 find 函数。推广开来,定义序关系后,程序会更加简单。
template < typename It , typename Pred >
It find_if ( It first , It last , Pred pred ) {
for ( It it = first ; it != last ; ++ it ) {
if ( pred ( * it )) return it ;
}
return last ;
}
bool isVowel ( char c ) {
c = :: tolower ( c );
return c == 'a' || c == 'e' || c == 'i' || c == 'o' || c == 'u' ;
}
std :: string s = "Hello, World!" ;
std :: string :: iterator it = find_if ( s . begin (), s . end (), isVowel );
将函数作为参数传递允许我们将算法与用户定义的行为进行泛化。
Passing functions allows us to generalize an algorithm with user-defined behaviour .
事实上,Pred 是一个函数指针,对上述式子来说,Pred 的类型是 bool ( * )( char )
但是,单纯传递函数指针作为参数是个很好的想法,然而函数指针的泛化能力有限(修改一下上面那段代码使得 isVowel 可以接受两个参数就知道了)。因此,我们引入了 Lambda 表达式。
10.2 Lambda 表达式
Lambda 函数是从所在的作用域捕获状态的函数。
Lambda functions are functions that capture state from an enclosing scope.
int n ;
std :: cin >> n ;
auto lessThanN = [ n ]( int x ) { return x < n ; };
Lambda 表达式的完整声明如下:[ capture - values ]( arguments ) mutable exception -> return type { function - body };
方括号 [] 内的是捕获列表,可以让函数体内使用外侧的变量;
括号 () 内的是参数列表,和正常的函数无异;
mutable 关键字表示 Lambda 函数可以修改捕获的变量;花括号 {} 内的是函数体,但是只有参数列表和捕获的变量可以被访问。
捕获方式如下:
[x]:按值捕获 x(创建副本);[x&]:按引用捕获 x;[x, y]:按值捕获 x 和 y;[&]:按引用捕获所有变量;[&, x]:除了 x 按值捕获外,其他都按引用捕获;[=]:按值捕获所有变量。[]:不捕获任何变量。
一个函子/Functor 是重载了 operator() 的类,Lambda 表达式本质上就是一个匿名的函子。
Definition: A functor is any object that defines an operator()
template < typename T >
struct std :: greater {
bool operator ()( const T & x , const T & y ) const {
return x > y ;
}
};
std :: greater < int > greaterThan ;
greaterThan ( 3 , 5 ); // false
既然函子是一个对象,它当然可以有状态:
struct my_functor {
bool opearator ()( int a ) const {
return a * value ;
}
int value ;
}
my_functor f ;
f . value = 3 ;
f ( 5 ); // 15
我们通过生成函子来生成 Lambda 表达式:
int n = 10 ;
auto lessThanN = [ n ]( int x ) { return x < n ; }
find_if ( begin , end , lessThanN );
其中的 Lambda 表达式就等价于:
class __lambda_6_18 {
public :
bool operator ()( int x ) const { return x < n ; }
__lambda_6_18 ( int & n ) : n { _n } {}
private :
int n ;
};
int n = 10 ;
auto lessThanN = __lambda_6_18 ( n );
find_if ( begin , end , lessThanN );
另外,std :: function
10.3 Range 和 View
Range 是定义了 begin 和 end 的任何东西。
Definition: A range is anything with a begin and end.
像 std::vector、std::string、std::set、std::map 都是 Range。
Range 提供了很多有效的函数,比如 std::ranges::find:
std :: vector < char > v = { 'a' , 'b' , 'c' , 'd' , 'e' };
auto it_ = std :: find ( v . begin (), v . end (). 'c' );
auto it = std :: ranges :: find ( v , 'c' );
auto _it = std :: ranges :: find ( v . begin () + 1 , v . end () - 1 , 'c' );
View/视图提供一种组合算法的方式,View 是一种惰性地适配另一个 Range 的 Range。
Views: a way to compose algorithms.
std :: vector < char > v = { 'a' , 'b' , 'c' , 'd' , 'e' };
std :: vector < char > f , t ;
std :: copy_if ( v . begin (), v . end (), std :: back_inserter ( f ), isVowel );
std :: transform ( f . begin (), f . end (), std :: back_inserter ( t ), toupper );
在使用 View 后,上述可以变成:
std :: vector < char > letters = { 'a' , 'b' , 'c' , 'd' , 'e' };
auto f = std :: ranges :: views :: filter ( letters , isVowel );
auto t = std :: ranges :: views :: transform ( f , toupper );
auto vowelUpper = std :: ranges :: to < std :: vector < char >> ( t );
这利用了 View 的可组合性,我们还可以通过 opera tor |
using rv = std :: ranges :: views ;
std :: vector < char > letters = { 'a' , 'b' , 'c' , 'd' , 'e' };
std :: vector < char > upperVowel = letters | rv :: filter ( isVowel ) | rv :: transform ( toupper ) | rv :: to < std :: vector < char >> ();
View 是惰性求值/Lazy Evaluation 的,这意味着上上个代码块只有到了最后一行才会真正求值。这样就可以很大的节约内存空间。这很像 Python 的生成器。
Range 是急切求值/Eager Evaluation 的,这意味着 std :: ranges :: sort ( v ); std::ranges 是旧的 STL 算法的重新包装。
PPT 上提到的一个小问题
C++26 甚至还有更新的东西,这就不写了。
Lecture 11:运算符重载
回忆:std :: map operator < min 其实是不方便的。这就要求我们对不同的类定义序关系,也就是给出 operator <
运算符允许我们传达函数不能传达的、关于对象的语义。你们 min 可以传达序关系吗?
Operators allow you to convey meaning about types that functions don't.
class StudentID {
private :
std :: string name ;
std :: string sunet ;
int idNumber ;
public :
StudentID ( const std :: string & name , const std :: string & sunet , int idNumber )
: name ( name ), sunet ( sunet ), idNumber ( idNumber ) {}
bool operator < ( const StudentID & rhs ) const { return idNumber < rhs . idNumber ; }
friend bool operator == ( const StudentID & lhs , const StudentID & rhs );
};
bool operator > ( const StudentID & lhs , const StudentID & rhs ) { return rhs < lhs ; }
bool operator == ( const StudentID & lhs , const StudentID & rhs ) {
return lhs . idNumber == rhs . idNumber && lhs . name == rhs . name && lhs . sunet == rhs . sunet ;
}
成员重载:如上面对 operator <
非成员重载:如上面对 operator == operator >
非成员重载更被 STL 偏爱,并且在 C++ 更为常见,因为其允许左侧的操作数是任意类型,并且允许重载我们不拥有的类,可以定义一个运算符讲 StudentID 和任何我们定义的类比较。
友元允许非成员函数访问对象的 private 成员。
不能重载的运算符:
:::作用域解析运算符.:成员访问运算符.*:成员指针访问运算符? ::三元运算符sizeof():获取类型或对象的大小typeid():获取类型信息cast():类型转换
可以重载的运算符:
class __lambda_6_18 {
public :
bool operator ()( int x ) const { return x < n ; }
__lambda_6_18 ( int & n ) : n { _n } {}
private :
int n ;
};
int n = 10 ;
auto lessThanN = __lambda_6_18 ( n );
find_if ( begin , end , lessThanN );
我有问题🤓:我重载了运算符 operator () () 的构造函数有没有影响?
当然是没有:构造函数和 operator() 是完全独立的函数。重载 operator() 不会影响构造函数的使用。圆括号语法在两种情况下有不同的含义:
对类名使用时表示构造函数调用;
对对象使用时表示 operator() 调用。
class Calculator {
public :
Calculator ( int base ) : base_ ( base ) { std :: cout << "Calculator constructed \n " ; }
int operator ()( int x ) const { return base_ + x ; }
private :
int base_ ;
};
Calculator calc ( 10 ); // 正常工作
int result = calc ( 5 ); // 调用 operator(),返回 15
Lecture 12:特殊成员函数
每个类都默认有六个特殊的成员函数,这些成员函数只有在被调用的情况下才会自动生成默认版本,或者我们显式地定义它们。
默认构造函数/Default Constructor:T ()
析构函数/Destructor:~ T ()
拷贝构造函数/Copy Constructor:T ( const T & )
拷贝赋值运算符/Copy Assignment Operator:T & operator = ( const T & )
移动构造函数/Move Constructor:T ( T && )
移动赋值运算符/Move Assignment Operator:T & operator = ( T && )
class Widget {
public :
Widget ();
Widget ( const Widget & w );
Widget & operator = ( const Widget & w );
Widget ( Widget && rhs );
Widget & operator = ( Widget && rhs );
~ Widget ();
};
Widget widgetOne ;
Widget widgetTwo = widgetOne ; // 调用拷贝构造函数
Widget widgetThree ;
widgetThree = widgetOne ; // 调用拷贝赋值运算符
在将一个已经存在的对象赋值给另一个的时候,会调用拷贝赋值运算符;
在使用一个已经存在的对象初始化另一个对象的时候,会调用拷贝构造函数。
当一个对象出了作用域,析构函数会被自动调用。
对于不能赋值的成员,比如 const 成员或者引用成员,这就需要使用初始化列表,初始化列表的效率也更高。
template < typename T >
class MyClass {
const int _constant ;
int & _reference ;
public :
MyClass ( int value , int & ref ) : _constant ( value ), _reference ( ref ) {}
};
默认的拷贝构造函数会拷贝每一个成员变量,按成员逐个复制,但是远远不足够如果变量是一个指针,那么拷贝的只是指针的值,而不是指针指向的内容,这种情况被称为浅拷贝。
template < typename T >
Vector < T >:: Vector ( const Vector < T > & other )
: _size ( other . _size ), _capacity ( other . _capacity ), _data ( other . _data ) { }
很多时候,我们希望创建的拷贝不仅仅只是拷贝成员变量;深拷贝会创建一个完全独立的副本。
template < typename T >
Vector < T >:: Vector ( const Vector < T > & other )
: _size ( other . _size ), _capacity ( other . _capacity ), _data ( new T [ other . _capacity ]) {
for ( int i = 0 ; i < _size ; i ++ ) _data [ i ] = other . _data [ i ];
}
我们可以“删除”特殊成员函数,通过 = delete 来显式禁用其功能,也可以通过 = default 来显式地要求编译器生成默认版本。
class Widget {
Widget ( const Widget & ) = delete ;
};
关于特殊成员函数,有以下原则:
Rule of Zero:如果默认的特殊成员函数能满足需求,那就不要自己实现,只在编译器默认生成的版本不能满足需求的时候才自己实现。如果我们的类是自管理的,就不需要自定义特殊成员函数。
Rule of Three:如果类需要自定义析构函数,那么通常也需要定义一个拷贝构造函数和拷贝赋值运算符。因为我们自定义析构函数意味着我们正在手动解决动态内存分配,这时候编译器就不会自动生成默认的拷贝构造函数和拷贝赋值运算符。
下面很多就是下一节:移动语义的东西了。
Lecture 13:移动语义
class Photo {
public :
Photo ( int width , int height );
Photo ( const Photo & other );
Photo & operator = ( const Photo & other );
~ Photo ();
private :
int width ;
int height ;
int * data ;
};
Photo :: Photo ( int width , int height ) : width ( width ), height ( height ), data ( new int [ width * height ]) {}
Photo :: Photo ( const Photo & other ) : width ( other . width ), height ( other . height ),
data ( new int [ other . width * other . height ]) {
std :: copy ( other . data , other . data + other . width * other . height , data );
}
Photo & Photo :: operator = ( const Photo & other ) {
if ( this == & other ) return * this ;
delete [] data ;
width = other . width ;
height = other . height ;
data = new int [ width * height ];
std :: copy ( other . data , other . data + other . width * other . height , data );
return * this ;
}
Photo ::~ Photo () { delete [] data ; }
Photo takePhoto ();
int main () {
Photo p1 = takePhoto (); // 编译器的 Return Value Optimization,避免拷贝
Photo retake ( 0 , 0 );
retake = takePhoto (); // 先是拷贝赋值,然后析构
}
但是这里的拷贝赋值非常占用时间,这个数据可能就有 width * height * 4 个字节,如果数据很大,那么拷贝赋值的时间就会很长。我们更希望将一个资源的所有权从一个对象转一个另一个对象,这样就避免了拷贝赋值。
但是编译器从何得知应该是拷贝还是移动呢?左值和右值的概念泛化了 C++ 中临时性的概念:
void foo ( Photo p ) {
Photo beReal = p ;
Photo instag = takePhoto ();
}
beReal 是一个左值,是有明确内存地址的表达式,我们可以对其取地址,可以放在等号左边;instal 是一个右值,临时值,没有固定内存地址,不能对其取地址,只能放在等号右边。
左值的生命周期是其作用域,右值的生命周期是当前行。
如果我们有左值,向函数传递引用就可以避免拷贝:
void uploadToInsta ( Photo & photo );
int main () {
Photo p1 = takePhoto ();
uploadToInsta ( p1 ); // No COPY here.
}
对于右值,我们就需要传递右值引用 && 来避免拷贝:
void uploadToInsta ( Photo && photo );
int main () {
uploadToInsta ( takePhoto ()); // No COPY here.
}
左值引用:Type &
右值引用:Type &&
左值引用和右值引用因此可以产生重载:
Photo :: Photo ( const Photo & other ) : width ( other . width ), height ( other . height ),
data ( new int [ other . width * other . height ]) {
std :: copy ( other . data , other . data + other . width * other . height , data );
}
Photo :: Photo ( Photo && other ) : width ( other . width ), height ( other . height ), data ( other . data ) {
other . data = nullptr ;
}
Photo & Photo :: operator = ( const Photo & other ) {
if ( this == & other ) return * this ;
delete [] data ;
width = other . width ;
height = other . height ;
data = new int [ width * height ];
std :: copy ( other . data , other . data + other . width * other . height , data );
return * this ;
}
Photo & Photo :: operator = ( Photo && other ) {
delete [] data ;
width = other . width ;
height = other . height ;
data = other . data ;
other . data = nullptr ;
return * this ;
}
强制移动语义:
void PhotoCollection::insert ( const Photo & photo , int pos ) {
for ( int i = size (); i > pos ; i -- )
elems [ i ] = elem [ i - 1 ];
elems [ i ] = pic ;
}
这时显然第三行使用的是拷贝赋值,我们希望使用移动赋值,这时就需要强制移动语义:
elems [ i ] = std :: move ( elem [ i - 1 ]);
std :: move
最后阐释一下 C++ 的几个原则:
Rule of One: If a class does not manage memory (or another external resource), the compiler generated versions of the SMFs are sufficient.
Rule of Three: If a class manages external resources, we must define copy assignment/destructor . Or, if we need to define only one of the copy constructor/assignment and destructor, we should define all three.
Rule of Five: If we defined copy constructor/assignment and destructor, we should also define move constructor/assignment.
Lecture 14:Optional 和类型安全
类型安全 :函数签名保证函数行为的能力(编程语言防止出现类型错误的能力)。
The extent to which a function signature guarantees the behavior of the function.
void removeOddsFromEnd ( vector < int >& vec ) {
while ( vec . back () % 2 == 1 ) {
vec . pop_back ();
}
}
vector :: back () vector 的最后一个元素的引用,如果 vector 为空,则行为未定义;vector :: pop_back () vector 的最后一个元素;因此我们不能保证这个函数的行为是安全的。
解决:程序员有责任确保前置条件 vec 不为空成立:
void removeOddsFromEnd ( vector < int >& vec ) {
while ( ! vec . empty () && vec . back () % 2 == 1 ) {
vec . pop_back ();
}
}
深层问题:问题来自于 vector :: back ()
valueType & vector < valueType >:: back () {
return * ( begin () + size () - 1 );
}
但是不加检验地解引用指针,有可能导致未定义行为,我们可以加上检验:
valueType & vector < valueType >:: back () {
if ( empty ()) throw std :: out_of_range ;
return * ( begin () + size () - 1 );
}
这个版本通过抛出异常来处理空容器的情况,但仍有改进空间。当 vec 并不存在最后一个元素的时候,我们希望返回一定的警告而不是直接抛出异常:
std :: pair < bool , valueType &> vector < valueType >:: back () {
if ( empty ()) {
return { false , valueType ()};
}
return { true , * ( begin () + size () - 1 )};
}
我们希望返回一个 std::pair,其中第一个元素表示是否成功,第二个元素表示返回的值。但是仍然存在问题:
要求 valueType 有默认构造函数;
即使 valueType 有默认构造函数,调用起构造函数也是很昂贵的;
就算我们忍受上面两个问题,如果默认构造函数返回的值是奇数,那么在 vec . pop_back ()
std :: optional T 的一个值,要么不包含任何值(std :: nullopt optional 类型“空值”)。
std :: optional < int > num1 = {}; // num1 没有值
num1 = 1 ; // 现在有值了
num1 = std :: nullopt ; // 又变成没有值
因此我们可以使用 std :: optional
std :: optional < valueType > vector < valueType >:: back () {
if ( empty ()) return {};
return * ( begin () + size () - 1 );
}
void removeOddsFromEnd ( vector < int >& vec ) {
while ( vec . back () && vec . back (). value () % 2 == 1 ) {
vec . pop_back ();
}
}
std :: optional
. value () std :: bad_optional_access . value_or ( val ) val;. has_value () true,否则返回 false。. and_then ( f ) f(),并返回结果,其中 f 必须返回 std :: optional std :: nullopt . transform ( f ) value,则返回调用 f(value) 的结果,其中 f 必须返回 std :: optional < valueType > std :: nullopt . or_else ( f ) f() 的结果。
注意:
不允许使用 std :: optional < T &> std :: optional
我们还是需要到处使用 . value () std :: bad_optional_access std :: optional *optional 仍然可能有未定义行为。
单子式/Monadic:软件设计模型,其结构组合了程序段,并将它们的返回值包装在一个带有额外计算的类型中。允许我们尝试调用一个函数,并且要么返回计算的结果,要么返回一些默认值。
void removeOddsFromEnd ( vector < int >& vec ) {
auto idOdd = []( optional < int > num ) {
if ( num ) return num % 2 == 1 ;
else return std :: nullopt ;
};
while ( vec . back (). and_then ( idOdd ))
vec . pop_back ();
}
虽然 std :: optional std :: optional std :: optional
Lecture 15:RAII 和智能指针
异常是处理代码错误的一种方式,异常可以被抛出/Thrown,可以在 try-catch 块中捕获/Caught 并且处理异常,允许程序在遇到错误时继续执行而不是直接崩溃。
try {
// 可能抛出异常的代码
} catch ([ exception ] e1 ) {
// 处理异常
} catch ([ exception ] e2 ) {
// 处理另一个异常
} catch {
// 处理其余所有异常
}
举个例子:
std :: string returnNameCheckPawsome ( Pet p ) {
if ( p . type () == "Dog" || p . firstName () == "Fluffy" ) {
std :: cout << p . firstName () << " " <<
p . lastName () << " is paw-some!" << '\n' ;
}
return p . firstName () + " " + p . lastName ();
}
至少 23 个可能的执行路径:
Pet 的拷贝构造函数可能抛出 1 个异常;临时字符串的构造函数加起来可能抛出 5 个异常;
Pet 的 type()、firstName() 和 lastName() 方法可能抛出 6 个异常;operator+ 运算符重载可能抛出 10 个异常;返回字符串的拷贝构造函数可能抛出 1 个异常。
std :: string returnNameCheckPawsome ( int petId ) {
Pet * p = new Pet ( petId );
if ( p -> type () == "Dog" || p -> firstName () == "Fluffy" ) {
std :: cout << p -> firstName () << " " <<
p -> lastName () << " is paw-some!" << '\n' ;
}
std :: string returnStr = p -> firstName () + " " + p -> lastName ();
delete p ;
return returnStr ;
}
在 new delete p 没有被析构。
有很多资源需要获取后释放,不仅仅是堆内存,还有文件、锁和套接字等。
RAII:Resource Acquisition Is Initialization,资源获取即初始化。
类(对象)所使用的所有资源都应该在构造函数中被获取;
类(对象)所使用的所有资源都应该在析构函数中被释放。
资源在创建之后立刻有用, 当对象离开作用域的时候自动调用析构函数。
资源的获取和释放应该是一体的,资源的释放应该在对象的生命周期结束时自动进行。即资源的有效期 = 持有资源的对象的生命周期。
ifstream input ;
input . open ( "hamlet.txt" );
input . close ();
这就不符合 RAII 原则,因为 input 在构造函数外被打开,在析构函数外被关闭。
智能指针包装了原始的指针,通过 RAII 原则自动管理动态分配的内存,主要有这三种:
std :: unique_ptr std :: shared_ptr std :: weak_ptr
std :: unique_ptr std :: move
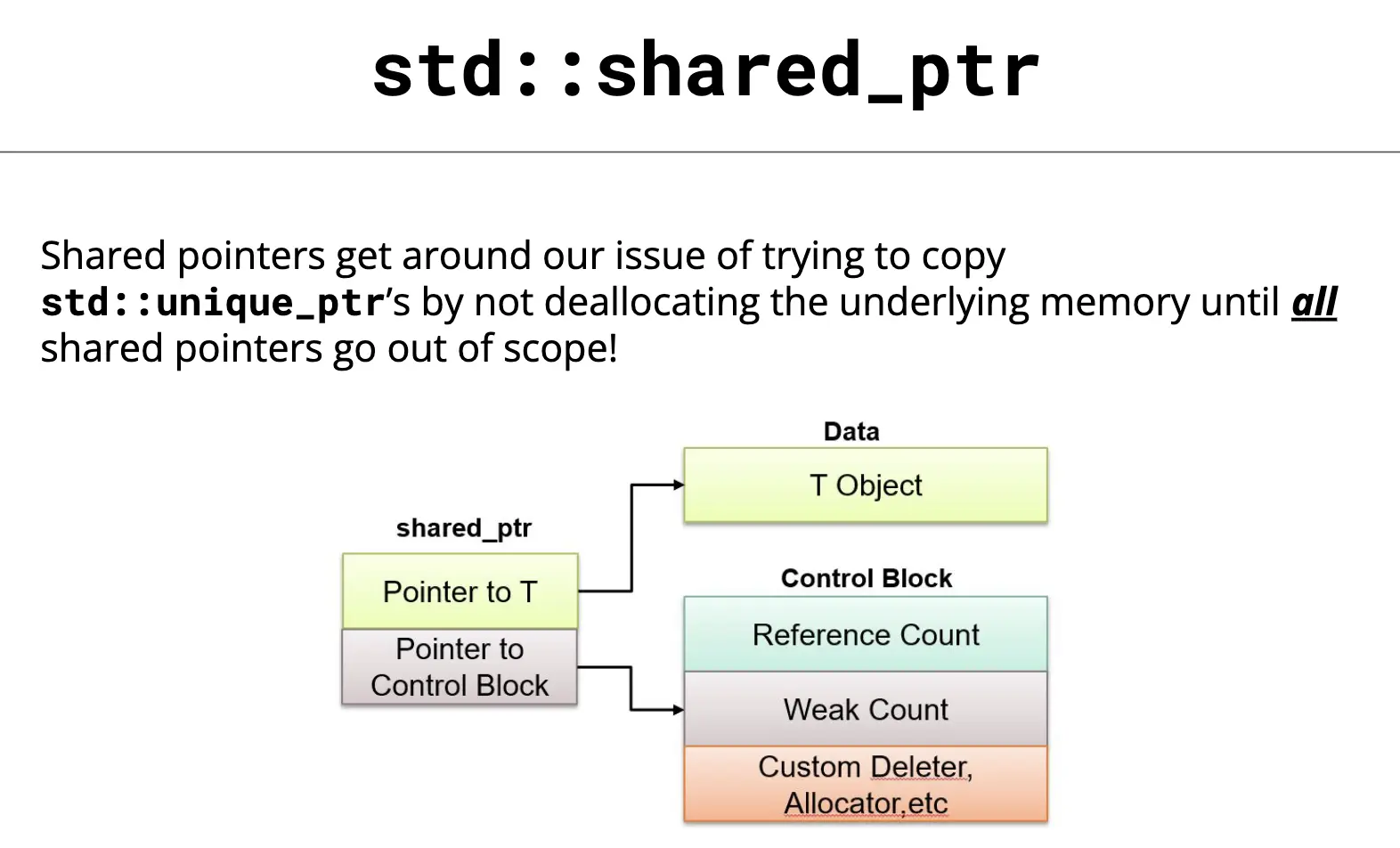
std :: shared_ptr
引用计数这种计数是为了防止内存泄露而产生的。基本想法是对于动态分配的对象,进行引用计数,每当增加一次对同一个对象的引用,那么引用对象的引用计数就会增加一次,每删除一次引用,引用计数就会减一,当一个对象的引用计数减为零时,就自动删除指向的堆内存。
std :: shared_ptr shared_ptr delete std :: make_shared std :: shared_ptr std :: shared_ptr
我们通过 . get () . reset () reset 的参数(不同重载有不同含义,比如 . reset () . use_count ()
初始化智能指针:
std :: unique_ptr < T > uniquePtr = std :: make_unique < T > ();
std :: shared_ptr < T > sharedPtr = std :: make_shared < T > ();
std :: weak_ptr < T > weakPtr = sharedPtr ;
对于下面代码:
struct A {
std :: shared_ptr < B > pointer ;
~ A () {
std :: cout << "A 被销毁" << std :: endl ;
}
};
struct B {
std :: shared_ptr < A > pointer ;
~ B () {
std :: cout << "B 被销毁" << std :: endl ;
}
};
int main () {
auto a = std :: make_shared < A > ();
auto b = std :: make_shared < B > ();
a -> pointer = b ;
b -> pointer = a ;
}
运行结果就是 A 和 B 都不会被销毁,这是因为 a 和 b 内部的 pointer 同时又强引用了 a 和 b,这使得 a 和 b 的引用计数均变为了 2,而离开作用域时,a 和 b 智能指针被析构,却只能造成这块区域的引用计数减一,这样就导致了 a 和 b 对象指向的内存区域引用计数不为零,而外部已经没有办法找到这块区域了,也就造成了内存泄露。
解决方法就是使用弱引用 std :: weak_ptr std :: weak_ptr * 运算符和 -> 运算符,不能对资源进行操作,它可以用于检查 std :: shared_ptr expired () false,否则返回 true;除此之外,它也可以用于获取指向原始对象的 std :: shared_ptr lock () std :: shared_ptr std :: shared_ptr < T > sp = wp . lock () nullptr。
std :: unique_ptr template < typename T >
class unique_ptr {
private :
T * ptr { nullptr };
public :
unique_ptr ( T * ptr ) : ptr ( ptr ) {}
unique_ptr ( std :: nullptr_t ) : ptr ( nullptr ) {}
unique_ptr () : unique_ptr ( nullptr ) {}
T & operator * () { return * ptr ; }
const T & operator * () const { return * ptr ; }
T * operator -> () { return ptr ; }
const T * operator -> () const { return ptr ; }
operator bool () const { return ptr != nullptr ; }
~ unique_ptr () { delete ptr ; }
unique_ptr ( const unique_ptr & other ) = delete ;
unique_ptr & operator = ( const unique_ptr & other ) = delete ;
unique_ptr ( unique_ptr && other ) : ptr ( other . ptr ) { other . ptr = nullptr ; }
unique_ptr & operator = ( unique_ptr && other ) {
if ( this != & other ) {
delete ptr ;
ptr = other . ptr ;
other . ptr = nullptr ;
}
return * this ;
}
};
template < typename T , typename ... Args >
unique_ptr < T > make_unique ( Args && ... args ) {
return unique_ptr < T > ( new T ( std :: forward < Args > ( args )...));
}
Appendix