Chapter 6 Architecture¶
约 4729 个字 129 行代码 4 张图片 预计阅读时间 17 分钟
Warning
本章节中的术语均由本人翻译,笔者尽力保证翻译的准确性,同时将原文术语保留,可能会出现一些不准确的地方,欢迎指正。
6.1 Introduction¶
6.2 Assembly Language¶
ISA 的分类
- Stack Architecture:
- Implicit Operands - on the Top Of the Stack(TOS).
- For operation
Add, both operands are removed from the stack, then perform the operation with the operands, store the result to the stack. - Easy to operate: Implement
C = A + B:
- Accumulator Architecture:
- One implicit operand: The accumulator.
- One explicit openand: Memory location.
- Instruction set:
add A,sub A,mult A,div A,store A,load A... - Implement
C = A + B:
- General Purpose Register Architecture (Register Memory Arch):
- Only explicit operands: Registers and Memory Locations.
- Operand access:
- General Purpose Register Archtecture (Load-Store Arch) (RISC-V):
- Only load and store instructions can access memory.
GPR Classification:
汇编语言是机器语言的人类可读表示,每条汇编语言指令都指出了该执行哪个操作和操作需要那些操作数。本章以 RISC-V 汇编 (RV32I) 为例,提纲挈领介绍简单的汇编语言。先引入一些简单的算术指令:
add:add dest, src1, src2,对应的 C 语言代码为dest = src1 + src2。左侧的
add是助记符/Mnemonic,右侧的dest称为目的操作数/Destination Operand,src1和src2称为源操作数/Source Operand。sub:sub dest, src1, src2,对应的 C 语言代码为dest = src1 - src2。
为了让最常见的情况执行得最快,RISC-V 指令集架构只引入了最常用的一部分指令,这样用来解码指令的硬件就可以变得简单、小巧且快速。更多的不太常见的复杂指令将会被拆分成几条简单的指令。RISC-V 指令集架构是经典的精简指令集计算机/RISC 架构,与之相对的是复杂指令集计算机/CISC 架构,如 x86 架构。在 CISC 架构中,尽管一条很复杂的指令很可能只会用到很少次,但是仍然会被加到指令集中,这样就会让硬件变得更复杂。
指令需要快速的获取操作数,这样才能保证运行快速。因此需要引入寄存器,RV32I 有 32 个 32 位的通用目的寄存器,分别用 x0 到 x31 表示。格外需要记忆的是 x0 代表硬件零,命名为 zero;x1 代表返回值,命名为 ra;x2 代表栈指针,命名为 sp,x3 代表全局指针,命名为 `gp。
lui 常常用于创建大立即数,lui dest, imm,对应的 C 语言代码为 dest = imm << 12。lui 与 addi 配合就可以创建出任意 32 位的立即数。需要注意的是,如果 addi 的立即数是负数,那么需要在 lui 创建的高位立即数中加上 1。这是因为 addi 的立即数是有符号的,换句话说,addi 将会对立即数进行符号扩展,而全 1 的立即数是 -1,就相当于在高位减去了 1,在 lui 的立即数中加上 1 就可以抵消这个减 1。具体可以看下面的例子:
由于 0x987 的最高位是 1,所以所以扩展之后就变成了 0xFFFFF987 (-1657),所以需要在 lui 的立即数中加上 1。这也算一个很有用的小技巧。
在 RISC-V 中,指令只能对寄存器进行操作,所以在内存中的数据需要先加载到寄存器中,然后再进行操作。RISC-V 使用字节寻址,下面是一个典型的内存模型:
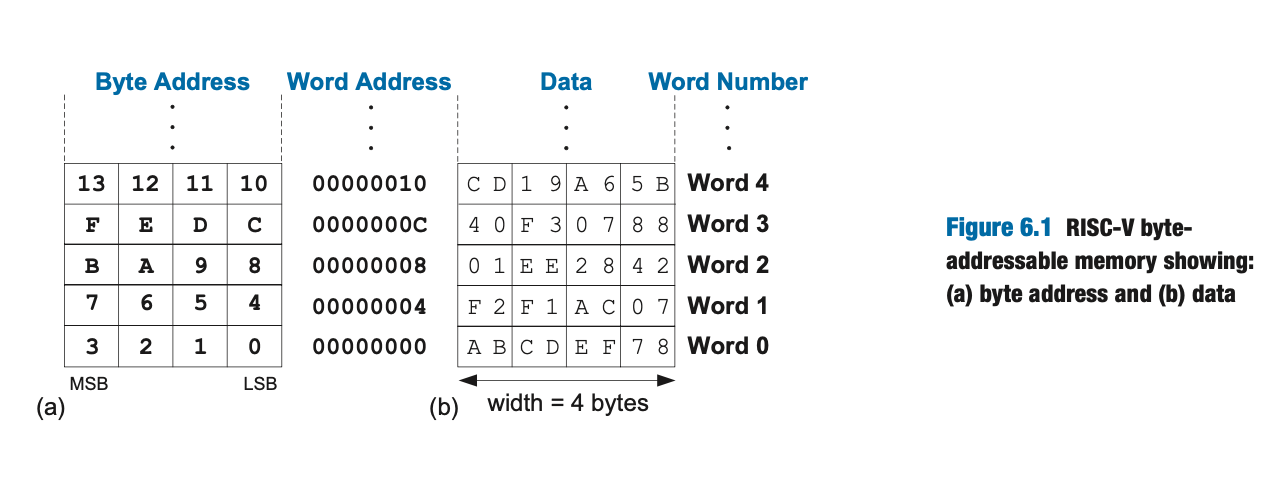
左侧默认是最高有效字节/MSB,右侧是最低有效字节/LSB,若对端序有了解的话,可以发现这个内存模型实际上是用的是小端序,即最低有效字节在最低的地址。字地址为 0x00000004 的字表示的数据是 0xF2F1AC07。
默认来说,内存是从低地址在低端,从低向高画的。并且多数 RISC-V 的实现都要求字对齐地址/Word-aligned Address,也就是说 lw 和 sw 指令只能对 4 的倍数地址进行操作。
经典的内存操作是 lw 和 sw,分别用于加载字和存储字,一般的格式为 *w dest, offset(base),会在寄存器 dest 和地址为 offset + base 的内存中进行数据传输。
6.3 Programming¶
6.3.6 数组¶
6.3.7 函数调用¶
6.3.8 伪指令¶
6.4 Machine Language¶
6.5 Compiling, Assembling and Loading¶
高级语言转化成机器语言并且开始执行的过程对我们来说早已耳熟能详,编译器将高级语言代码转化成汇编语言代码,然后汇编器将汇编语言代码转化成机器语言代码,并且打包成一个目标文件,链接器将目标文件与其他库以及其他文件链接起来,并确定合适的分支地址与变量位置,从而生成一个可执行文件。最后,加载器会将可执行文件加载到内存中,并且开始执行。我们从内存模型开始介绍:
6.5.1 内存映射¶
由于 RV32I 只有 32 位地址,所以 RV32I 的内存地址空间只有 4GB,字地址只能是 4 的倍数,范围从 0x0 到 0xFFFFFFFC。我们的内存映射将地址空间分成下面五个部分或者称为端/Segment:文本段/Text,全局数据段/Global Data Segment,动态数据段/Dynamic Data Segments 以及异常处理程序/Exception Handlers 与操作系统/Operating System 的段。下面是一个典型的内存映射:
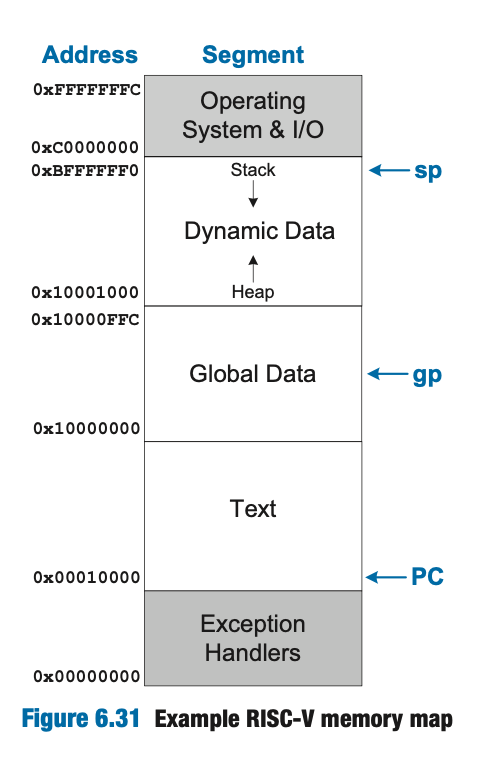
但是 RISC-V 并不定义特定的内存映射,尽管异常处理程序要么在低地址要么在高地址,但是用户还可以自定义文本段、内存映射 IO、栈与全局数据的地方,这就提供了很大的灵活性,尤其对于一些小型系统来说特别重要。
- 「文本段/Text」:存放机器语言代码,也可能包含字面量与只读的数据。
- 「全局数据段/Global Data Segments」:存放全局变量,这些变量可以被程序中的任何函数访问。局部变量定义在函数之中,只可以被该函数访问,他们一般位于寄存器上或者栈上,拿
sp访问。全局变量会在程序开始执行钱就分配内存,它们一般需要使用全局指针寄存器gp来访问。gp一般指向整个全局数据段的中间位置,在上面的内存映射中,gp指向0x1000800,使用 12 比特的偏移量恰好可以通过gp访问到全局数据段的任意位置。 - 「动态数据段/Dynamic Data Segments」:动态数据段包括栈和堆,这部分的数据在程序开始的时候尚未确定,在程序执行的动态分配和释放。在程序开始的时候,操作系统会将栈指针设为栈的顶部,这里是
0xBFFFFFF0。栈一般是向下增长的,栈包括临时存储和不适合放在寄存器中的局部变量,每个栈帧强行按照后进先出的顺序访问。堆存储程序运行时分配的数据,堆一般是向上增长的,内部数据可以以任何顺序使用或者丢弃。如果栈和堆增长并且碰撞在一起,程序的数据可能会被破坏,内存分配器会确保这种情况不会发生,倘若是真的没有足够的空间来分配更多的动态数据,内存分配器会返回一个内存不足的错误。 - 「异常处理程序、操作系统与 IO 段」:RISC-V 内存映射的最底部部分保留给异常处理程序和启动时运行的引导代码,内存映射的最顶部分保留给操作系统和内存映射 IO/Memory-mapped IO。
另外,RISC-V 还要求 sp 满足 16 字节对齐,这是为了保证与四倍精度的基础指令集架构 RV128I 兼容。RV128I 操纵 16 字节的数据,因此 sp 要求以 16 字节的倍数递减,尽管可能只需要很少的内存。
6.5.2 汇编器指令¶
汇编器指令用于指导汇编器分配并初始化全局变量、定义常量、区分代码与数据方面的工作。
.data、.text、.bss 以及 .section、.rodata 这些汇编指令分别告诉汇编器将后续的数据或代码放在全局数据段、文本段、BSS 段或只读数据段中。BSS 段位于全局数据段中,但是其初始化值为 0。只读数据段是常量数据,放置在文本段中(即程序存储器/Program Memory 中),下面是一些常见的汇编器指令。
| 汇编器指令 | 描述 |
|---|---|
.text |
代码段 |
.data |
全局数据段 |
.bss |
初始化为 0 的全局数据段 |
.section .foo |
名为 .foo 的段 |
.align N |
下一个数据/指令对齐在 \(2^N\) 字节边界上 |
.balign N |
下一个数据/指令对齐在 \(N\) 字节边界上 |
.globl sym |
标签 sym 是全局的 |
.string "str" |
将字符串 "str" 存储在内存中 |
.word w1, w2,..., wN |
在连续的内存字中存储 \(N\) 个 32 位值 |
.byte b1, b2,..., bN |
在连续的内存字节中存储 \(N\) 个 8 位值 |
.space N |
保留 \(N\) 字节以存储变量 |
.equ name, constant |
用值 constant 定义符号 name |
.end |
汇编文件结束 |
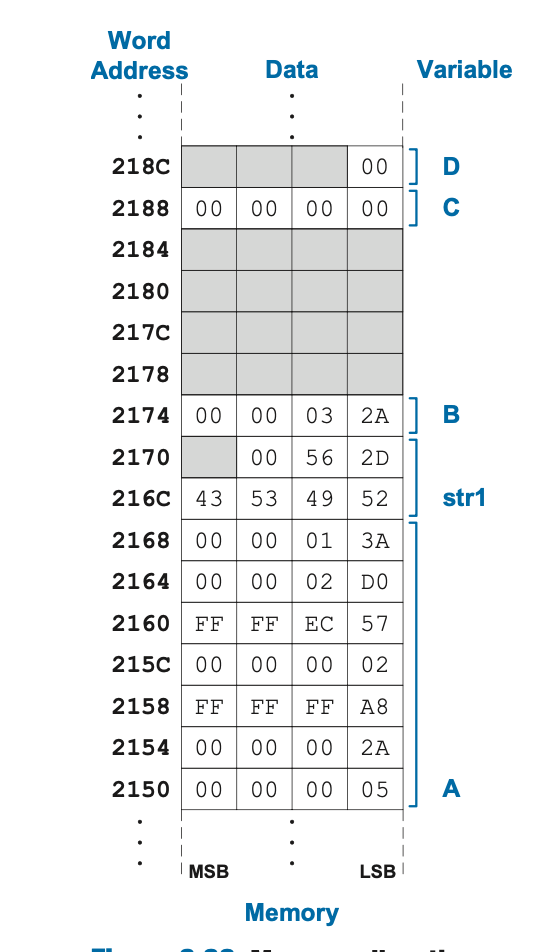
右侧是上面的实例代码对应的内存分配模型。首先将 main 标签定义为全局标签,这样就令 main 函数可以从这个文件外部被操作系统或引导加载程序调用。.equ N, 5 会将 N 的值定义为 5,在汇编指令翻译成机器代码之前,汇编器会将所有的标签 N 替换成 5。.align 2汇编指令将后续的数据或代码对齐在 2 ^ 2 = 4 字节的边界上,.balign 4(按照 4 字节对齐)的效果是一样的。这些汇编指令有助于保持数据和指令的对齐。例如,如果在分配 B 之前删除 .align 2(即在B: .word 0x32A 之前),B 就会直接在 str1 变量之后被分配,占据字节 0x2157 – 0x215A(而不是 0x2158 – 0x215B)。该汇编器在数据段和 BSS 段之间包括了 16 字节的未分配内存,如右图中的灰色框所示。还是应该一直记得该部分内存使用的仍然是小端序,这完全可以从 str1 的内存布局看出来。
其余的一些内容看看代码就会了。
6.5.3 编译¶
编译器将高级语言代码转换成汇编语言代码。可以使用 gcc 编译器将下边的 C 代码转换成汇编代码:
可能用到的指令如下:gcc –O1 –S prog.c –o prog.s。书上讲的确实没什么好说的,只简单提一下这个递归吧,func 函数编译后的汇编代码在上边:程序首先将 f 和 g 放入参数寄存器 a0 和 a1,然后调用 func 函数,函数先将 ra 和 s0 存放在栈上,然后将 a0(a)放入 s0(因为在递归调用 func 之后还需要它),并计算 a0 = a0 + a1(返回值 = a + b)。如果 a1(b)大于等于 0,就进入分支;否则就恢复 ra、s0 和 sp 并返回。如果分支被采取,首先递减 a1(b),再将 a0 恢复成 s0(a),然后开始递归调用 func。在递归调用返回后,将返回值(a0)与 s0(a)相加并跳转到标签 .L1,在这里恢复 ra、s0 和 sp 并返回函数。
这就是递归的一个经典例子,另一个经典例子是斐波那契数列,读者可以在我的笔记中找到,这里不多赘述。另一个值得注意的点是 gcc 的编译选项,读者也可以在我的笔记中找到。QAQ
6.5.4 汇编¶
汇编器将汇编代码转化成包含机器语言代码的目标文件。可以使用 gcc -c prog.s -o prog.o 来将汇编代码转化成目标文件。汇编器会对汇编代码进行两次遍历,在第一次遍历中,汇编器为指令分配地址并且找到所有的的符号,例如标签和全局变量名。这些符号的名称和地址被保存在符号表中。在第二次遍历中,汇编器生成机器语言代码,标签的地址则从符号表中获取。机器语言代码和符号表被存储在目标文件中。
反汇编是非常容易的,直接使用 objdump 就可以。objdump -S prog.o 会显示目标文件的汇编代码,这样我们就可以研究汇编语言代码与机器语言代码之间的关系。倘若当初编译的时候使用了 -g 选项,类似于 gcc -O1 -g -c prog.c -o prog.o,那么编译器会在生成的目标文件或可执行文件中包含调试信息。调试信息不仅包括源代码中的变量名和行号,还包括源代码与生成的机器码之间的映射。这样不光允许我们在调试器中将机器码与源代码对应起来,在反汇编的时候还可以直接显示与汇编代码对应的源代码行。
我们发现,call 伪指令被翻译为两条 RISC-V 指令:auipc ra, 0x0 和 jalr ra,这是为了应对函数距离当前程序计数器较远的情况,超出了 jal 的有符号 21 位偏移量的可达范围,有时候我们称之为远调用。
存储全局变量的指令也只是占位符,因为需要等待链接,直到全局变量在链接阶段被放到内存中,对应的指令才会被更新。
使用 objdump -t 可以查看目标文件的符号表,以下面的符号表为例,这是编译上节的 C 程序得到的目标文件的符号表:
我们只对几个有意义的列添加了标签:符号的内存地址、大小和名称。由于程序目前还没有链接,所以这些地址目前只是占位符,并且可以发现 .text 和 .data 的大小都是 0,因为程序还没有链接。全局变量符号 f、g、y 的地址还是 0x00000004,这还是占位符,因为他们还没有被分配地址。我们还发现有一些未标记的列,这些列显示了与符号相关的标志:l 表示局部、g 表示全局、d 表示调试、F 表示函数、O 表示对象。符号所在的段也被列出,.text 表示代码段,.data 表示数据段,*COM* 代表 common,表示尚未定位到段中的公共符号。
6.5.5 链接¶
大多数大型程序并不仅仅只包括一个文件,一旦程序员修改了其中之一,就要花时间全部重新编译一遍,这显然是浪费时间的。特别的,程序经常还会调用库文件的函数,这些库文件几乎不改变,一旦一个高层代码文件没被修改,与之关联的目标文件就不需要更新。此外,程序还包括一些启动代码,如初始化栈、堆等,这些代码必须在调用 main 函数之前执行。
链接器的作用是将所有的目标文件与启动代码合并成一个机器语言文件,称为可执行文件,并且为全局变量分配地址。链接器会重新定位目标文件中的数据和指令,以避免它们相互重叠。它使用符号表中的信息,根据新的标签和全局变量地址调整代码。可以使用 gcc prog.o -o prog 调用 GCC 来链接目标文件,也可以使用 objdump -S -t prog 来反汇编可执行文件。
前面的启动代码太长了,没法完全展示,但是更新后的符号表如下:
我们为感兴趣的列添加了标签,可以发现函数和全局变量现在被重定位到实际地址,整体文本段和数据段(包括启动代码和系统数据)分别从地址 0x10074 和 0x115e0 开始。并且 func 函数从 16 条指令减少到了 15 条,这是因为调用 func 时,它的位置距禀较近,只需要一条 jalr 指令就可以调用。同样,main 代码从 17 条指令减少到了 13 条,这是因为近距离调用和存储位于全局指针 gp 附近。程序使用一条指令将值存储到 f:sw a4, -944(gp),而不用像之前一样使用 lui 和 li。通过这条指令,我们还可以确定由启动代码初始化的全局指针 gp 的值。我们知道 f 位于地址 0x11a30,因此 gp 的值为 0x11a30 + 944 = 0x11DE0。
注意到 f、g 和 y 现在被分配到了 BSS 段,这是因为它们是未初始化的全局变量,所以它们的值在程序开始执行之前是未知的,未初始化的全局变量都放在 BSS 段。
6.5.6 加载¶
操作系统通过存储设别读取可执行文件的文本段,并将其加载到内存的文本段中,然后操作系统跳转到程序的开头开始执行,这样就可以开始执行程序了。
6.6 Odds and Ends¶
6.6.1 大端与小端¶
按本书所言,无论是大端序还是小端序,字地址都是一样的,并且同样的字地址指向相同的四个字节。在我们的内存模型中,仍然可以想象每个四字节字的左侧都是最高有效字节/MSB,右侧都是最低有效字节/LSB。这样的话,大端序和小端序的区别就在于字节的排列顺序。在大端序中,最高有效字节在最低的地址,最低有效字节在最高的地址;而在小端序中,最低有效字节在最低的地址,最高有效字节在最高的地址。所以就有下面的图片:
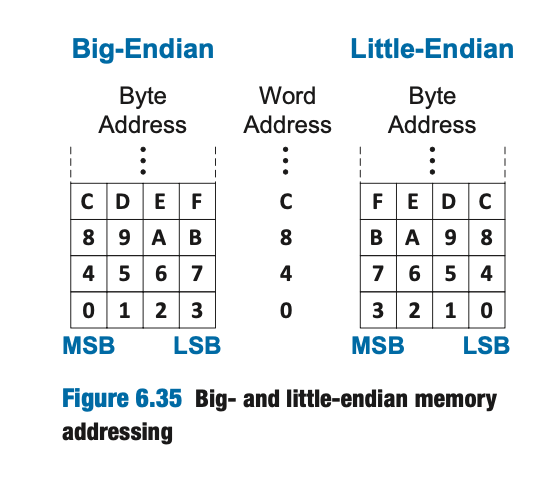
一般来说,RISC-V 使用的是小端序。尽管端序的选择是完全任意的,但是在大端序与小端序计算机之间共享数据的时候,有可能会出现一堆问题,本书的数据默认使用小端序。
6.6.2 异常¶
异常/Exception 类似于硬件或者软件事件引发的非预期函数调用。由输入输出设备(如键盘)触发的硬件异常通常称为中断/Interrupt,软件异常有时被称为陷阱/Trap。其他异常的原因包括复位和尝试读取不存在的内存。异常像其他函数调用一样,必须保存返回地址,跳转到某个地址,完成其工作,清理之后返回到之前中断的程序。
RISC-V 处理器可以在多个具有不同特权级别的模式下运行,特权级别决定了可以执行哪些指令以及可以访问哪些内存。RISC-V 的三个主要特权级别按特权从低到高排列为用户模式/User Mode、监督模式/Supervisor Mode和机器模式/Machine Mode,RISC-V 在这三个模式之外还有一个模式,称为 Hypervisor 模式,支持机器虚拟化/Machine Virtualization,但是貌似很不常用。
M Mode 是最高的特权级别,运行在这个模式下的程序可以访问所有寄存器和内存位置,同时也是唯一要求的特权模式,